大数据ETL实践探索(2)---- python 与aws 交互
文章大纲
- 大数据ETL 系列文章简介
- 简介与实例
- 读写本地数据到aws s3
- upload csv to aws
- 使用python 将本地文件写入s3
- 读出kinesis 中数据
大数据ETL 系列文章简介
本系列文章主要针对ETL大数据处理这一典型场景,基于python语言使用Oracle、aws、Elastic search 、Spark 相关组件进行一些基本的数据导入导出实战,如:
- oracle使用数据泵impdp进行导入操作。
- aws使用awscli进行上传下载操作。
- 本地文件上传至aws es
- spark dataframe录入ElasticSearch
等典型数据ETL功能的探索。
系列文章:
1.大数据ETL实践探索(1)---- python 与oracle数据库导入导出
2.大数据ETL实践探索(2)---- python 与aws 交互
3.大数据ETL实践探索(3)---- pyspark 之大数据ETL利器
4.大数据ETL实践探索(4)---- 之 搜索神器elastic search
5.使用python对数据库,云平台,oracle,aws,es导入导出实战
6.aws ec2 配置ftp----使用vsftp
本文主要介绍,使用python与典型云平台aws 进行交互的部分过程和经典代码
简介与实例
boto3 有了这个包,基本所有和aws 进行交互的库都可以搞定了
aws 云服务提供了一些基础到高端的组合帮助我们更好的进行交付,实现自己的想法。 我看过最经典的例子莫过于
利用 AWS Comprehend 打造近实时文本情感分析
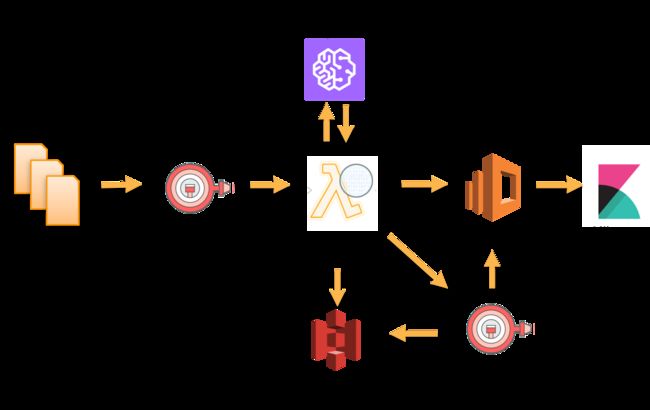
来自aws 官方技术博客的
下面我们给出一些典型例子和场景代码
读写本地数据到aws s3
upload csv to aws
使用awscli上传大文件,当然直接浏览器上传也行,但是好像超过4g会有问题。
Download Windows Installer
Https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/awscli-install-windows.html#awscli-install-windows-path
When installed, use
AWS --version
to confirm whether it is normal
Single file upload eg.
AWS S3 --region cn-north-1 CP CL_CLLI_LOG.csv s3://xxxx/csv/
You can use the notepad++'s block pattern, edit each table into a command, and execute the bat file in the CMD,like below:
aws s3 --region cn-north-1 cp LOG1.csv s3://xxxx/csv/
aws s3 --region cn-north-1 cp LOG2.csv s3://xxxx/csv/
使用python 将本地文件写入s3
def writeJsonToS3(json,aws_access_key,aws_secret_access_key):
client = boto3.client('s3', 'cn',aws_access_key_id=aws_access_key, aws_secret_access_key=aws_secret_access_key)
filename = "_".join(['result',datetime.datetime.now().strftime('%Y%m%d%H%M%S'),'score']) + '.csv'
bucket_name = '...'
route = '...'
client.put_object(Body=json,Bucket=bucket_name, Key=route + filename )
logger.info("score result Added to S3")
file_url = "https://.../{0}/{1}".format(bucket_name,filename)
logger.info(image_url)
读出kinesis 中数据
def get_stream_data(stream_name, limit, timedelta):
client = boto3.client('kinesis', 'cn', aws_access_key_id='',aws_secret_access_key='')
if stream_name:
stream = client.describe_stream(StreamName=stream_name)['StreamDescription']
for shard in stream['Shards']:
print ("### %s - %s"%(stream_name, shard['ShardId']))
shard_iterator = client.get_shard_iterator(
StreamName=stream_name,
ShardId=shard['ShardId'],
ShardIteratorType='AT_TIMESTAMP', #'TRIM_HORIZON'|'LATEST'
Timestamp=datetime.datetime.utcnow() - datetime.timedelta(minutes=timedelta)
)['ShardIterator']
for i in range(0,1):
out = client.get_records(ShardIterator=shard_iterator, Limit=limit)
if out["Records"]:
for record in out["Records"]:
data = json.loads(record["Data"])
print (data)
break
else:
print (out)
else:
print ("Need stream name !!!")