python爬虫爬取京东商品信息
python爬虫爬取京东商品信息
话不多说,直接上代码!
import requests
from bs4 import BeautifulSoup
import xlwt
class Excel:
# 当前行数
_current_row = 1
# 初始化,创建文件及写入title
def __init__(self, sheet_name='sheet1'):
# 表头,放到数组中
title_label = ['商品编号', '商品名称', '图片路径', '价格', '商家', '商品详情地址']
self.write_work = xlwt.Workbook(encoding='ascii')
self.write_sheet = self.write_work.add_sheet(sheet_name)
for item in range(len(title_label)):
self.write_sheet.write(0, item, label=title_label[item])
# 写入内容
def write_content(self, content):
for item in range(len(content)):
self.write_sheet.write(self._current_row, item, label=content[item])
# 插入完一条记录后,换行
self._current_row += 1
# 保存文件(这里的'./dj_data.xls'是默认路径,如果调用此函数,没有传file_url参数,则使用'./dj_data.xls')
def save_file(self, file_url='./dj_data.xls'):
try:
self.write_work.save(file_url)
print("文件保存成功!文件路径为:" + file_url)
except IOError:
print("文件保存失败!")
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 创建文件
excel = Excel()
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置解析器
soup = BeautifulSoup(html, 'lxml')
# 商品列表
goods_list = soup.find_all('li', class_='gl-item')
# 打印goods_list到控制台
for li in goods_list: # 遍历父节点
# 商品编号
no = li['data-sku']
# 商品名称
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
# 图片路径
img_url = li.find(class_='p-img').find('img')['src']
# 价格
price = li.find(class_='p-price').find('i').get_text()
# 商家
shop = li.find(class_='p-shop').find('a').get_text()
# 商品详情地址
detail_addr = li.find(class_='p-name p-name-type-2').find('a')['href']
# 将商品信息放入数组中,再传到写入文件函数
goods = [no, name, img_url, price, shop, detail_addr]
# 写入文档
excel.write_content(goods)
# 保存文件,使用的是相对目录(也可以使用绝对路径),会保存在当前文件的同目录下。文件名为dj_data.xls,必须是.xls后缀
excel.write_work.save("C:/Users/86135/Desktop/dj_data.xls")
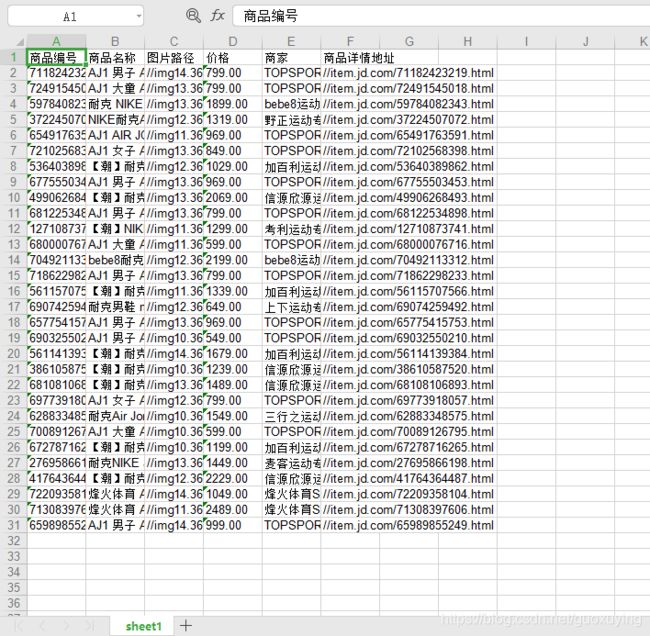
运行结果: