Incomplete Multi-View Weak-Label Learning论文笔记
Incomplete Multi-View Weak-Label Learning(IJCAI2018)
Qiaoyu Tan; Guoxian Yu.
College of Computer and Information Science, Southwest University
论文链接:https://www.ijcai.org/Proceedings/2018/0375.pdf
1 论文主要贡献
提出了一种解决 Incomplete Multi-View Weak-Label (iMVWL)的方法,Weak-Label 即标 签部分缺失,iMVWL 从不完整的视图中同时通过弱标签,局部标签相关性和该子空间中的 预测变量来学习共享子空间。不仅可以捕获交叉视图关系,还可以捕获训练样本的弱标签信息。
2 论文主要内容
2.1 Introduction
现有的一些多视图多标签学习方法很少考虑视图缺失或者标签缺失的情况,一种更具有 挑战的情况是:incomplete views 和 weak labels 同时存在,很少有研究在多视图学习中处理不完整的数据 [Xu 等,2015a] 或缺少标签 [Zhang 等,2013],但是之前的工作没有同时考虑到这两个问题。
本文提出了一个 iMVWL 统一模型,以联合处理不完整的视图和缺失标签问题。 iMVWL 的基本策略是在统一的学习框架中通过不完整视图学习共享的子空间,并在该子空 间中学习弱标签分类器。
• iMVWL 可以共同解决视图不完整和标签缺失的问题。它从弱标签,标签相关性以 及该子空间中的预测变量的不完整视图中学习共享子空间;
• 本文开发了一种解决方案来迭代优化模型,避免出现次优问题。
2.2 Related Work
A. Weak-label learning
现有的一些 Weak-label learning 方法大致上可以分为三类:under a supervised setting; under a semi-supervised setting; under a multi-instance multi-label framework.
B. Multi-view learning
Multi-view learning 方法常常与半监督学习,多标签学习,或自主学习结合起来;其他的方法基于:所有视图源自一个统一子空间,以及不同视图下的同一样本映射到统一子空间 应该是相近的假设,学习统一子空间,也就是 subspace learning 方法。
C. Multi-view Weak-label learning
大部分 Weak-label learning 方法基于 a single view;以及大部分 Multi-view learning 方法 基于 complete views. LabelMe 和 MVL-IV 这两种方法是例外,LabelMe 是一种 Multi-view Weak-label learning 方法,但是 LabelMe 的每个训练样本都具有完整的视图;MVL-IV 考虑 了 incomplete views,但是它是用无监督的方式学习统一子空间,然后在学习到的子空间上训练标签分类器,这就导致了次优问题。另外 MVL-IV 的训练样本都具有完全的标签,忽略了现实中存在大量的标签缺失情况。
2.3 iMVWL
本文的这块内容逻辑很清晰,我下面一步一步的推导出 iMVWL 的目标函数。
现有的一些共享子空间学习方法利用低秩约束,矩阵分解或者 NMF,其中 NMF 取得了很大的成功,因为大多数的数据矩阵自然是非负的,或者可以很容易地转换为非负的矩阵。NMF 与其他矩阵分解方法(例如 SVD(奇异值分解))之间的主要区别在于非负约束,这有助于获得基于局部的表示形式并增强学习的子空间的可解释性。所以本文选用NMF 学习低秩的共享子空间。
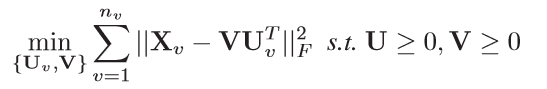
Eq (1)时NMF的目标函数,其中 X v ∈ R n × d v X_v\in\R^{n×d_v} Xv∈Rn×dv 为第 v v v个视图的数据矩阵, n n n是样本总数, d v d_v dv是第 v v v 个视图的特征维度; V ∈ R n × k ≥ 0 V\in\R^{n×k}\ge 0 V∈Rn×k≥0 为共享子空间(样本重构表达); U v ∈ R k × d v ≥ 0 U_v\in\R^{k×d_v}\ge 0 Uv∈Rk×dv≥0 为分解系数矩阵; n v n_v nv是所有视图数。然而 Eq(1)不能满足 incomplete views 的情况;如果对缺失的视图用 特征平均值来补充,会提高错误率,另外由于 V V V 通过无监督的方式学习得到,缺少具有判别力的信息。由此产生 Eq(2):

Eq(2)中, O v ∈ R n × d v O^v\in\R^{n×d_v} Ov∈Rn×dv 为第 v v v 个视图的数据指示矩阵,即用来表示 ( i , j ) (i, j) (i,j)在 X v X_v Xv中是否可用,可用为 1 1 1,缺失为 0 0 0; Y ∈ R n × c Y\in\R^{n×c} Y∈Rn×c是 n n n 个样本的可用标签矩阵; W ∈ R k × c W\in\R^{k×c} W∈Rk×c是一个系数矩阵, W W W将共享子空间 V V V 和语义空间联系起来,我对 W W W 理解就是 2.1 Introduction 中提到的子空间的预测变量。Eq(2)实现了两个目标:1) 通过捕获交叉视图的关系学习共享子空间;2) 借助标签矩阵学习 V V V,使 V V V 更具有判别力。另外 Eq(2)可以缓解输入异构特征空间和语义标签空间之间的语义鸿沟。考虑到 weak-label 和标签之间的相关性产生 Eq(3):

Eq(3)中, M ∈ R n × c M\in\R^{n×c} M∈Rn×c为标签指示矩阵,即用来表示 ( i , j ) (i, j) (i,j)在 Y Y Y中是否缺失,可用为 1 1 1,缺失为 0 0 0; S ∈ R c × c S\in\R^{c×c} S∈Rc×c表示标签相关性矩阵,引入 S S S 使得学习到的标签分类器更加鲁棒。由于 weak-label 情况,不能直接从 Y Y Y 中得到 S S S,另外考虑到标签相关性自然是局部的这一事 实,表现为标签之间直接的或者间接的依赖性。所以对 S S S 施加低秩约束,考虑到优化问题,用矩阵核范数逼近矩阵的秩,产生 Eq(4):
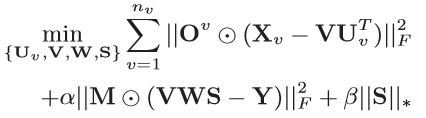
Eq(4)为 iMVWL 目标函数,Eq(4)考虑了交叉视图关系和局部(低秩)标签结构。另外,它吸收标签信息以诱导共享子空间并增强其区分能力。iMVWL 的另一个优点是,它可以从不完整的视图中联合学习一个共享子空间,该不完整视图具有弱标签,局部标签结构和该子空间中的预测变量。这种统一的模型增强了它们的相互影响,从而进一步提高了性能。
Optimization Strategy: 由于无法得到闭式解,所以利用交替优化策略。固定其他变量,求偏导置 0 0 0 得到 U v , V , W U_v,V,W Uv,V,W的迭代公式。采用之前一篇论文中的算法对 S S S优化,[Xu et al., 2013] Miao Xu, Rong Jin, and Zhihua Zhou. Speedup matrix completion with side information: Application to multi-label learning. In NIPS, pages 2301–2309, 2013.
2.4 实验设置
Data Sets
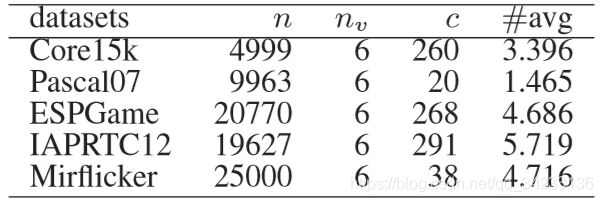
70 % 70\% 70%作为训练集, 30 % 30\% 30%作为测试集;incomplete views 设置:从每个视图中随机删除 ε % \varepsilon\% ε%个样本,同时确保每个样本都至少出现在一个视图中;weak-label 设置:对于每个标签 c ′ c' c′, 在全部样本中移除 ω % \omega\% ω%个 c ′ c' c′.
Baseline
LabelMe and lrMMC 不能处理 incomplete views,用特征平均值补充缺失视图;
MVL-IV and iMSF 不能处理 missing labels,将缺失标签视为 negative labels;
iMVWL-Sp: iMVWL 引出的一种变式,iMVWL-Sp 在子空间学习过程中不考虑标签信 息;
iMVWL-X: iMVWL 引出的一种变式,iMVWL-X 将多视图特征连接成一个向量;
iMVWL-Nc: iMVWL 引出的一种变式,iMVWL-Nc 不考虑标签相关性
Evaluation
Ranking Loss (RL ↓ ↓ ↓), Average Precision (AP ↑ ↑ ↑), Hamming Loss (HL ↓ ↓ ↓), and adapted AUC( ↑ ↑ ↑).