特征匹配-NNDR策略,kd树,BBF算法
特征匹配需要考虑匹配策略和如何更快的完成匹配。
一:以欧式距离为度量,有三种匹配策略:固定阈值、最近邻、最近邻距离比率(NNDR)
固定阈值:就是设定一个阈值,当距离大于阈值,判为不匹配,否则判为匹配。但是一个问题是,阈值很难设定。随着移动到特征空间的不同部分时,阈值的有效范围会变化很大,即没有通用的阈值。
最近邻:找最近的那个。
最近邻距离比率:定义为最近邻距离和次近邻距离的比值。
最近邻和NNDR策略改善了匹配效果。
——————————————————————————————————————
————————————更详细的介绍————————————————————
参考:结合NNDR与霍夫变换的匹配方法。
在建立两幅图像之间局部特征的匹配关系时,需要满唯一性、相似性、连续性三个基本约束条件,即物体表面任意一点到观察点距离是唯一的,因此其视差是唯一的,给定一副图像中的一点,其在另一幅图像中对应的匹配点最多只有一个;对应的特征应有相同的属性,在某种度量下,同一物理特征在两幅图像中具有相似的描述符;与观测点的距离相比,物体表面因凹凸不平引起的深度变化是缓慢的,因而视差变化是缓慢的,或者说视差具有连续性。
目前常用的目标匹配策略有两种:1、是距离阈值法,即待匹配目标与模型之间的距离小于某个阈值,则认为匹配上了,改方法非常简单,但是阈值的确定非常困难,而且目标很容易匹配上多个模型,从而产生大量的误匹配;2、最小距离法,即目标只匹配与其距离最近的模型,实际应用中一般还需要满足距离小于某个阈值的条件,该方法只有一个最佳的匹配结果,相对于距离阈值法来说,正确率要高。
由于图像的内容千差万别,加上场景中运动物体,不重叠内容以及图像质量等因素的存在,一副图像中的局部特征并不一定能够在另一幅图像中找到相似的特征,这就需要采取措施剔除那些产生干扰的噪声点。
3、通过对SIFT特征的研究表明,可以通过比较最近邻特征和次近邻特征的距离有效的甄别局部特征是否正确匹配。这就是最近邻距离比值法。该方法的理论来源是,如果一个特征在一副图像中与两个特征的距离都很相似,那么该特征的区分度较低,会对图像相似度的判断产生干扰。
——————————————————————————————————————
——————————————————————————————————————
二:高效完成匹配
选定匹配策略,下面要做的就是在潜在的候选中高效地进行搜索。
1、用穷举法搜索最近邻点以及次紧邻点,即在每对潜在的匹配图像中将特征和其他所有特征进行一一匹配。想法简单自然,并且可以得到最精确的结果,但是由于特征空间一般都高达128维以上,加之复杂图像的局部特征数量比较多,搜索算法的效率是整个系统的一个瓶颈。
2、导出一个索引结构,来快速寻找一个给定特征的邻近的特征。广泛使用的索引结构是多维搜索树,这里介绍最著名的k-d树,
因为实际数据一般都会呈现簇状的聚类形态,因此我们想到建立数据索引,然后再进行快速匹配。索引树是一种树结构索引方法,其基本思想是对搜索空间进行层次划分。k-d 树是索引树中的一种典型方法。
2-1、k-d树
是对数据点在k维空间中划分的一种数据结构。k-d树实际上是一种二叉树。
----------------------------------------------------------------------------------------------------------------------------
k-d树的节点组成集合为样本集,每个结点表示一个样本点。根据分裂结点的分割超平面将样本空间分为两个子空间。左子空间中的样本点集合由左子树表示,右空间中的样本点集合由右子树表示。分割超平面是一个通过分裂点并且垂直于分割序号所指示的方向轴的平面。
----------------------------------------------------------------------------------------------------------------------------
一个简单例子说明分割:在二维的情况下,一个样本点可以由二维向量(x,y)表示,其中令x维的序号为0,y维的序号为1.假设分裂结点为(7,2),垂直于分割超平面的方向轴序号为0,那么分割超平面就是x=7,他垂直于x轴且过点(7,2)如下所示:

(红线代表分割超平面)
于是其他数据点的x维如果小于7,则被分配到左子空间;若大于7,则被分配到右子空间。如(5,4)被分配到左子空间,(9,6)被分配到右子空间。
所以可看出k-d树本质上是一种二叉树。
---------------------------------------------------------------------------------------
分裂结点的选择通常有多种方法,最常用的一种方法:对于所有的样本点,统计他们在每个维上的方差,挑选出方差中的最大值,对应的维就是垂直于分割超平面的方向轴,如x轴上方差最大则分割超平面垂直于x轴画出。数据方差最大表明沿该维度数据点分散的比较开,这个方向进行数据分割可以获得最好的分辨率。然后再将所有样本点在以上方向轴方向进行排序。。
---------------------------------------------------------------------------------------
一个例子来说明:
假设样本集为{(2,3),(5,4)(9,6)(4,7)(8,1)(7,2)}。构建k-d树的过程如下:
1、确定split域。6个数据点在x,y维度上的数据方差分别为39,28.63。所以在x轴上方差最大,所以split阈值为0(x维的序号为0)
2、确定分裂结点,根据x维上的值将数据排序,则6个数据点在排序后位于中间的那个数据点为(7,2),该结点就是分割超平面就是通过(7,2)并垂直于split=0即x轴的直线x=7;
3、左子空间和右子空间,分割超平面x=7将整个空间分为两部分,x<=7的部分为左子空间,包含3个数据点{(2,3)(5,4)(4,7)}另一部分为右子空间,包含2个数据点{(9,6)(8,1)}
4、分别对左子空间中的数据点和右子空间中的数据点重复上面的步骤构建左子树和右子树直到经过划分的子样本集为空。

————————————————————————————————————————
————————————————————————————————————————
k-d树的最近邻搜索算法:
在k-d树中进行数据的k近邻搜索是特征匹配的重要环节,其目的是检索在k-d树中与待查询点距离最近的k个数据点。
最近邻搜索是k近邻的特例,即1近邻。最近邻搜索的思路很简单:首先通过二叉树搜索(比较待查询结点和分裂结点的分裂维的值,小于等于则进入左分支,大于就进入右分支直到叶子结点),顺着“搜索路径”很快能找到最近邻的近似点,也就是与待查查询点处于同一个子空间的叶子结点;然后再回溯搜索路径,并判断搜索路径上的 结点的其他子节点空间中是否可能有距离查询点更近的数据点,如有可能,则需要跳到其它子结点空间中去搜索(将其他子结点加入到搜索路径)。重复这个过程直到搜索路径为空。
——————————————————————————————————————————————
举例说明最近邻搜索算法:
假设根据之上步骤样本集{(2,3)(5,4)(9,6)(4,7)(8,1)}建立了k-d树。,将上面的图转换成树形图如下:

我们查找点(2.1,3.1),在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后搜索路径中的结点为<(7,2)(5,4)(2,3)>,从搜索路径中取出(2,3)作为当前最佳结点nearest,距离dist为0.141.
然后回溯到(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和超平面y=4相交,如下图,所以不必跳到结点(5,4)的右子空间去搜索,因为右子空间中不可鞥有更近样本点了。
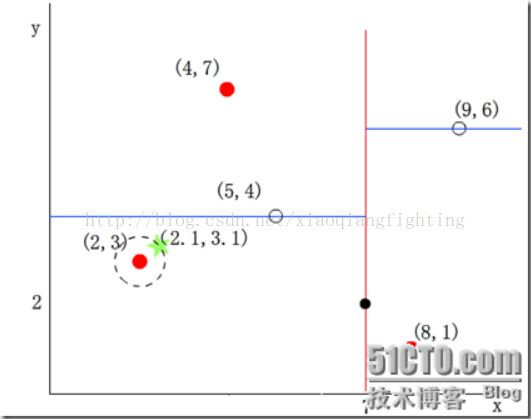
于是在回溯到(7,2),同理以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆并不和超平面x=7相交,所以不必跳到结点(7,2)的右子空间去搜索。
至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2.1,3.1)的最近邻点,最近距离为0.141。
然而有时有些复杂情况。如查找点(2,4.5),在(7,2)处测试到达(5,4),在(5,4)处测试到达(4,7)。然后搜索路径search_path中的结点为<(7,2)(5,4)(4,7)>,从搜索路径search_path中取出(4,7)作为当前最佳结点nearest,距离dist=3.202.
然后回溯到(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交。如下图,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到搜索路径search_path中,所以现在search_path中的结点为<(7,2)(2,3)>;又因为(5,4)与(2,4.5)的距离为3.04小于距离dist=3.202所以将(5,4)付给nearest并且dist=3.04.

回溯至(2,3),(2,3)是叶子节点,直接判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为1.5.
回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交,所以不用跳到结点(7,2)的右子空间去搜索。
至此,search_Path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点。最近邻距离为1.5
还可以参考:July的http://blog.sina.com.cn/s/blog_52284fb50101218x.html,写的很好!
上面两次搜索返回的最近邻点虽然是一样的,但是搜索(2,4.5)的过程要复杂的多,因为(2,4.5)更接近超平面。研究表明当查询点的邻域与分割超平面两侧的空间都产生交集时,回溯的次数大大增加。由于大量回溯会导致k-d树最近邻搜索的性能大大下降,因此提出了一些改进方法,比较著名的就是Best--Bin--First (BBF算法)。他通过设置优先级队列和运行超时限定来获取
2-2 BBF算法
BBF算法是KD树的改进方法,从上述标准的KD树的查询过程可以看出其搜索过程中的“回溯”是由“查询路径”决定的,并没有考虑查询路径上一些数据点本身的一些性质。一个简单的改进思路就是将“查询路径”上的结点进行排序,如按各自分割超平面(也称bin)与查询点的距离排序,也就是说,回溯检查总是从优先级最高(best bin)的树结点开始。
BBF算法是针对高维数据提出的一种近似算法,此算法能确保优先检索包含最近邻点可能性较高的空间,此外,BBF还设置了一个运行超时限定机制。
————————————————————————————————————————————————
一个例子说明,还是查询(2,4.5)搜索算法流程为:
1、将(7,2)压入优先队列中;
2、提取优先队列中(7,2),由于(2,4.5)位于(7,2)分割超平面的左侧,所以检索其左子节点(5,4)。同时,根据BBF机制“搜索左/右子树,就把相应这一层的兄弟结点即右/左结点存进队列”,将其(5,4)对应的兄弟结点即右子节点(9,6)压入优先队列中,此时优先队列为{(9,6)},最佳点为(7,2);然后一直检索到叶子节点(4,7),此时优先队列为{(2,3)(9,6)},最佳点则为(5,4)
3、提取优先级最高的结点(2,3),重复步骤2,直到优先队列为空。
参考整理自:
1、http://blog.sina.com.cn/s/blog_52284fb50101218x.html
2、http://blog.sina.com.cn/s/blog_52284fb50101218x.html