最长回文子串求解
转载自LeetCode,作者liweiwei1419
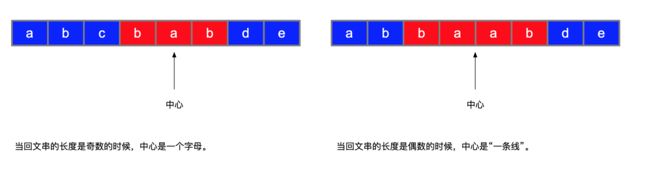
回文串可分为奇数回文串和偶数回文串。它们的区别是:奇数回文串关于它的“中点”满足“中心对称”,偶数回文串关于它“中间的两个点”满足“中心对称”。
方法一:暴力匹配 (Brute Force)
不推荐
方法二:中心扩散法
中心扩散法的想法很简单:遍历每一个索引,以这个索引为中心,利用“回文串”中心对称的特点,往两边扩散,看最多能扩散多远。要注意一个细节:回文串的长度可能是奇数,也可能是偶数。
可以设计一个方法,兼容以上两种情况:
1、如果传入重合的索引编码,进行中心扩散,此时得到的最长回文子串的长度是奇数;
2、如果传入相邻的索引编码,进行中心扩散,此时得到的最长回文子串的长度是偶数。
public class Solution {
public String longestPalindrome(String s) {
int len = s.length();
if (len == 0) {
return "";
}
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
for (int i = 0; i < len; i++) {
String palindromeOdd = centerSpread(s, len, i, i);
String palindromeEven = centerSpread(s, len, i, i + 1);
String maxLen = palindromeOdd.length() > palindromeEven.length() ? palindromeOdd : palindromeEven;
if (maxLen.length() > longestPalindrome) {
longestPalindrome = maxLen.length();
longestPalindromeStr = maxLen;
}
}
return longestPalindromeStr;
}
private String centerSpread(String s, int len, int left, int right) {
int l = left;
int r = right;
while (l >= 0 && r < len && s.charAt(l) == s.charAt(r)) {
l--;
r++;
}
// 这里要特别小心,跳出 while 循环的时候,是第 1 个满足 s.charAt(l) != s.charAt(r) 的时候
// 所以,不能取 l,不能取 r
return s.substring(l + 1, r);
}
}复杂度分析:
- 时间复杂度:O(N*N)。
- 空间复杂度:O(1)。
方法三:动态规划
解决这类 “最优子结构” 问题,可以考虑使用 “动态规划”:
1、定义 “状态”;
2、找到 “状态转移方程”。
记号说明: 下文中,使用记号 s[l, r] 表示原始字符串的一个子串,l、r 分别是区间的左右边界的索引值,使用左闭、右闭区间表示左右边界可以取到。举个例子,当 s = 'babad' 时,s[0, 1] = 'ba' ,s[2, 4] = 'bad'。
1、定义 “状态”,这里 “状态”数组是二维数组。
dp[l][r] 表示子串 s[l, r](包括区间左右端点)是否构成回文串,是一个二维布尔型数组。即如果子串 s[l, r] 是回文串,那么 dp[l][r] = true。
2、找到 “状态转移方程”。
首先,我们很清楚一个事实:
1、当子串只包含 1 个字符,它一定是回文子串;
2、当子串包含 2 个以上字符的时候:如果 s[l, r] 是一个回文串,例如 “abccba”,那么这个回文串两边各往里面收缩一个字符(如果可以的话)的子串 s[l + 1, r - 1] 也一定是回文串,即:如果 dp[l][r] == true 成立,一定有 dp[l + 1][r - 1] = true 成立。根据这一点,我们可以知道,给出一个子串 s[l, r] ,如果 s[l] != s[r],那么这个子串就一定不是回文串。如果 s[l] == s[r] 成立,就接着判断 s[l + 1] 与 s[r - 1],这很像中心扩散法的逆方法。
事实上,当 s[l] == s[r] 成立的时候,dp[l][r] 的值由 dp[l + 1][r - l] 决定,这一点也不难思考:当左右边界字符串相等的时候,整个字符串是否是回文就完全由“原字符串去掉左右边界”的子串是否回文决定。但是这里还需要再多考虑一点点:“原字符串去掉左右边界”的子串的边界情况。
1、当原字符串的元素个数为 3 个的时候,如果左右边界相等,那么去掉它们以后,只剩下 1 个字符,它一定是回文串,故原字符串也一定是回文串;
2、当原字符串的元素个数为 2 个的时候,如果左右边界相等,那么去掉它们以后,只剩下 0 个字符,显然原字符串也一定是回文串。把上面两点归纳一下,只要 s[l + 1, r - 1] 至少包含两个元素,就有必要继续做判断,否则直接根据左右边界是否相等就能得到原字符串的回文性。而“s[l + 1, r - 1] 至少包含两个元素”等价于 l + 1 < r - 1,整理得 l - r < -2,或者 r - l > 2。
综上,如果一个字符串的左右边界相等,以下二者之一成立即可:
1、去掉左右边界以后的字符串不构成区间,即“ s[l + 1, r - 1] 至少包含两个元素”的反面,即 l - r >= -2,或者 r - l <= 2;
2、去掉左右边界以后的字符串是回文串,具体说,它的回文性决定了原字符串的回文性。
于是整理成“状态转移方程”:
dp[l, r] = (s[l] == s[r] and (l - r >= -2 or dp[l + 1, r - 1]))或
dp[l, r] = (s[l] == s[r] and (r - l <= 2 or dp[l + 1, r - 1]))编码实现细节:因为要构成子串 l 一定小于等于 r ,我们只关心 “状态”数组“上三角”的那部分取值。理解上面的“状态转移方程”中的 (r - l <= 2 or dp[l + 1, r - 1]) 这部分是关键,因为 or 是短路运算,因此,如果收缩以后不构成区间,那么就没有必要看继续 dp[l + 1, r - 1] 的取值。
public class Solution {
public String longestPalindrome(String s) {
int len = s.length();
if (len <= 1) {
return s;
}
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
boolean[][] dp = new boolean[len][len];
// abcdedcba
// l r
// 如果 dp[l, r] = true 那么 dp[l + 1, r - 1] 也一定为 true
// 关键在这里:[l + 1, r - 1] 一定至少有 2 个元素才有判断的必要
// 因为如果 [l + 1, r - 1] 只有一个元素,不用判断,一定是回文串
// 如果 [l + 1, r - 1] 表示的区间为空,不用判断,也一定是回文串
// [l + 1, r - 1] 一定至少有 2 个元素 等价于 l + 1 < r - 1,即 r - l > 2
// 写代码的时候这样写:如果 [l + 1, r - 1] 的元素小于等于 1 个,即 r - l <= 2 ,就不用做判断了
// 因为只有 1 个字符的情况在最开始做了判断
// 左边界一定要比右边界小,因此右边界从 1 开始
for (int r = 1; r < len; r++) {
for (int l = 0; l < r; l++) {
// 区间应该慢慢放大
// 状态转移方程:如果头尾字符相等并且中间也是回文
// 在头尾字符相等的前提下,如果收缩以后不构成区间(最多只有 1 个元素),直接返回 True 即可
// 否则要继续看收缩以后的区间的回文性
// 重点理解 or 的短路性质在这里的作用
if (s.charAt(l) == s.charAt(r) && (r - l <= 2 || dp[l + 1][r - 1])) {
dp[l][r] = true;
if (r - l + 1 > longestPalindrome) {
longestPalindrome = r - l + 1;
longestPalindromeStr = s.substring(l, r + 1);
}
}
}
}
return longestPalindromeStr;
}
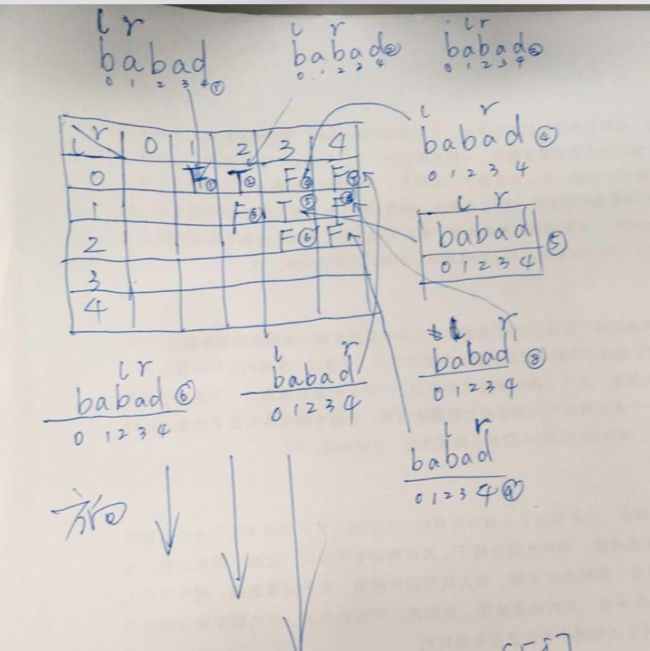
}写完代码以后,请读者在纸上写下代码运行的流程,以字符串 'babad' 为例:
 复杂度分析:
复杂度分析:
- 时间复杂度:O(N2)
- 空间复杂度:O(N2)
方法四:Manacher 算法(马拉车)
维基百科中对于 Manacher 算法是这样描述的:
[Manacher(1975)] 发现了一种线性时间算法,可以在列出给定字符串中从字符串头部开始的所有回文。并且,Apostolico, Breslauer & Galil (1995) 发现,同样的算法也可以在任意位置查找全部最大回文子串,并且时间复杂度是线性的。因此,他们提供了一种时间复杂度为线性的最长回文子串解法。替代性的线性时间解决 Jeuring (1994), Gusfield (1997)提供的,基于后缀树(suffix trees)。也存在已知的高效并行算法。Manacher 算法,被中国程序员戏称为“马拉车”算法。专门用于解决“最长回文子串”问题,时间复杂度为 O(n),事实上,“马拉车”算法在思想上和“KMP”字符串匹配算法有相似之处,都避免做了很多重复的工作。“KMP”算法也有一个很有意思的戏称,带有一点颜色。
挺有意思的一件事情是:我在学习“树状数组”和“Manacher 算法”的时候,都看了很多资料,但最后代码实现的时候,就只有短短十几行。
理解 Manacher 算法最好的办法,是根据查阅的关于 Manacher 算法的文章,自己在稿纸上写写画画,举一些具体的例子,这样 Manacher 算法就不难搞懂了。
Manacher 算法本质上还是中心扩散法,只不过它使用了类似 KMP 算法的技巧,充分挖掘了已经进行回文判定的子串的特点,提高算法的效率。
下面介绍 Manacher 算法的运行流程。
首先还是“中心扩散法”的思想:回文串可分为奇数回文串和偶数回文串,它们的区别是:奇数回文串关于它的“中点”满足“中心对称”,偶数回文串关于它“中间的两个点”满足“中心对称”。为了避免对于回文串字符个数为奇数还是偶数的套路。首先对原始字符串进行预处理,方法也很简单:添加分隔符。
第 1 步:对原始字符串进行预处理(添加分隔符)
我们先给出具体的例子,看看如何添加分隔符。
例1:给字符串 "level" 添加分隔符 "#"。
答:字符串 "level" 添加分隔符 "#" 以后得到:"#l#e#v#e#l#"。
例2:给字符串 "noon" 添加分隔符 "#"。
答:字符串 "noon" 添加分隔符 "#" 以后得到:"#n#o#o#n#"。
我想你已经看出来分隔符是如何添加的,下面是两点说明。
1、分隔符是一定是原始字符串中没有出现过的字符,这个分隔符的种类也只能有一个,即你不能同时添加 "#" 和 "?" 作为分隔符;
2、添加分隔符的方法是在字符串的首位置、尾位置和每个字符的“中间”都添加 1个这个分隔符。可以很容易知道,如果这个字符串的长度是 len,那么添加的分隔符的个数就是 len + 1,得到的新的字符串的长度就是 2 * len + 1,显然它一定是奇数。
为什么要添加分隔符?
1、首先是正确性:添加了分隔符以后的字符串的回文性质与原始字符串是一样的(这句话不是很严谨,大家意会即可);
2、其次是避免回文串长度奇偶性的讨论(马上我们就会看到这一点是如何体现的)。
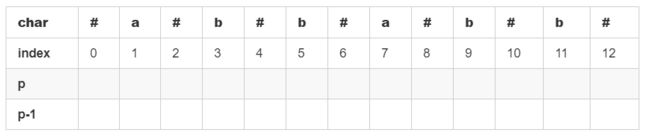
第 2 步:得到 p 数组
p 数组可以通过填表得到。以字符串 "abbabb" 为例,说明如何手动计算得到 p 数组。假设我们要填的就是下面这张表。
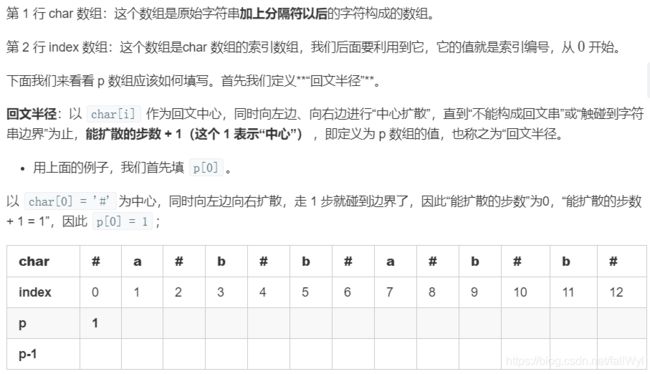
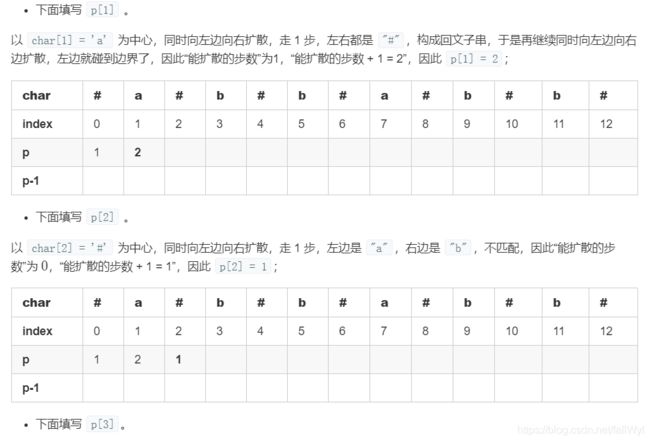

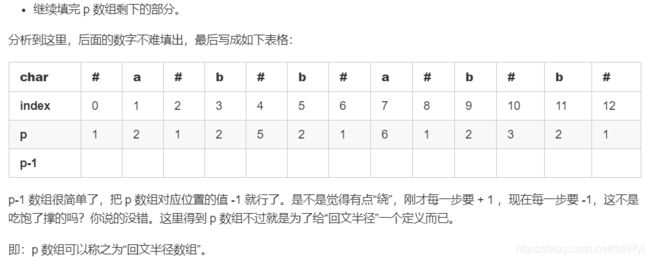
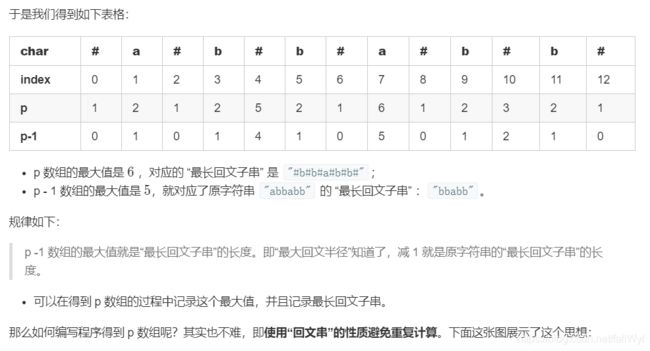
上面这张图画得仔细一点是下面这张图:
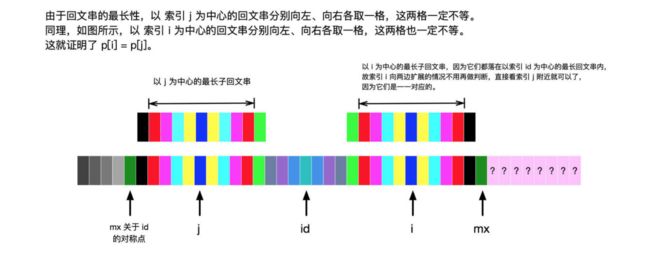
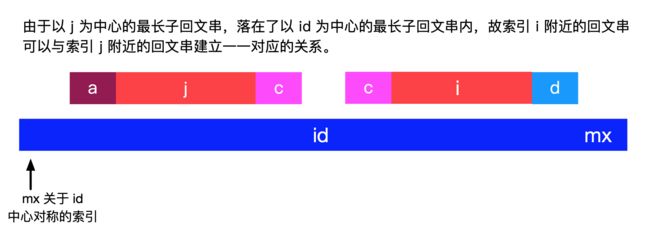
这里 i 和 j 关于 id 中心对称:即 j = 2 * id - i。上面的两张图表示的意思是:p[i] 的值可以根据 p[j] 得到。因为我们遍历一个字符串的方向是“从左到右”,故数组 p 后面的值根据前面的值得来,这个思路没有问题。
接下来要介绍 id 和 mx 的含义了:
1、id :从开始到现在使用“中心扩散法”能得到的“最长回文子串”的中心的位置;
2、mx:从开始到现在使用“中心扩散法”能得到的“最长回文子串”能延伸到的最右端的位置。容易知道 mx = id + p[id]。
先从最简单的情况开始:
1、当 id < i < mx 的时候,此时 id 之前的 p 值都已经计算出来了,我们利用已经计算出来的 p 值来计算当前位置的 p 值。
由于以 j 为中心的最长子回文串,落在了以 id 为中心的最长子回文串内,由于 i 和 j 对称, 故索引 i 附近的回文串可以与索引 j 附近的回文串建立一一对应的关系。
如果 j 的回文串很短,在 mx 关于 id 的对称点之前结束,一定有 dp[i]=dp[j],如上图所示;
如果 j 的回文串很长,此时 dp[i] 的值不会超过 i 与 mx 之间的距离: mx - i,此时想一下 mx 是 以 id 为中心的最长回文子串的“最右边界”,就不难理解了,如下图所示 。
如果 p[j] 很大的话,即当 p[j] >= mx - i 的时候,以 s[j] 为中心的回文子串不一定完全包含于以 s[id] 为中心的回文子串中,但是基于对称性可知,以 s[i] 为中心的回文子串,其向右至少会扩张到 mx 的位置,也就是说 p[i] >= mx - i。至于 mx 之后的部分是否对称,就只能老老实实去匹配了。


public class Solution {
/**
* 创建分隔符分割的字符串
*
* @param s 原始字符串
* @param divide 分隔字符
* @return 使用分隔字符处理以后得到的字符串
*/
private String generateSDivided(String s, char divide) {
int len = s.length();
if (len == 0) {
return "";
}
if (s.indexOf(divide) != -1) {
throw new IllegalArgumentException("参数错误,您传递的分割字符,在输入字符串中存在!");
}
StringBuilder sBuilder = new StringBuilder();
sBuilder.append(divide);
for (int i = 0; i < len; i++) {
sBuilder.append(s.charAt(i));
sBuilder.append(divide);
}
return sBuilder.toString();
}
public String longestPalindrome(String s) {
int len = s.length();
if (len == 0) {
return "";
}
String sDivided = generateSDivided(s, '#');
int slen = sDivided.length();
int[] p = new int[slen];
int mx = 0;
// id 是由 mx 决定的,所以不用初始化,只要声明就可以了
int id = 0;
int longestPalindrome = 1;
String longestPalindromeStr = s.substring(0, 1);
for (int i = 0; i < slen; i++) {
if (i < mx) {
// 这一步是 Manacher 算法的关键所在,一定要结合图形来理解
// 这一行代码是关键,可以把两种分类讨论的情况合并
p[i] = Integer.min(p[2 * id - i], mx - i);
} else {
// 走到这里,只可能是因为 i = mx
if (i > mx) {
throw new IllegalArgumentException("程序出错!");
}
p[i] = 1;
}
// 老老实实去匹配,看新的字符
while (i - p[i] >= 0 && i + p[i] < slen && sDivided.charAt(i - p[i]) == sDivided.charAt(i + p[i])) {
p[i]++;
}
// 我们想象 mx 的定义,它是遍历过的 i 的 i + p[i] 的最大者
// 写到这里,我们发现,如果 mx 的值越大,
// 进入上面 i < mx 的判断的可能性就越大,这样就可以重复利用之前判断过的回文信息了
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
if (p[i] - 1 > longestPalindrome) {
longestPalindrome = p[i] - 1;
longestPalindromeStr = sDivided.substring(i - p[i] + 1, i + p[i]).replace("#", "");
}
}
return longestPalindromeStr;
}
}
复杂度分析:
时间复杂度:O(N),由于 Manacher 算法只有在遇到还未匹配的位置时才进行匹配,已经匹配过的位置不再匹配,所以对于对于字符串S 的每一个位置,都只进行一次匹配,所以算法的总体复杂度为 O(N)。
空间复杂度:O(N)。