B题原文
“拍照赚钱”是移动互联网下的一种自助式服务模式。用户下载APP,注册成为APP的会员,然后从APP上领取需要拍照的任务(比如上超市去检查某种商品的上架情况),赚取APP对任务所标定的酬金。这种基于移动互联网的自助式劳务众包平台,为企业提供各种商业检查和信息搜集,相比传统的市场调查方式可以大大节省调查成本,而且有效地保证了调查数据真实性,缩短了调查的周期。因此APP成为该平台运行的核心,而APP中的任务定价又是其核心要素。如果定价不合理,有的任务就会无人问津,而导致商品检查的失败。
附件一是一个已结束项目的任务数据,包含了每个任务的位置、定价和完成情况(“1”表示完成,“0”表示未完成);附件二是会员信息数据,包含了会员的位置、信誉值、参考其信誉给出的任务开始预订时间和预订限额,原则上会员信誉越高,越优先开始挑选任务,其配额也就越大(任务分配时实际上是根据预订限额所占比例进行配发);附件三是一个新的检查项目任务数据,只有任务的位置信息。请完成下面的问题:
**1. 研究附件一中项目的任务定价规律,分析任务未完成的原因。
- 为附件一中的项目设计新的任务定价方案,并和原方案进行比较。
- 实际情况下,多个任务可能因为位置比较集中,导致用户会争相选择,一种考虑是将这些任务联合在一起打包发布。在这种考虑下,如何修改前面的定价模型,对最终的任务完成情况又有什么影响?
- 对附件三中的新项目给出你的任务定价方案,并评价该方案的实施效果。**
附件一:已结束项目任务数据
附件二:会员信息数据
附件三:新项目任务数据
解题思路
问题一,研究附件一中项目的任务定价规律,分析任务未完成的原因。
第一问就是签到题,没什么难度,当然也做不了很出彩。
整个附件一只有经纬度、标价、完成情况四条信息,其中定价规律和是否完成没有关系.
本题主要考查分析问题是否全面。
附件一内容:
有经纬度肯定要标到地图上看
可以看到不同城市任务的完成度是相差很大的,东莞几乎全部完成深圳大概完成了20%,广州和佛山大概完成了一半。
看到这里后半问也应该有思路了,既然不同城市完成度差别这么大,那么未完成的原因一定包括没有考虑到城市的状况,或者是人均GDP,或者是道路交通状况,或者是人口密度等,这个没有固定的答案,需要你自己找数据,最好从政府机构的网站上获得,标明来源日期,做些分析得出自己的结论。
再看任务的定价规律
颜色越深价格越低,很容易的发现任务越密集价格越低,这个也很容易理解,因为任务密集意味着跑一趟可以接很多任务,而偏远郊区想要让会员去接任务就没那么容易了.
那么除了任务密集度定价还和什么有关呢?既然任务是要人去做的,那么应该还和周围会员的数量有关系,如果周围会员多,离会员的最短距离很近,那么哪怕定价低些也应该有人接才对。
再看看附件二给了会员的哪些信息
很好,既然有位置信息就可以判定我们前面到猜测,画出会员的分布地图。
点的大小和颜色深度代表会员的信誉值,可以看到东莞市有一个虽然会员数量少但是质量很高,还有一个大佬,或许这和东莞的任务完成度很高有关系。
从图里可以看出任务密集的地方会员的分布同样也很密集(画到一个图上就很乱了,这里自己能看出来就行,具体分析还是要编程提取数据的),可以判定上面的猜测八成是正确的。
我们不能直接由图可知,需要编程计算出需要的数据:
- 任务周围任务数量
- 任务周围会员数量
- 任务离最近会员的距离
- 或许还可以考虑会员的信誉值
但实际情况并不都像数学应用题那样直观,周围是多远?信誉值该怎么附加到定价上?
实际上这些都没有明确的对错,只有好坏,你可以给出些调查数据,说明人们可以接受的步行最长距离是多少。
我的方法是从0.1km到100km遍历,可以想到当距离很小时任务周围的任务和会员都很少,体现不出差异。同样,距离很大时也是如此,那么中间应该有个距离会使不同任务的差异最大,那么半径就取这个距离。
得到数据后还需要做相关性检验来说明它和任务定价是否有关系。
最后把有关系的因素放到一块,做拟合得到相关系数,最终得到一个公式给出任务的定价规律。
易错点
有人看到灰度图后发现市中心地区任务的定价低,距离市中心越远任务的定价越高,而且做分析后定价和市中心的距离确实是相关的,结果给出了定价和离市中心的距离有关。
实际上这是不对的,之所以看起来和市中心距离有关是因为任务的性质
决定了市中心任务多,而大量的相似任务可以定价低些。
假设你是任务发布者,你会因为任务在市中心就定价低吗?当然是因为周围任务多、会员多才定价低,而市中心恰好人多,任务多罢了。
我知道有一组在第一问把任务的执行情况也考虑进去了,最后得出任务是否完成和定价没有相关性,所以他后面三问都不用做了(都没关系了还怎么给定价方案?)
问题二,改进附件一的定价方案并和原方案比较
设计新的定价方案
问题一的后半问分析任务未完成的原因,就是改进的地方,比如城市间任务完成度差异大,说明是没有考虑到不同城市的区别,那么加上城市的影响,就是改进点。或者你在第一问中发现任务的定价和周围会员的数量没有关系(那你肯定做错了),那么这也是一个改进点。
和原方案比较
比较方法也很容易,计算新的定价方案得到的结果使得未完成任务的定价有所升高,已完成任务的定价没有升高或者稍稍降低。
通过上面两个数值就可以很好的评价新的定价方案。
但是未完成的任务定价升高多少合适呢?
这是可以算是一个出彩的地方,因为很多人可能都没有想到。
如果原来定价60没有完成,现在定价100,那肯定也不是一个好的模型。因为附件一中所有任务最高定价85,最低65,所以新的定价也不能偏离很多,这里可以做些分析。
问题三,将任务打包后对最终的完成情况有什么影响
这一问是B题最重要的一问。看问题就知道了。
别的问题只有一行,它有三行肯定很重要!
好吧,其实是因为别的问题没有什么发挥的地方,你能想到的别人也能想到,就算想不到去群里水水,贴吧逛逛,总归也不会差太多,但这题差距就出来了。
打包就是个很有创新点的地方,打包肯定是距离的打包到一块,但是具体的算法就很有文章了。
百度下可以找到很多聚类算法,用的最广的k-means聚类、层次聚类还有用到神经网络的SOM聚类什么的。但实际上没有一种算法是普适于所有情况的,每种算法得到的结果也不尽相同,正是因为如此才有创新点。
上面几乎所有的聚类算法都是算点之间平均距离最小,这适用于我们把人分成三组放三个音响让尽可能多的人听到,但不适用于分成三组和每组的人挨个握手,比如下面的情况:
虽然我们用看的可以很容易把上面的点分成三类,但普通的聚类算法可能会得到类似下面的结果
考虑到问题的实际情况,分类后我们要挨个走过每个任务点。
假设我们从A点出发去离自己最近的任务,下次应该还是去离自己最近的未完成的任务点,而上图的聚类算法认为你要先回到A点再去完成任务,这显然是不符合实际的。
计算机专业可能看到上面的话就想到了,每次去离自己最近的点,这不就是深度优先搜索吗。没错这是一种贪心的考虑,每次去离自己最近的且未走过的点,直到点的距离大于某个设定的值时停止,这时走过的点就在一个包里。
至于分包后的定价,这个就很难说什么好坏了,一般来说既然费心把任务打包了,那应该是会省点钱。但是看原题。
打包的目的是为了避免用户争抢,说明打包后用户的积极性低了,如果从这个角度考虑,打包后的定价可能高于各任务的定价和。
对最终的任务完成情况又有什么影响?
这个同样没什么对错,我也没什么好主意,言之有理即可,不实际试试,评委也不知道有什么影响,只要你能说服评委,你就赢了。
易错点
可能有人会觉得打包后挨个去完成任务这不是图的遍历吗?迪杰斯特拉啊!
但实际上人是贪心的,而且Dijkstra并不是经过每个点只一次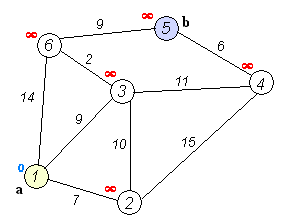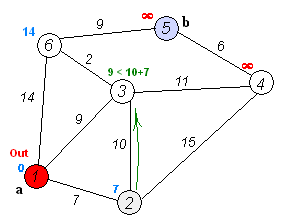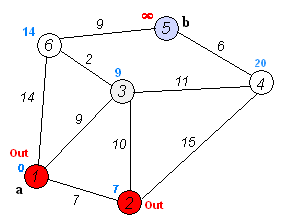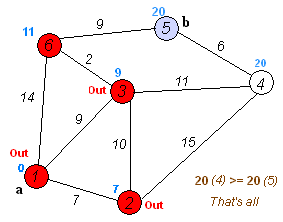
这更像一个货郎担问题,但是货郎担问题本就是一个NP难解的,更何况这个时候还没有分包呢。
问题四,对附件三中的新项目给出你的任务定价方案,并评价该方案的实施效果
这题就是问题三模型的应用,数学模型是用于解决一类问题的,建完模型后总要让你用用。
把附件三的数据标到地图上差不多是这个样子。
这几乎就是在你耳边对你喊一定要记得用问题三的结论把任务打包啊!!!!
虽然他们看起来已经很完美的分成了几堆,但这是地图,实际上离得还是挺远的。
我分类后的结果是这样
每种颜色是一类,灰色是没有被分类的任务,实际上这是尝试了好几个距离得到的结果,距离很小被分类的任务也很少,距离大了可能一个包里会包含二三十个任务,那任务量就太大了,试了好几次才找到这么一个看起来还不错的结果。
因为附件三只有任务的经纬度,没有给新的条件,所以也很难有漂亮的发挥,只能根据前面得到的模型,做些“合理”的修改,得到“合理”的结果。主要是写手的水平,能写的“看起来很有道理的样子”就好。