python远程连接influxdb,动态通过占位符查询数据报错influxdb ERR: error parsing query: found -, expected
今天在做一个关于influxdb的数据库脚本时python报错如下:由于之前对influxdb没有什么了解,所以记录下这个过程
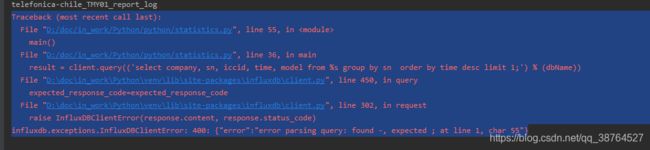
报错后我去找组内前辈问可不可以改数据表的名字,因为只有两个表名称包含“-”字符,结果却是这个已经是在运营的表了,WTF?谁教你写数据表名称用“-”连接的,不是下划线吗?太随意了,竟然就上线了,靠
然后我就去查资料,嗯?几乎没有相关的中文资料,好吧,我太菜了,呜呜呜。
话不多说,上代码:
"""
author:bruce yang
2019.12.12
读取数据库中的特定表,提取特定字段存入csv文件
"""
from influxdb import InfluxDBClient
import csv
def main():
#连接服务器,获得句柄
client = InfluxDBClient('xxx.xxx.xxx.xxxx', 8086, 'xxx', 'xxx', 'xxxx')
#获取数据库中的列表
measurements = client.get_list_measurements()
#设置标志位,方便遍历所有列表
i = 0
#新建文件,设置好表头
with open("report_log_Dates_Collection.csv", 'w') as csvFile:
writer = csv.writer(csvFile)
writer.writerow(['Company', 'Type', 'sn', 'ICCID', 'Latest Report Date'])
#循环将列表数据读取
for objectM in measurements:
#设置匹配子串
pattern = '_report_log'
#取到数据库名字
dbName = str(measurements[i]["name"])
#标志位移向下一条
i += 1
#判断数据库是否包含_report_log子串,返回bool值
flag = dbName.find(pattern) > 0
print(flag)
print(dbName)
#得到目标表,获取数据
if flag:
#获得查询结果,特别注意其中的转义字符,当数据库表中带有'-'字符时就需要转义,否则报错
result = client.query(('select company, sn, iccid, time, model from \"%s\" group by sn order by time desc limit 1;') % (dbName))
#返回生成器,生成器可以看为一个字典,可以获得相应字段的值
points = result.get_points()
for item in points:
#追加写入文件
with open("report_log_Dates_Collection.csv", 'a+') as csvFile:
writer = csv.writer(csvFile)
Company = item['company']
sn = item['sn']
time = item['time']
type = item['model']
iccid = item['iccid']
data = [Company, type, sn, iccid, time]
writer.writerow(data)
#一定要记得关闭数据库
client.close()
if __name__ == "__main__":
main() 代码挺少的,但是这是python的特点,用更少的代码实现更多的功能。需求是这样的,我需要用python访问influxdb,获取某个数据库的所有表,然后提取某些特定表的一些字段,存入csv文件,然后好做数据分析。然后我就开始了编程大法,之前没觉得会这么简单,其实只要了解influxdb的相关接口函数,这样操作起来就非常简单。加上自己之前有多vb开发经验,其实对于接口函数的理解还是到位的。influxdb的资料大多是英文文档,但是很好理解,看官方的文档会让编程更加高效。
首先我连接到远程服务器,获得了句柄,这样就可以方便访问远程的influx数据库,通过get_list_measurements()接口函数就可以取到对应数据库下所有的表。然后新建一个csv文本,提前写上相应的属性,这里要注意一点的是python 对with的使用,真的超级方便。with会对as 后面的对象自动监控,当文件使用完毕后会自动释放、关闭,不用害怕忘记close()的危险,同时with还提供了try的功能,当出现错误的时候会抛出错误。是不是很方便。
后面就是要判断measurement的名字是否是我们需要的,我们需要带有_report_log的表,所以需要使用find 函数去判断字串的问题,用in 一直都是false ,具体也不知道为什么,后面换程find函数,这点我会面在更新一篇关于python字串判断的博客。
设置一个flag 这样简明清晰,如果是我们需要的表,那么就进行sql查询,(我的sql还是非常强的,又相关方面问题可以交流。)
这里就要小心,如果用我这种占位符的方式还好,一句写完。如果使用字符串拼接的话酒宴小心在每一个字符串都以空格结尾,不然就会让两个单词连接起来,在成书写语句错误。最好还是用占位符的方式,这样看起来也比较方便,又显得NB。可以使用多个占位符哦,然后后面用%连接,最后用括号将参数传入,括号内用括号分开:“select %s from %s” % (params1,params2)这样。
这下就到最坑的时候,书写sql语句,influxdb不支持没有双引号括起来的带有“-”的查询,除非带有双引号,但是我们这里参数是动态传入的,本来就以字符串的形式,不可能在加个双引号,有人说可以字符串拼接,"""+sql+"""这样就把双引号带进去了,哈哈哈哈哈哈,我试过了,不可以!这样就会被query函数认为为一句查询语句,包括“”,会报错。
之后就是有某个人美活差的家伙把数据表名称用“-”连接起来了,服气!

这就是那个表名 ,我检查了一遍,没发现异常,后面左看右看,突然发现竟然有个”-“我一直看作”_",靠。
太坑了,然后我就去数据库里面查了一遍,没错,嗯?不对,,,要把表名的双引号去掉。果然出错了
然后查资料,没查到,问了前辈,说用转义符号。果然,NB.之前都没用过python转义,太菜了我
最后就是读取数据,然后写入文件,有连个关键点要记录一下,一个是OPEN文件的方式,a+表示追加,wb表示写,也就是覆盖,我们这里用追加,放心,每次运行都会产生新的文件,之前的数据清空。
还有一个就是influcdb 的get_points()函数,这个函数会将sql查到的resultse结果集生成为一个一个的字典形式上的生成器,然后就可以通过字典取到对应的列值,循环存入csv文件,最后记得关闭数据库连接
今天就到这里,欢迎有问题的提问,一起进步!
我对数据挖掘,人工智能、java后端都有巨大兴趣,欢迎来撩。