zookeeper 集群部署(4)
zookeeper集群

可靠的zookpeer服务
只要集群的大多数准备好了,就可以使用这项
容错集群至少要三台以上机器,建议奇数以上
建议独立运行在每个服务器上
集群参数配置
initLimit
集群中的follower服务器(F)与leader服务器(L)之间完成初始化同 步连接时能容忍的最多心跳数(tickTime的数量)。如果zk集群 环境数量确实很大,同步数据的时间会变长,因此这种情况下可以适当调大该参数。
syncLimit
集群中的follower服务器与leader服务器之间请求和应答之间能
容忍的最多心跳数(tickTime的数量)。
集群节点
server.id=host:port:port
您可以通过创建名为myid的文件将服务器ID归因于每台计算机,每个服务器对应一个文件 ,该文件位于该服务器的数据目录中,由配置文件参数dataDir指定。
myid文件(需要手动创建)由一行组成,只包含该机器id的文本。所以服务器1的myid将包含文本“1”而没有别的。id在整体中必须是唯一的,其值应介于1到255之间。 重要信息:如果启用TTL节点等扩展功能(见下文),由于内部限制,id必须介于1和254之间。
两个端口号:前者是跟随用来链接leader,后者是用来选择leader.
集群的所有节点都可以提供服务,客户端连接时,连接串可以指定多个或全部节点连接地址。如果一个节点出现故障,自动切换到其它节点。

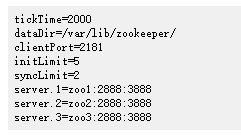
ZooKeeper 监控控制台
1.四字命令
ZooKeeper响应一小组命令。每个命令由四个字母组成。您可以通过telnet或nc在客户端端口向ZooKeeper发出命令。
示例:$ echo ruok | nc 127.0.0.1 5111
-
conf:3.3.0中的新功能:打印有关服务配置的详细信息。
-
缺点:3.3.0中的新功能:列出连接到此服务器的所有客户端的完整连接/会话详细信息。包括有关接收/发送的数据包数量,会话ID,操作延迟,上次执行的操作等信息...
-
crst:3.3.0中的新功能:重置所有连接的连接/会话统计信息。
-
dump:列出未完成的会话和临时节点。这只适用于领导者。
-
envi:打印有关服务环境的详细信息
-
ruok:测试服务器是否在非错误状态下运行。如果正在运行,服务器将使用imok响应。否则它根本不会响应。“imok”的响应不一定表示服务器已加入仲裁,只是服务器进程处于活动状态并绑定到指定的客户端端口。有关状态wrt仲裁和客户端连接信息的详细信息,请使用“stat”。
-
srst:重置服务器统计信息。
-
srvr:3.3.0中的新功能:列出服务器的完整详细信息。
-
stat:列出服务器和连接客户端的简要详细信息。
-
wchs:3.3.0中的新功能:列出服务器手表的简要信息。
-
wchc:3.3.0中的新功能:按会话列出服务器监视的详细信息。这将输出与相关监视(路径)的会话(连接)列表。请注意,根据手表的数量,此操作可能很昂贵(即影响服务器性能),请谨慎使用。
-
dirs:3.5.1中的新增功能:显示快照和日志文件的总大小(以字节为单位)
-
wchp:3.3.0中的新功能:按路径列出服务器监视的详细信息。这将输出一个包含相关会话的路径列表(znodes)。请注意,根据手表的数量,此操作可能很昂贵(即影响服务器性能),请谨慎使用。
-
mntr:3.4.0中的新增内容:输出可用于监视群集运行状况的变量列表。
$ echo mntr | nc localhost 2185
zk_version 3.4.0
zk_avg_latency 0
zk_max_latency 0
zk_min_latency 0
zk_packets_received 70
zk_packets_sent 69
zk_outstanding_requests 0
zk_server_state leader
zk_znode_count 4
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 27
zk_followers 4 - only exposed by the Leader
zk_synced_followers 4 - only exposed by the Leader
zk_pending_syncs 0 - only exposed by the Leader
zk_open_file_descriptor_count 23 - only available on Unix platforms
zk_max_file_descriptor_count 1024 - only available on Unix platforms
zk_fsync_threshold_exceed_count 02.JMX (Java Management Extensions)
是一个应用程序,设备管理功能的框架。
zookeeper集群leader选举
对leader要求 :
第一个,跟随者需要保持正确操作的最高zxid。
第二个要求,即法定数量的追随者,只需要很高的概率。我们将重新检查第二个要求,因此如果在领导者选举期间或之后发生失败并且法定人数丢失,我们将通过放弃领导者激活和进行另一次选举来恢复。
两个领导者选举算法:
- LeaderElection
- FastLeaderElection
- AuthFastLeaderElection是FastLeaderElection的变体
zookeeper集群leader选举机制概念
选举机制的概念
- 服务器id->myid
- 事务id->服务器存放最大zxid
- 逻辑时钟->发起的投票轮数计数
- 选举状态
- LOOOKING 竞选状态。
- FOLLOWING 跟随者状态,同步leader状态,参与投票。
- OBSERVING 观察者状态,同步leader状态,不参与投票。
- LEADING 领导者状态。
选举消息内容:
服务id、事务id、逻辑时钟、选举状态
zookeeper集群leader选举机制概念
- 每个服务均发起选举自己为leader投票(自己给自己投)
- 其它服务实例收到投票邀请,比较发起者的数据事务id是否比自己最新的事务id大,大则投给他一票,小则不投,相等的比较发起者的服务id,大则给它投。
- 发起者收到大家的投票结果后,看投票数(包含自己)是否大于集群的半数,大则胜任担任者;未超过半数的,则在发起投票选举。
胜出条件:投票赞成数大于半数则胜出。
zookeeper集群leader选举流程示例说明
有5台机器,每台机器均没有数据,它们的编号分别是1,2,3,4,5 按编号一次启动,它们的选举过程如下:

zookeeper工作原理
应用集群
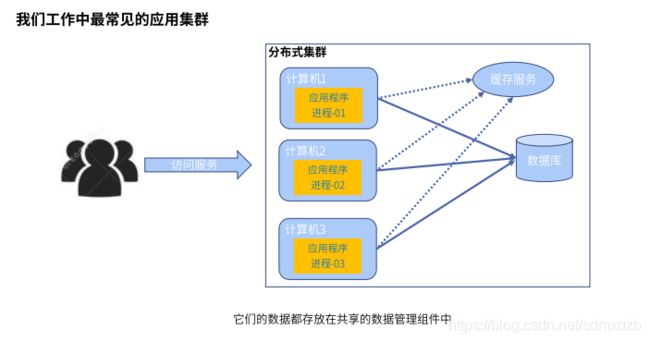
zookeeper数据一致性问题
ZAB(zookeeper Atomic Broadcasr,原子消息广播)是专门为zk设计的数据一致性协议。参考paxos来实现。
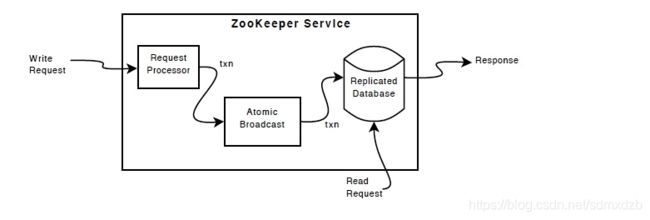
ZAB协议基本原则
原文:
It all sounds complicated but here are the basic rules of operation during leader activation:
- A follower will ACK the NEW_LEADER proposal after it has synced with the leader.
- A follower will only ACK a NEW_LEADER proposal with a given zxid from a single server.
- A new leader will COMMIT the NEW_LEADER proposal when a quorum of followers have ACKed it.
- A follower will commit any state it received from the leader when the NEW_LEADER proposal is COMMIT.
- A new leader will not accept new proposals until the NEW_LEADER proposal has been COMMITED.
If leader election terminates erroneously, we don't have a problem since the NEW_LEADER proposal will not be committed since the leader will not have quorum. When this happens, the leader and any remaining followers will timeout and go back to leader election.
- 跟随者将在与领导者同步后确认NEW_LEADER提案。
- 跟随者只会使用来自单个服务器的给定zxid确认NEW_LEADER提议。
- 当法定数量的粉丝确认后,新的领导者将提交NEW_LEADER提案。
- 当NEW_LEADER提议为COMMIT时,关注者将提交从领导者收到的任何州。
- 在NEW_LEADER提案获得COMMITED之前,新领导者不会接受新提案。
活动消息
Leader Activation does all the heavy lifting. Once the leader is coronated he can start blasting out proposals. As long as he remains the leader no other leader can emerge since no other leader will be able to get a quorum of followers. If a new leader does emerge, it means that the leader has lost quorum, and the new leader will clean up any mess left over during her leadership activation.
如果领导者选举错误地终止,我们就没有问题,因为由于领导者没有法定人数,因此不会提交NEW_LEADER提案。当发生这种情况时,领导者和任何剩下的追随者将超时并返回领导者选举。
ZooKeeper messaging operates similar to a classic two-phase commit.
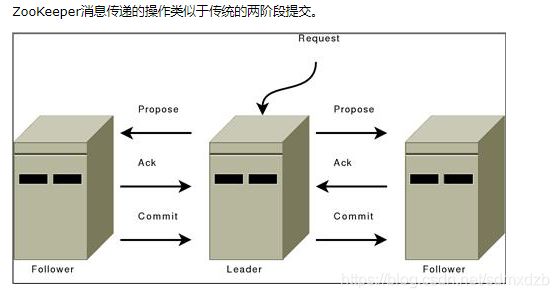
约束原文:
All communication channels are FIFO, so everything is done in order. Specifically the following operating constraints are observed:
- The leader sends proposals to all followers using the same order. Moreover, this order follows the order in which requests have been received. Because we use FIFO channels this means that followers also receive proposals in order.
- Followers process messages in the order they are received. This means that messages will be ACKed in order and the leader will receive ACKs from followers in order, due to the FIFO channels. It also means that if message $m$ has been written to non-volatile storage, all messages that were proposed before $m$ have been written to non-volatile storage.
- The leader will issue a COMMIT to all followers as soon as a quorum of followers have ACKed a message. Since messages are ACKed in order, COMMITs will be sent by the leader as received by the followers in order.
- COMMITs are processed in order. Followers deliver a proposals message when that proposal is committed.
所有通信通道都是FIFO,所以一切都按顺序完成。具体而言,遵守以下操作约束:
- 领导者使用相同的订单向所有粉丝发送提案。此外,此顺序遵循收到请求的顺序。因为我们使用FIFO通道,这意味着关注者也会按顺序接收提案。
- 关注者按照收到的顺序处理消息。这意味着将按顺序确认消息,并且由于FIFO通道,领导者将按顺序接收来自关注者的ACK。这也意味着如果消息$ m $已写入非易失性存储器,则在$ m $之前建议的所有消息都已写入非易失性存储器。
- 一旦有法定数量的粉丝确认消息,领导者将向所有粉丝发出COMMIT。由于消息按顺序被确认,因此将由跟随者按顺序接收的领导者发送COMMIT。
- COMMIT按顺序处理。在提交提案时,关注者会发送提案消息。
ZAB协议最重要的特性:有序性。
崩溃场景
Leader服务器崩溃,或者说由于网络原因导致Foller服务器失与Leader的联系,那么就会进入崩溃恢复的模式。
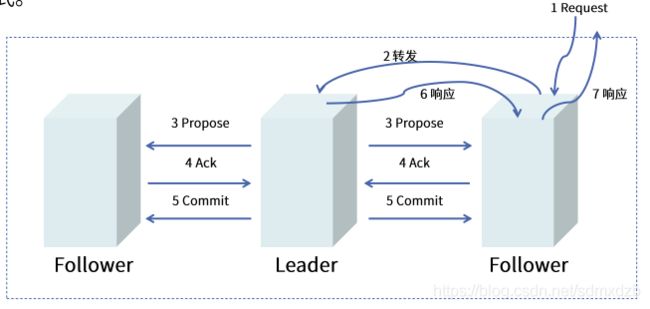
原文:
Guarantees, Properties, and Definitions
The specific guarantees provided by the messaging system used by ZooKeeper are the following:
-
Reliable delivery : If a message, m, is delivered by one server, it will be eventually delivered by all servers.
-
Total order : If a message is delivered before message b by one server, a will be delivered before b by all servers. If a and b are delivered messages, either a will be delivered before b or b will be delivered before a.
-
Causal order : If a message b is sent after a message a has been delivered by the sender of b, a must be ordered before b. If a sender sends c after sending b, c must be ordered after b.
The ZooKeeper messaging system also needs to be efficient, reliable, and easy to implement and maintain. We make heavy use of messaging, so we need the system to be able to handle thousands of requests per second. Although we can require at least k+1 correct servers to send new messages, we must be able to recover from correlated failures such as power outages. When we implemented the system we had little time and few engineering resources, so we needed a protocol that is accessible to engineers and is easy to implement. We found that our protocol satisfied all of these goals.
Our protocol assumes that we can construct point-to-point FIFO channels between the servers. While similar services usually assume message delivery that can lose or reorder messages, our assumption of FIFO channels is very practical given that we use TCP for communication. Specifically we rely on the following property of TCP:
-
Ordered delivery : Data is delivered in the same order it is sent and a message m is delivered only after all messages sent before m have been delivered. (The corollary to this is that if message m is lost all messages after m will be lost.)
-
No message after close : Once a FIFO channel is closed, no messages will be received from it.
FLP proved that consensus cannot be achieved in asynchronous distributed systems if failures are possible. To ensure we achieve consensus in the presence of failures we use timeouts. However, we rely on times for liveness not for correctness. So, if timeouts stop working (clocks malfunction for example) the messaging system may hang, but it will not violate its guarantees.
总结:
- ZAB协议规定,如果一个事物proposal在一太机器被处理成功,那么在所有机器上处理也都是成功的,即使机器出现故崩溃。
- ZAB协议确保那些已经在Leader服务提交事务最终被所有服务提交。
- ZAB协议确保丢弃那些只在Leader服务被提出的事物。
崩溃恢复
ZAB协议需要设计的选举算法应该满足:确保已经提交的Leader事务Proposal,同时丢弃那些已经跳过事务的Proposal.
如果让Leader选举算法能够保证新选举出来的Leader服务器拥有集群最高ZXID的事务Proposal,就可以保证这个新选举出来的Leader具有所有已经提交的提案。同时,如果让具有最高编号事务Proposal的机器成为Leader,那么可以省去Leader服务器检查Proposal的提交和丢弃工作的这一步操作。
数据同步
Leader选举出来后,先完成与Follower的数据同步,当完成半数时开始恢复提供服务。
同步过程
Leader服务器为每一个Follower服务器准备一个队列,并将那些没有被各Follower服务同步的事务以Proposal消息形式发送给Follower,并在每一个Proposal消息发送后紧接着发送一个Commit消息,表示该事务已经被提交。
Follower服务将所有其尚未从Leader同步事务的Proposal都从Leader服务器上同步过来成功,并保存到本地数据库中后,Leader服务器就会将该Follower服务器加入到很正的可用Follower列表中,并创建服务连接,开始其它流程。个人认为就是两事务Proposal提交,担保的问题。
丢弃事务Proposal处理
原文:
When describing the ZooKeeper messaging protocol we will talk of packets, proposals, and messages:
-
Packet : a sequence of bytes sent through a FIFO channel
-
Proposal : a unit of agreement. Proposals are agreed upon by exchanging packets with a quorum of ZooKeeper servers. Most proposals contain messages, however the NEW_LEADER proposal is an example of a proposal that does not correspond to a message.
-
Message : a sequence of bytes to be atomically broadcast to all ZooKeeper servers. A message put into a proposal and agreed upon before it is delivered.
As stated above, ZooKeeper guarantees a total order of messages, and it also guarantees a total order of proposals. ZooKeeper exposes the total ordering using a ZooKeeper transaction id (_zxid_). All proposals will be stamped with a zxid when it is proposed and exactly reflects the total ordering. Proposals are sent to all ZooKeeper servers and committed when a quorum of them acknowledge the proposal. If a proposal contains a message, the message will be delivered when the proposal is committed. Acknowledgement means the server has recorded the proposal to persistent storage. Our quorums have the requirement that any pair of quorum must have at least one server in common. We ensure this by requiring that all quorums have size (_n/2+1_) where n is the number of servers that make up a ZooKeeper service.
The zxid has two parts: the epoch and a counter. In our implementation the zxid is a 64-bit number. We use the high order 32-bits for the epoch and the low order 32-bits for the counter. Because it has two parts represent the zxid both as a number and as a pair of integers, (_epoch, count_). The epoch number represents a change in leadership. Each time a new leader comes into power it will have its own epoch number. We have a simple algorithm to assign a unique zxid to a proposal: the leader simply increments the zxid to obtain a unique zxid for each proposal. Leadership activation will ensure that only one leader uses a given epoch, so our simple algorithm guarantees that every proposal will have a unique id.
zxid有两个部分:纪元和计数器。在我们的实现中,zxid是一个64位数字。我们使用高阶32位用于纪元,低阶32位用于计数器。因为它有两个部分代表zxid既是数字又是一对整数(_epoch,count_)。时代数字代表了领导层的变化。每当新领导人上台时,它将拥有自己的纪元号码。我们有一个简单的算法来为一个提议分配一个唯一的zxid:领导者只需递增zxid以获得每个提案的唯一zxid。领导激活将确保只有一个领导者使用给定的纪元,因此我们的简单算法保证每个提案都具有唯一的ID。
个人理解:
每一个客户端的每一个事务请求,Leader服务器在产生一个新的Proposal的时候,都会对该计数器进行加1操作;高32位代表了Leader周期纪元的编号,每选举产生一个新的Leader服务器,就会从这个Leader服务器上取出本地日志最大事务的ZXID,并从该ZIXD中解析出对应的纪元值,然后加1操作,之后就会以此编号做为新纪元,并将低32位置0来开始生成新的ZXID.
基于这样的策略,当一个包含了上一个Leader周期尚未提交过的事务Proposal的服务器加入到新的集群中,发现已经有了新的Leader,就会将以Follower的形式与新Leader连接,新Leader会根据自己服务器上最后提交的事务Proposal来和上一个Follower(旧Leader)服务器的事务的Proposal对比,发现Follower中包含了上一个Leader周期的事务Proposal时,Leader会要求Follower回退到一个已经被集群中过半机器的最新事务Proposal。
个人认为这里其实就是大多数原则。
地址:http://zookeeper.apache.org/doc/current/zookeeperInternals.html#sc_atomicBroadcast
paxos算法资料下载地址:https://download.csdn.net/upload/11190407
curator实现方式:https://cloud.tencent.com/developer/article/1388344