【分支限界法】0-1背包问题系列3
问题&&题目分析
假设有n个物品和1个背包,每个物品的重量为wi,价值为vi,每个物品只有1件,要么装入,要么不装,不可拆分,背包载重量一定,如何装使背包装入的物品价值最高?
算法
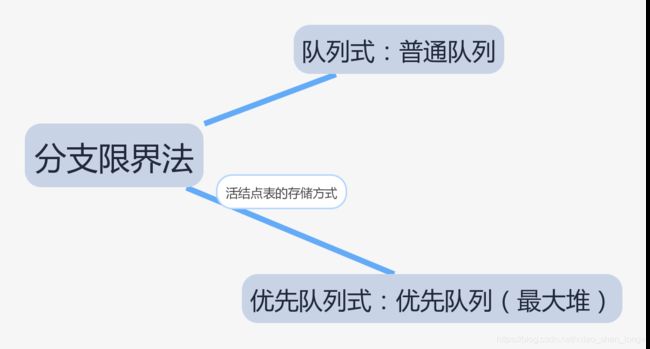
分支限界法
分支限界法就是广度优先搜索,从活结点表中取出队首的活结点,一次性生成所有符合条件的孩子结点,把孩子结点加入活结点表,然后继续下一个结点的扩展,直至得到最优解或者是活结点表为空。
算法核心
跟回溯法有点像,就是用约束条件判断能否生成左孩子结点,用限界条件判断能否生成右孩子结点,但是这里不需要回溯,因为是广度优先,而不是深度优先,分支限界法的搜索是逐层的。
约束条件,这里的约束条件就是背包剩余容量>=当前物品的重量,这样当前物品才可能放进背包。
限界条件,这里的限界条件就是当前背包中物品的价值+之后所有物品的价值>=之前计算得到的最大价值,看到这里有没有觉得和回溯法非常类似。但是还是有不同的地方,回溯法这里没有等号,但是分支限界法有。还是由算法的搜索方式决定的,回溯法是深度优先,如果得到最优解就意味着一定走到了某个叶子结点。但是分支限界法不一样,它是广度优先,得到最优解并不意味着走到叶子结点,因为可能后几个物品都不装入背包。我们可以设想这样一种情况就是,已经找到了一个最优解,是一种最后几个物品不装入的情况,物品不装入就一定不会更新最优解的值,如果不加等号的话,就没法生成右孩子结点,那么就无法得到这个解了,这样就很可能会出错。
代码实现
队列式分支限界法
#include
#include
#include
using namespace std;
const int maxn=10;
struct node
{
int cv,lv;//当前价值,剩余价值
int lw;//剩余容量
int id;//物品序号
int x[maxn];//解向量
node()
{
memset(x,0,sizeof(x));
}
node(int cvv,int lvv,int lww,int idd)//有参构造函数
{
memset(x,0,sizeof(x));
cv=cvv;
lv=lvv;
lw=lww;
id=idd;
}
};//结点结构体
int n,W;//物品种数,背包容量
int w[maxn],v[maxn];//重量和价值
int bestx[maxn];//最优解
int bestv;//最优价值
void init()
{
memset(w,0,sizeof(w));
memset(v,0,sizeof(v));
memset(bestx,0,sizeof(bestx));
bestv=0;
}
void bfs()
{
queue q;
int sumv=0;
int i;
for(i=1; i<=n; ++i)
sumv+=v[i];
q.push(node(0,sumv,W,1));
while(!q.empty())
{
node live;
live=q.front();
q.pop();
int t=live.id;//当前处理物品的序号
if(t>n||live.lw==0)//到达叶子结点或者没有容量了
{
if(live.cv>=bestv)//更新最优解,不加等号的话,第一次计算得到的值不会更新
{
for(int i=1; i<=n; ++i)
bestx[i]=live.x[i];
bestv=live.cv;
}
continue;
}
if(live.cv+live.lv=w[t])//满足约束条件,可以生成左孩子
{
node lchild(live.cv+v[t],live.lv-v[t],live.lw-w[t],t+1);
for(int i=1; i<=n; ++i)
lchild.x[i]=live.x[i];
lchild.x[t]=1;
if(lchild.cv>bestv)//注意要更新最优值
bestv=lchild.cv;
q.push(lchild);
}
if(live.cv+live.lv-v[t]>=bestv)//满足限界条件,可以生成右孩子
{
node rchild(live.cv,live.lv-v[t],live.lw,t+1);
for(int i=1; i<=n; ++i)
rchild.x[i]=live.x[i];
rchild.x[t]=0;
q.push(rchild);
}
}
}
void output()
{
cout<<"可装载物品的最大价值为:"<>n;
cout<<"请输入背包容量:";
cin>>W;
cout<<"请依次输入物品的重量和价值:";
for(int i=1; i<=n; ++i)
cin>>w[i]>>v[i];
bfs();
output();
return 0;
}
优先队列式分支限界法
顾名思义,是用优先队列(最大堆)来存储活结点表,活结点的优先级由当前价值+剩余物品至能把背包装满的最大价值(假设物品可以分割)决定,就是说在一种情况下,往背包里继续装,假设物品可分割,直至装满,这时的总价值高,那么这种情况的结点就靠前。进一步优化呢,就是尽可能保证后续装物品是先捡着价值重量比高的装,这样我们就可以先将物品按单位重量的价值从高到低排序,然后再进行BFS(广度优先搜索)。
#include
#include
#include
#include
using namespace std;
const int maxn=10;
struct object//物品结构体
{
double w;//重量
double v;//价值
double d;//单位重量的价值(价值重量比)
int id;//物品序号
} a[maxn];
int n,W;//物品种数,背包容量
int bestx[maxn];//最优解
int bestv;//最优价值
bool tmp1(object b1,object b2)//物品优先级,以单位价值高的优先
{
return b1.d>b2.d;
}
void init()//初始化
{
memset(bestx,0,sizeof(bestx));
bestv=0;
sort(a+1,a+n+1,tmp1);
}
struct node//结点结构体
{
double cv,lv;//当前价值,价值上界(注意类型)
int lw;//剩余容量
int id;//物品排序后的序号
int x[maxn];//解向量
node()
{
memset(x,0,sizeof(x));
lv=0;
}
node(int cvv,int lvv,int lww,int idd)//构造函数
{
memset(x,0,sizeof(x));
cv=cvv;
lv=lvv;
lw=lww;
id=idd;
}
};
struct tmp2//结点优先级,价值上界高的优先级高
{
bool operator() (node& n1,node& n2)
{
return n1.lv=a[num].w)
{
left-=a[num].w;
maxvalue+=a[num].v;
++num;
}
if(num<=n&&left>0)//一定要加下标限制
maxvalue+=1.0*a[num].v/a[num].w*left;
return maxvalue;
}
void bfs()
{
priority_queue,tmp2> q;
int sumv=0;
int i;
for(i=1; i<=n; ++i)
sumv+=a[i].v;
q.push(node(0,sumv,W,1));//放入根结点
while(!q.empty())
{
node live,lchild,rchild;
live=q.top();
q.pop();
int t=live.id;//当前处理物品的序号
if(t>n||live.lw==0)//到达叶子结点或者没有容量了
{
if(live.cv>=bestv)//更新最优解,不加等号的话,第一次计算得到的值不会更新
{
for(int i=1; i<=n; ++i)
bestx[i]=live.x[i];
bestv=live.cv;
}
continue;
}
if(live.lv=a[t].w)//满足约束条件,可以生成左孩子
{
lchild.cv=live.cv+a[t].v;
lchild.lw=live.lw-a[t].w;
lchild.id=t+1;
lchild.lv=CalInf(lchild);
for(int i=1; i<=n; ++i)
lchild.x[i]=live.x[i];
lchild.x[t]=1;
if(lchild.cv>bestv)//注意要更新最优值
bestv=lchild.cv;
q.push(lchild);
}
rchild.cv=live.cv;
rchild.lw=live.lw;
rchild.id=t+1;
rchild.lv=CalInf(rchild);
if(rchild.lv>=bestv)//满足限界条件,可以生成右孩子
{
for(int i=1; i<=n; ++i)
rchild.x[i]=live.x[i];
rchild.x[t]=0;
q.push(rchild);
}
}
}
void output()
{
cout<<"可装载物品的最大价值为:"<>n;
cout<<"请输入背包容量:";
cin>>W;
cout<<"请依次输入物品的重量和价值:";
for(int i=1; i<=n; ++i)
{
cin>>a[i].w>>a[i].v;
a[i].d=a[i].v/a[i].w;
a[i].id=i;
}
init();
bfs();
output();
return 0;
}
参考文献:《趣学算法》