以下内容针对互斥锁。
为什么需要锁?
锁代表着对临界区的访问权限。只有获得锁的操作对象,才能进入临界区。
锁的本质是什么?
锁的本质是一个数据结构(或者说是一个对象),这个对象内保留着描述锁所需要的必要信息。如当前锁是否已被占用,被哪个线程占用。而锁的一些工具,函数库,实际上就是对一个锁对象的信息进行变更。
上锁操作 => 尝试对锁对象的信息进行修改,如果修改成功,则程序继续向下执行,否则将暂时停留在此。(停留的方式有两种,一种是自旋反复尝试,另一种是挂起等待唤醒)
解锁操作 => 重置锁对象的信息。
类似下面这样(注:这个例子不准确,后面会讲)
typedef struct __lock_t { int flag; //锁的状态 0-空闲, 1-被占用 } lock_t; void init(lock_t *mutex) { //初始化锁对象 mutex->flag = 0; } void lock(lock_t *mutex) { while(mutex->flag == 1) ;// 自旋等待 mutex->flag = 1; } void unlock(lock_t *mutex) { mutex->flag = 0; }
锁信息的存储位置
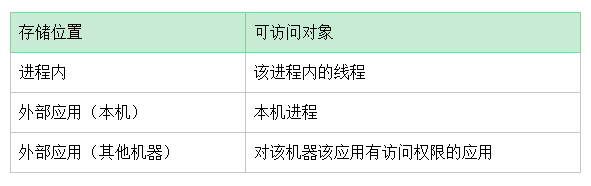
一种是保留在进程内,由于操作系统提供的内存虚拟化,所以这个锁对象的内存空间,只能被当前进程访问。并且同一进程的线程可以共享内存资源。所以,这个锁对象只能被当前进程的线程所访问。
另一种是将锁的信息保存在本机的其他应用中。例如本机没有开启外部访问的Redis。这样本机的多个应用就可以通过Redis中的这个锁的信息进行调度管理。
还有一种就是将锁的信息保存在其他机器中(或者本机开启外部访问的Redis中),这样其他电脑的应用也可以对这个锁进行访问,这就是分布式锁。
对锁信息进行修改
存在的问题
前面有提到,前面的lock函数对锁信息的修改操作存在问题,我们来看看问题到底出在哪里。假设,我们的电脑只有一个CPU,这个时候有两个线程开始尝试获取锁。

这个程序的结果是,在线程B已经占用锁的时候,线程A还能获取到锁。这就不能满足"互斥锁"的定义,这段代码就不满足正确性。那么问题出在哪里呢?问题就在于判断和修改这两个操作没有原子性。
正如上面的例子那样,线程A刚执行完判断,还没来得及做修改操作,就发生了上下文切换,转而执行线程B的代码。切换回线程A的时候,实际上条件已经发生了变更。
硬件的支持
这个问题显然不是应用的代码能够解决的,因为上下文切换是OS决定的,普通应用无权干涉。但是硬件提供了一些指令原语,可以帮助我们解决这个问题。这些原语有test-and-set、compare-and-swap、fetch-and-add等等,我们可以基于这些原语来实现锁信息修改的原子操作。例如,我们可以基于test-and-set进行实现:
//test-and-set的C代码表示 int TestAndSet(int *ptr, int new) { int old = *ptr; //抓取旧值 *ptr = new; //设置新值 return old; //返回旧值 } typedef struct __lock_t { int flag; } lock_t; void init (lock_t *lock) { lock->flag = 0; } void lock(lock_t *lock) { //如果为1,说明原来就有人在用 //如果不为1,说明原来没人在用,同时设置1,表明锁现在归我使用了 while (TestAndSet(&lock->flag, 1) == 1) ; //spin-wait (do noting) } void unlock (lock_t *lock) { lock->flag = 0; }
为什么这些指令不会被上下文切换所打断?
上下文切换实际上也是执行切换的指令。CPU执行指令是一条一条执行的,test-and-set对于CPU来说就是一个指令,所以就算需要进行上下文切换,它也会先执行完当前的指令,然后再执行上下文切换的指令。