经典网络整理
经典网络架构
VGG16
googleNet
ResNet
ResNet参考资料
查看超分重建.md对应章节
DenseNet
DenseBlock是DenseNet的内部单元,DenseNet由多个DenseBLock通过Transition来连接起来
bottleneck 就是减少channels数量,通常采用Conv1*1来实现
Bottleneck Layer是指在DenseBlock中,输入由很多层结构拼接,那么需要转换为标准输出数量的层,因此用了一个1X1的Conv2d,这个1X1的卷积层被命名为Bottleneck层;实际就是一个1X1的卷积
-
网络中的重要参数
-
Growth rate:位于_DenseLayer中;看代码
-
Compression: 这个位于Transition层中,就是决定多少输出 out_channels = 压缩率*in_channels
-
-
网络结构
原文解析

从表格中获取如下信息:
-
DenseNet的DenseBlock是有n个 1*1Conv + 3*3Conv组成
-
原始是用于目标分类的
-
有Pooling,output size逐步变小,最终输出的是分类节点数
-
Transition Layer作用:就是Pooling作用,缩小output size。 Transition由BN+1*1 conv + pooling组成;在图上看不到BN的存在
-
每层的输入是不固定的 k*(l-1) channel,但每层的输入是固定的k channel
-
-
网络结构
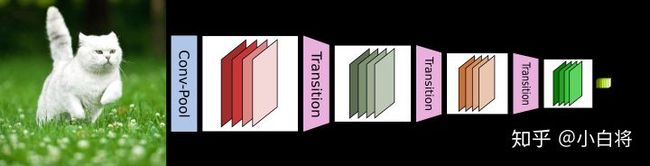


DenseNet由多个DenseBlock构成,每个DenseBlock由多个DenseLayer组成。通过Transition连接两个DenseBlock

-
特点
-
因为存在很多跳连,减少了空梯度问题,更容易训练
-
加强了特征重用
-
DenseNet层的filters数量比较少,使得层比较狭窄
-
-
pytorch 源码分析
- DenseBlock结构
内部结构:BN + Relu + 11Conv2d + BN + Relu +33 Conv2d
pytorch源码分析class _DenseLayer(nn.Sequential): # 注意这里继承的是nn.Sequential """Basic unit of DenseBlock (using bottleneck layer) """ # DenseLayer(64+i*32, 32, 4, 0) # 输入通道数 num_input_features = 64+i*32 # 中间通道数 growth_rate*bn_size = 32*4 这就说明是个大肚子?中间channel数多,当然是由参数决定的 # 输出通道数 growth_rate + num_input_features = num_input_features + 32 def __init__(self, num_input_features, growth_rate, bn_size, drop_rate): super(_DenseLayer, self).__init__() self.add_module("norm1", nn.BatchNorm2d(num_input_features)) self.add_module("relu1", nn.ReLU(inplace=True)) self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate, kernel_size=1, stride=1, bias=False)) self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate)) self.add_module("relu2", nn.ReLU(inplace=True)) self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)) self.drop_rate = drop_rate def forward(self, x): ''' 1. 调用nn.Sequential的forward 2. new_features 是本次的新特征 3. torch.cat([x, new_features], 1) 这里是神来之笔,实现了稠密连接 3.1 x是前一层的自身输出 + 前一层的输入;涵盖了之前所有层的输出 ''' new_features = super(_DenseLayer, self).forward(x) # 丢掉一部分 if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) # 采用 cat方式,非resnet的按元素加操作, x 含有了之前所有层的输出,随着迭代,x包含的channel越来越多 return torch.cat([x, new_features], 1)# 注意这里继承的是nn.Sequential class _DenseBlock(nn.Sequential): """DenseBlock""" # DenseBlock(6, 64, 4, 32, 0) def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate): super(_DenseBlock, self).__init__() for i in range(num_layers): # DenseLayer(64+i*32, 32, 4, 0) layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size, drop_rate) self.add_module("denselayer%d" % (i+1,), layer)-
Transitiion
class _Transition(nn.Sequential): """Transition layer between two adjacent DenseBlock""" def __init__(self, num_input_feature, num_output_features): super(_Transition, self).__init__() self.add_module("norm", nn.BatchNorm2d(num_input_feature)) self.add_module("relu", nn.ReLU(inplace=True)) self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features, kernel_size=1, stride=1, bias=False)) self.add_module("pool", nn.AvgPool2d(2, stride=2)) -
DenseNet
class DenseNet(nn.Module): "DenseNet-BC model" def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000): """ :param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper :param block_config: (list of 4 ints) number of layers in each DenseBlock :param num_init_features: (int) number of filters in the first Conv2d :param bn_size: (int) the factor using in the bottleneck layer :param compression_rate: (float) the compression rate used in Transition Layer :param drop_rate: (float) the drop rate after each DenseLayer :param num_classes: (int) number of classes for classification """ super(DenseNet, self).__init__() # first Conv2d self.features = nn.Sequential(OrderedDict([ ("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)), ("norm0", nn.BatchNorm2d(num_init_features)), ("relu0", nn.ReLU(inplace=True)), ("pool0", nn.MaxPool2d(3, stride=2, padding=1)) ])) # DenseBlock 从这里看DenseBlock之间是无稠密连接的 num_features = num_init_features for i, num_layers in enumerate(block_config): # DenseBlock(6, 64, 4, 32, 0);输入是64 channel + num_layers*32,输出是32channel+ 输入通道数(在_DenseBlock输出是做了拼接操作) block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate) #注册 self.features.add_module("denseblock%d" % (i + 1), block) # 这里同步更新输出通道数 num_features += num_layers*growth_rate if i != len(block_config) - 1: # 这里就是输入通道数和输出通道数,通过compression_rate来压缩通道数 transition = _Transition(num_features, int(num_features*compression_rate)) #注册 self.features.add_module("transition%d" % (i + 1), transition) # 下一个DenseBlock的输入通道数 num_features = int(num_features * compression_rate) # final bn+ReLU self.features.add_module("norm5", nn.BatchNorm2d(num_features)) self.features.add_module("relu5", nn.ReLU(inplace=True)) # classification layer self.classifier = nn.Linear(num_features, num_classes) # params initialization for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.bias, 0) nn.init.constant_(m.weight, 1) elif isinstance(m, nn.Linear): nn.init.constant_(m.bias, 0) def forward(self, x): features = self.features(x) out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1) out = self.classifier(out) return out
[参考文献]
1. pytorch densenet 实现
2. DenseNet
3. DenseNet原文解析
DRN CVPR2017
-
语义分割 扩张卷积 DRN : Dialted Residual Networks
-
pytorch实现
-
对于多曝光融合的Resnet Gan的描述可以考虑用这个描述
在卷积神经网络中使用下采样会降低feature的空间分辨率,这会丢失许多细节,从而影响模型对小型目标乃至目标之间关系的识别。 论文以Resnet为基础,提出了一个改进方法,在resnet的top layers移除下采样层,这可以保持feature map的空间分辨率,但后续的卷积层接收野分辨率下降了,这不利于模型聚合上下文信息。针对这一问题,论文使用扩张卷积替换下采样,在后续层合理使用扩张卷积,在保持feature map的空间分辨率同时维持后续层接收野的分辨率。 ···
Gan 网络
普通GAN
SRGan
ESRGAN(提出了RRDB)
-
提出RRDB网络,这个是在DenseNet基础上进一步的稠密连接
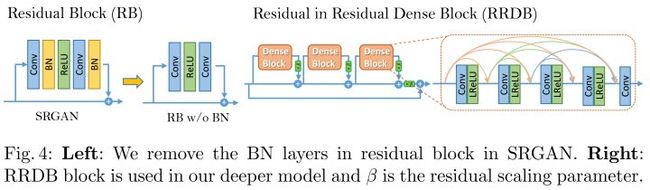
-
DenseNet是DenseBlock内部的稠密连接,DenseBlock之间通过Transition连接,不是稠密连接
-
改动
-
仅改动了G4和G5
-
至于为什么不全替换了下采样层,是因为在全分辨率下不使用下采样,内存消耗超出当前硬件的能力。
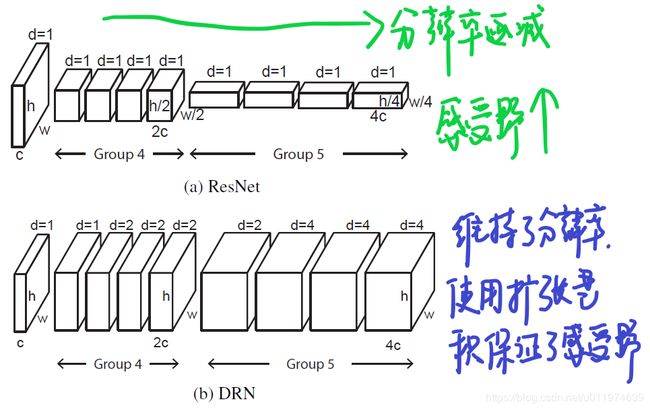
-
-
扩张会产生 Degridding问题
- Degridding是什么? 大致可以总结当使用的扩张率增加,采样点之间相隔较远,局部信息丢失,产生的预测图出现网格效应

-
给出的解决方法
-
(a): 移除最大池化层,使用卷积滤波器代替最大池化
这样的高频传播到网络后面,会加剧gridding影响。


-
(b): 添加图层
-
©: 移除残差连接

-
迁移GAN
CycleGAN
General的GAN面向一个domain的数据,G尝试生成尽可能接近真实的数据,而D则尽可能地分辨来自domain的真实数据和生成数据。两者是一直在博弈的,博弈中G逐渐占据上风,最终生成的数据跟domain的数据没什么两样

官方Pytorch代码
知乎参考
DualGAN 对偶Gan
-
style迁移,人物-卡通 / 卡通-人物
-
风景画加上梵高风格
-
斑马映射到马
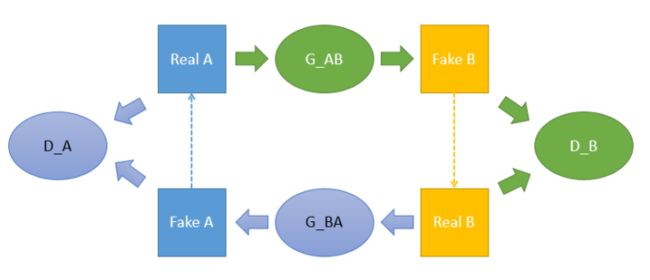
你并不需要pair的数据
知乎参考
- 去掉重构误差?模型是否还有效?
模型仍然有效,只是收敛比较慢,毕竟缺少了重构误差这样的强引导信息。以及,虽然实现了风格迁移,但是人物的一些属性改变了,比如可能出现『变性』、『变脸』,而姿态在转换的时候一般不出现错误。这表明,对偶重构误差能够引导模型在迁移的时候保留图像固有的属性;而对抗loss则负责确定模型该学什么,该怎么迁移。
论文地址:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
官方Pytorch代码
- 这里B本身是B domain的,那么经过G_A(B)生成的还是B domain的,这个损失应该较小才对
"""Add new dataset-specific options, and rewrite default values for existing options.
Parameters:
parser -- original option parser
is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
Returns:
the modified parser.
For CycleGAN, in addition to GAN losses, we introduce lambda_A, lambda_B, and lambda_identity for the following losses.
A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A.
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A||
* lambda_A) (Sec 5.2 "Photo generation from paintings" in the paper)
这里B本身是B domain的,那么经过G_A(B)生成的还是B domain的,这个损失应该较小才对
Dropout is not used in the original CycleGAN paper.
"""
DiscoGAN
BeautyGAN
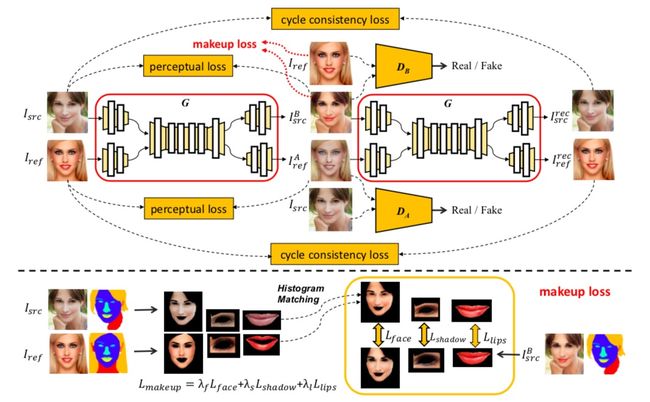
一键上妆的BeautyGAN
tensorflow复现的代码
美妆迁移,几篇GAN
2018CVPR:PairedCycleGAN
值得研究和借鉴
- 是否可以用于去雾
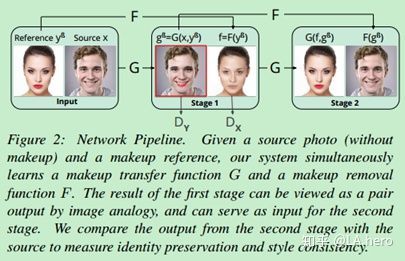
风格迁移GAN、CGAN、StarGAN、CycleGAN、AsymmetricCycleGAN
风格迁移
CycleGAN
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OhRaPYCj-1588823377245)(https://ask.qcloudimg.com/http-save/1309561/a3w7j15rcm.jpeg?imageView2/2/w/1620)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bYNCM5UX-1588823377247)(https://ask.qcloudimg.com/http-save/1309561/a3w7j15rcm.jpeg?imageView2/2/w/1620)]
基于GAn的人脸光照处理 (无代码)
-
Face Image Illumination Processing Based on Generative Adversarial Nets
-
主要参考一些损失函数的定义
-
结构图

参考blog