Redis内核基于时间点的备份恢复和基于AOF日志的增量同步机制设计
11月30日云栖社区在线培训,云栖社区请来了阿里云资深开发工程师夏德军为大家带来阿里云Redis内核优化的分享。本文从两大方面介绍阿里云Redis服务,一是Redis内核支持基于时间点的备份恢复,一是Redis基于AOF日志的增量同步机制设计,并分别通过假设场景,详细的分析了备份恢复流程和AOF PSYNC流程。一起来了解下吧。
直播视频回顾
Redis内核支持基于时间点的备份恢复
Redis内存数据库,须有一种机制能够把内存中的数据持久化到硬盘上,再将硬盘中数据备份到备份系统中,才能去做恢复。Redis原生的持久化机制包括RDB持久化和AOF持久化两种。
RDB持久化
RDB持久化触发方式有两种:
-
手动触发:执行 BGSAVE命令;
-
自动触发:配置 SAVE选项,在指定时间内发生指定次数的 key修改,自动进行后台 RDB SAVE。
RDB持久化流程如下:

在做RDB SAVE时需要fork一个子进程,每次RDB SAVE生成一个对应时间点的内存快照文件。
AOF持久化

-
配置 appendonly 选项,可以动态开关;
-
和 RDB 持久化不太一样的是,每一次的写操作命令都会追加到 aof 文件中,根据配置的 appendfsync 选项不同,会有不同 aof 文件刷新策略;
-
Redis 通过 AOF Rewrite 的方式来“紧凑” AOF ,解决持续追加导致 AOF 文件过大的问题。
当前备份恢复方式
现在Redis内核能够支持的备份方式有两种:
1. 备份RDB:执行BGSAVE命令 -> Fork子进程 -> 生成rdb文件 -> 备份rdb文件;
2. 备份AOF:根据aof大小判断是否需要先做一次AOF Rewrite,备份aof,AOF Rewrite同样需要Fork子进程。
两种方式都是备份一个全量数据文件,通常不会选择备份aof,rdb格式更为紧凑,备份开销更小。
恢复时,创建实例,从备份系统拉取全量的aof或rdb文件到实例数据目录,恢复数据。
当前内核备份恢复方式只能做全量数据的备份和恢复,fork子进程生成全量快照的方式开销比较大。
应用场景举例

如果能够不管几点上线,都能恢复Redis数据到那个时间点,场景中的问题将不再存在。
Redis基于时间点的备份恢复

我们的目标就是要恢复数据到任意时间点,我们做了基于AOF改造的增量日志,禁用AOF Rewrite,日志按照配置大小自动切分。除了每个命令执行的历史日志要保存下来,还需要添加一些额外的信息,比如:
- 根据系统时间戳命名AOF,AOF中除了包含原有的Redis协议格式的命令(Oplog),每个Oplog还对应了一个Header;
- Header中包含多个字段,其中timestamp记录了命令执行时的时间戳,基于任意时间点恢复时就依赖于该信息;
- server_id、opid和dbid是为后面讲的主从同步优化所设计,reserved为保留字段;
- Oplog Header以二进制的形式用Redis命令封装,保持AOF协议格式不变。
AOF日志管理

AOF会按固定大小做切分,我们需要将AOF日志进行管理,主要有以下三点:
1. 使用AOF Index索引文件记录Redis当前维护的AOF文件;
2. 使用专门的清理命令删除AOF,同时维护AOF index文件的正确性;
3. BGSAVE完成时需要记录RDB文件对应的AOF日志名和文件写入偏移,这个信息保存在rdb index文件中。
本地定时BGSAVE

我们也需要本地定时BGSAVE机制,AOF会越变越大,仍然需要某种方式来“紧凑”AOF日志,比如AOF Rewrite方式复合式进程重写AOF日志,Redis实例在本地也需要保存一份持久化的全量数据,重启时从AOF日志恢复数据是不现实的。
对此,我们引入Cron BGSAVE,当AOF日志的增长量满足一定条件时,触发BGSAVE,生成RDB文件,该RDB文件对应的时间点之前的AOF日志在本地都是不需要的,只要已经上传到备份系统,即可删除。
备份恢复流程

时间点备份恢复的流程如图所示,左侧假如有一个Redis-Server实例,追加写AOF6文件,接着实时备份AOF日志,上传到备份空间中,同时也有定时全量备份,每一个RDB文件会对应一个RDB文件写入偏移,每个AOF文件会有一个起始时间;右侧指定要恢复的时间点,Redis顺序加载RDB、AOF到指定地点。
备份和原来全量备份的区别在于,需要实时持续地把Redis生成的AOF增量日志不断的备份下来,我们也要有删除的机制,比如保存一个星期或一个月的情况。
Redis基于AOF日志的增量同步机制设计
Redis原生同步机制主要有两种,全量同步和增量同步。
全量同步

全量同步代价非常大,全量同步意味着有一个空的Redis实例挂上来后,Master需要做一次BGSAVE,还需要网络传输RDB文件,发送给slave,大量占用主库带宽、cpu资源,大内存时fork会导致redis hang住,虽然fork是写实复制,但需要copy页表,如果内存比较大,页表也会比较大。
增量同步
Redis在2.8中引入了增量同步机制,是为了解决网络偶尔的抖动导致需要全量同步的问题。
增量同步机制实现比较简单,master和slave之间维护一个一致的同步offset,此外,master还在内存里面维护了一个同步buffer,保存了最近一段时间内的更新命令日志,当slave断链重连时,会根据自己的同步偏移从master的同步buffer直接拉取数据,完成同步。
理想情况下,这个流程同步很快,代价很低,但是当网络断开时间较长时,或主库写入非常大时,同步Buffer会将历史数据覆盖掉,仍然需要全量同步。而且,现有的增量同步机制,也没有解决一主多从场景下,主从切换,其他从需要从新主全量同步的问题。
应用场景举例
有不少使用Redis的业务的重要性很高,譬如说金融业务,都有跨机房,甚至跨地域灾备的需求,而跨机房或跨地域的网络质量往往很难保证。
假设有一天,Redis业务的杭州主机房和深圳的备机房之间的光纤被人挖断了,网络中断数小时,恢复后,深圳机房所有的备实例同时发起全量同步,导致的后果很可能是:主库所在机器带宽、cpu打满,甚至有些机器会直接OOM,而备又还没有完成同步,后果可能是灾难性的,对此,我们该如何处理呢?
基于AOF日志的增量同步(AOF PSYNC)
由于现有机制存在的问题,以及真实场景中业务需求的推动,我们想到不依赖于具体内存的Buffer,用增量日志做增量同步,那么,基于AOF日志的增量同步是怎么实现的呢?具体原理解释如下:
- 当主从同步断开,需要拉取增量时,会先选择尝试基于同步偏移从主库同步buffer获取数据,如果同步buffer缺少增量数据,会开始从AOF日志获取增量;
- AOF PSYNC以AOF日志中的opid作为同步基准,slave继承从主库同步过来的opid,并记录在自己的AOF日志中;
- 使用opid作为同步基准是因为对于带过期时间的命令,Redis写AOF和写同步buffer的字节序列不一样,Redis在写AOF时会转换设置过期时间的命令为PEXPIREAT;
- AOF日志中的dbid,决定了AOF中的每条命令写入的db是哪个。AOF PSYNC同步完成后,会同步master和slave间的同步偏移。
AOF PSYNC流程
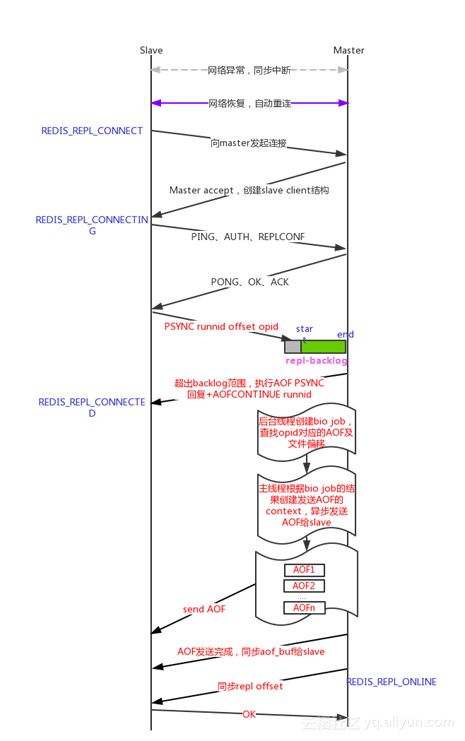
1. Master收到Slave的AOF PSYNC请求后,会使用后台线程来查找offset,避免server hang住;
2. 根据slave发送的opid查找到起始的AOF文件后会异步的通知主线程;
3. 主线程会异步发送一个或多个AOF文件给SLAVE,发送完成后,需要同步aof buffer;
4. 如果slave给定的opid在master的AOF中不存在(AOF可能被异常删除),会发起全量同步。
阿里云Redis服务

与其它Redis对比,阿里云Redis服务具备高可靠、高性能、高扩展、易用的特点。