2019独角兽企业重金招聘Python工程师标准>>> 

\
disclaimer: 本文所讲的设计,非UI/UE的设计,单单指软件代码/功能本身在技术上的设计。UI/UE的主题请出门右转找特赞(Tezign)。
在如今这个Lean/Agile横扫一切的年代,设计似乎有了被边缘化的倾向,做事的周期如此之快,似乎已容不下人们更多的思考。MVP(Minimal Viable Produce)在很多团队里演化成一个形而上的图腾,于是工程师们找到了一个完美的借口:我先做个MVP,设计的事,以后再说。
如果纯属个人玩票,有个点子,hack out还说得过去;但要严肃做一个项目,还是要下工夫设计一番,否则,没完没了的返工会让你无语泪千行。
设计首先得搞懂要解决的问题
工程师大多都是很聪明的人,聪明人有个最大的问题就是自负。很多人拿到一个需求,还没太搞明白其外延和内涵,代码就已经在脑袋里流转。这样做出来的系统,纵使再精妙,也免不了承受因需求理解不明确而导致的返工之苦。
搞懂需求这事,说起来简单,做起来难。需求有正确的但表达错误的需求,有正确的但没表达出来的需求,还有过度表达的需求。所以,拿到需求后,先不忙寻找解决方案,多问问自己,工作伙伴,客户follow up questions来澄清需求模糊不清之处。
搞懂需求,还需要了解需求对应的产品,公司,以及(潜在)竞争对手的现状,需求的上下文,以及需求的约束条件。人有二知二不知:
I know that I know
I know that I don’t know
I don’t know that I know
I don’t know that I don’t know
澄清需求的过程,就是不断驱逐无知,掌握现状,上下文和约束条件的过程。
这个主题讲起来很大,且非常重要,但毕竟不是本文的重点,所以就此带过。
寻找(多个)解决方案
如果对问题已经有不错的把握,接下来就是解决方案的发现之旅。这是个考察big picture的活计。同样是满足孩子想要个汽车的愿望,你可以:
去玩具店里买一个现成的
买乐高积木,然后组装
用纸糊一个,或者找块木头,刻一个
这对应软件工程问题的几种解决之道:
购买现成软件(acuquire or licensing),二次开发之(如果需要)
寻找building blocks,组装之(glue)
自己开发(build from scratch, or DIY)
大部分时候,如果a或b的TCO [1] 合理,那就不要选择c。做一个产品的目的是为客户提供某种服务,而不是证明自己能一行行码出出来这个产品。
a是个很重要的点,可惜大部分工程师脑袋里没有钱的概念,或者出于job security的私心,而忽略了。工程师现在越来越贵,能用合理的价格搞定的功能,就不该雇人去打理(自己打脸)。一个产品,最核心的部分不超过整个系统的20%,把人力资源铺在核心的部分,才是软件设计之道。
b我们稍后再讲。
对工程师而言,DIY出一个功能是个极大的诱惑。一种DIY是源自工程师的不满。任何开源软件,在处理某种特定业务逻辑的时候总会有一些不足,眼里如果把这些不足放在,却忽略了人家的好处,是大大的不妥。前两天我听到有人说 “consul sucks, …, I’ll build our own service discovery framework…”,我就苦笑。我相信他能做出来一个简单的service discovery tool,这不是件特别困难的事情。问题是值不值得去做。如果连处于consul这个层次的基础组件都要自己去做,那要么是心太大,要么是没有定义好自己的软件系统的核心价值(除非系统的核心价值就在于此)。代码一旦写出来,无论是5000行还是50行,都是需要有人去维护的,在系统的生命周期里,每一行自己写的代码都是一笔债务,需要定期不定期地偿还利息。
另外一种DIY是出于工程师的无知。「无知者无畏」在某些场合的效果是正向的,有利于打破陈规。但在软件开发上,还是知识和眼界越丰富越开阔越好。一个无知的工程师在面对某个问题时(比如说service discovery),如果不知道这问题也许有现成的解决方案(consul),自己铆足了劲写一个,大半会有失偏颇(比如说没做上游服务的health check,或者自己本身的high availability),结果bug不断,辛辛苦苦一个个都啃下来,才发现,自己走了很多弯路,费了大半天劲,做了某个开源软件的功能的子集。当然,对工程师而言,这个练手的价值还是很大的,但对公司来说,这是一笔沉重的无意义的支出。
眼界定义了一个人的高度,如果你每天见同类的人,看同质的书籍/视频,(读)写隶属同一domain的代码,那多半眼界不够开阔。互联网的发展一日千里,变化太快,如果把自己禁锢在一方小天地里,很容易成为陶渊明笔下的桃花源中人:乃不知有汉,无论魏晋。
构建灵活且有韧性的系统
如果说之前说的都是废话,那么接下来的和真正的软件设计能扯上些关系。
分解和组合
软件设计是一个把大的问题不断分解,直至原子级的小问题,然后再不断组合的过程。这一点可以类比生物学:原子(keyword/macro)组合成分子(function),分子组合成细胞(module/class),细胞组合成组织(micro service),组织组合成器官(service),进而组合成生物(system)。
一个如此组合而成系统,是满足关注点分离(Separation of Concerns)的。大到一个器官,小到一个细胞,都各司其职,把自己要做的事情做到极致。心脏不必关心肾脏会干什么,它只需要做好自己的事情:把新鲜血液通过动脉排出,再把各个器官用过的血液从静脉回收。
分解和组合在软件设计中的作用如此重要,以至于一个系统如果合理分解,那么日后维护的代价就要小得多。同样讲关注点分离,不同的工程师,分离的方式可能完全不同。但究其根本,还有有一些规律可循。
总线(System Bus)
首先我们要把系统的总线定义出来。人体的总线,大的有几条:血管(动脉,静脉),神经网络,气管,输尿管。它们有的完全负责与外界的交互(气管,输尿管),有的完全是内部的信息中枢(血管),有的内外兼修(神经网络)。
总线把生产者和消费者分离,让彼此互不依赖。心脏往外供血时,把血压入动脉血管就是了。它并不需要知道谁是接收者。
同样的,回到我们熟悉的计算机系统,CPU访问内存也是如此:它发送一条消息给总线,总线通知RAM读取数据,然后RAM把数据返回给总线,CPU再获取之。整个过程中CPU只知道一个内存地址,毋须知道访问的具体是哪个内存槽的哪块内存 —— 总线将二者屏蔽开。
学过计算机系统的同学应该都知道,经典的PC结构有几种总线:数据总线,地址总线,控制总线,扩展总线等;做过网络设备的同学也都知道,一个经典的网络设备,其软件系统的总线分为:control plane和data plane。
路由(routing)
有了总线的概念,接下来必然要有路由。我们看人体的血管:
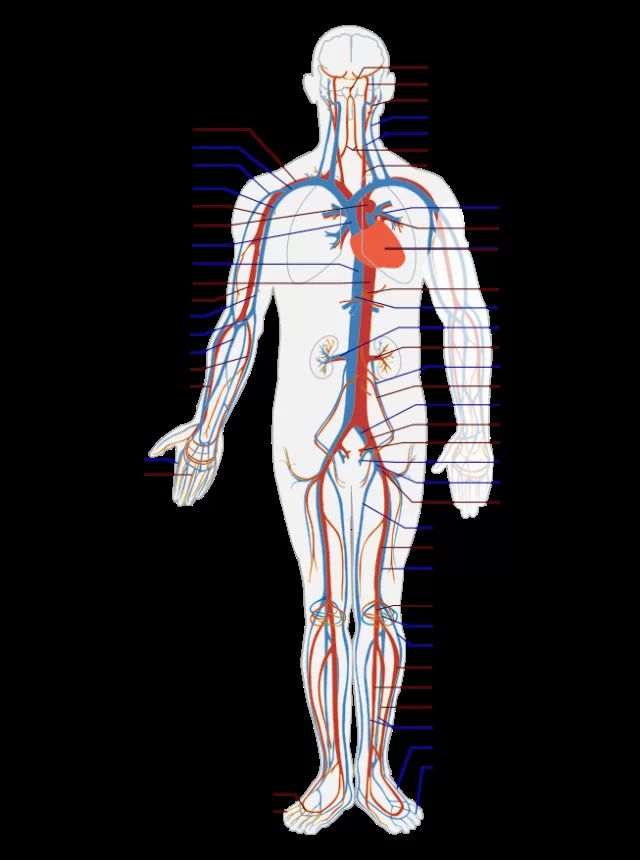
每一处分叉,就涉及到一次路由。
路由分为外部路由和内部路由。外部路由处理输入,把不同的输入dispatch到系统里不同的组件。做web app的,可能没有意识到,但其实每个web framework,最关键的组件之一就是url dispatch。HTTP的伟大之处就是每个request,都能通过url被dispatch到不同的handler处理。而url是目录式的,可以层层演进 —— 就像分形几何,一个大的系统,通过不断重复的模式,组合起来 —— 非常利于系统的扩展。遗憾的是,我们自己做系统,对于输入既没有总线的考量,又无路由的概念,if-else下去,久而久之,代码便绕成了意大利面条。
再举一例:DOM中的event bubble,在javascript处理起来已然隐含着路由的概念。你只需定义当某个事件(如onclick)发生时的callback函数就好,至于这事件怎么通过eventloop抵达回调函数,无需关心。好的路由系统剥茧抽丝,把繁杂的信息流正确送到处理者手中。
外部路由总还有「底层」为我们完成,内部路由则需工程师考虑。service级别的路由(数据流由哪个service处理)可以用consul等service discovery组件,service内部的路由(数据流到达后怎么处理)则需要自己完成。路由的具体方式有很多种,pattern matching最为常见。
无论用何种方式路由,数据抵达总线前为其定义Identity(ID)非常重要,你可以管这个过程叫data normalization,data encapsulation等,总之,一个消息能被路由,需要有个用于路由的ID。这ID可以是url,可以是一个message header,也可以是一个label(想象MPLS的情况)。当我们为数据赋予一个个合理的ID后,如何路由便清晰可见。
队列(Queue)
对于那些并非需要立即处理的数据,可以使用队列。队列也有把生产者和消费者分离的功效。队列有:
single producer single consumer(SPSC)
single producer multiple consumers(SPMC)
multiple producers single consumer(MPSC)
multiple producers multiple consumers(MPMC)
仔细想想,队列其实就是总线+路由(可选)+存储的一个特殊版本。一般而言,system bus之上是系统的各个service,每个service再用service bus(或者queue)把micro service chain起来,然后每个micro service内部的组件间,再用queue连接起来。
有了队列,有利于提高流水线的效率。一般而言,流水线的处理速度取决于最慢的组件。队列的存在,让慢速组件有机会运行多份,来弥补生产者和消费者速度上的差距。
Pub/Sub
存储在队列中的数据,除路由外,还有一种处理方式:pub/sub。和路由相似,pub/sub将生产者和消费者分离;但二者不同之处在于,路由的目的地由路由表中的表项控制,而pub/sub一般由publisher控制 [2]:任何subscribe某个数据的consumer,都会到publisher处注册,publisher由此可以定向发送消息。
协议(protocol)
一旦我们把系统分解成一个个service,service再分解成micro service,彼此之间互不依赖,仅仅通过总线或者队列来通讯,那么,我们就需要协议来定义彼此的行为。协议听起来很高大上,其实不然。我们写下的每个function(或者每个class),其实就是在定义一个不成文的协议:function的arity是什么,接受什么参数,返回什么结果。调用者需严格按照协议调用方能得到正确的结果。
service级别的协议是一份SLA:服务的endpoint是什么,版本是什么,接收什么格式的消息,返回什么格式的消息,消息在何种网络协议上承载,需要什么样的authorization,可以正常服务的最大吞吐量(throughput)是什么,在什么情况下会触发throttling等等。
头脑中有了总线,路由,队列,协议等这些在computer science 101中介绍的基础概念,系统的分解便有迹可寻:面对一个系统的设计,你要做的不再是一道作文题,而是一道填空题:在若干条system bus里填上其名称和流进流出的数据,在system bus之上的一个个方框里填上服务的名称和服务的功能。然后,每个服务再以此类推,直到感觉毋须再细化为止。
组成系统的必要服务
有些管理性质的服务,尽管和业务逻辑直接关系不大,但无论是任何系统,都需要考虑构建,这里罗列一二。
代谢(sweeping)
一个活着的生物时时刻刻都进行着新陈代谢:每时每刻新的细胞取代老的细胞,同时身体中的「垃圾」通过排泄系统排出体外。一个运转有序的城市也有新陈代谢:下水道,垃圾场,污水处理等维持城市的正常功能。没有了代谢功能,生物会凋零,城市会荒芜。
软件系统也是如此。日志会把硬盘写满,软件会失常,硬件会失效,网络会拥塞等等。一个好的软件系统需要一个好的代谢系统:出现异常的服务会被关闭,同样的服务会被重新启动,恢复运行。
代谢系统可以参考erlang的supervisor/child process结构,以及supervision tree。很多软件,都运行在简单的supervision tree模式下,如nginx。
高可用性(HA)
每个人都有两个肾。为了apple watch卖掉一个肾,另一个还能保证人体的正常工作。当然,人的两个肾是Active-Active工作模式,内部的肾元(micro service)是 N(active)+M(backup) clustering 工作的(看看人家这service的做的),少了一个,performance会一点点有折扣,但可以忽略不计。
大部分软件系统里的各种服务也需要高可用性:除非完全无状态的服务,且服务重启时间在ms级。服务的高可用性和路由是息息相关的:高可用性往往意味着同一服务的冗余,同时也意味着负载分担。好的路由系统(如consul)能够对路由至同一服务的数据在多个冗余服务间进行负载分担,同时在检测出某个失效服务后,将数据路只由至正常运作的服务。
高可用性还意味着非关键服务,即便不可恢复,也只会导致系统降级,而不会让整个系统无法访问。就像壁虎的尾巴断了不妨碍壁虎逃命,人摔伤了手臂还能吃饭一样,一个软件系统里统计模块的异常不该让用户无法访问他的个人页面。
安保(security)
安保服务分为主动安全和被动安全。authentication/authorization + TLS + 敏感信息加密 + 最小化输入输出接口可以算是主动安全,防火墙等安防系统则是被动安全。
继续拿你的肾来比拟 —— 肾脏起码有两大安全系统:
输入安全。肾器的厚厚的器官膜,保护器官的输入输出安全 —— 主要的输入输出只能是肾动脉,肾静脉和输尿管。
环境安全。肾器里有大量脂肪填充,避免在撞击时对核心功能的损伤。
除此之外,人体还提供了包括免疫系统,皮肤,骨骼,空腔等一系列安全系统,从各个维度最大程度保护一个器官的正常运作。如果我们仔细研究生物,就会发现,安保是个一揽子解决方案:小到细胞,大到整个人体,都有各自的安全措施。一个软件系统也需如此考虑系统中各个层次的安全。
透支保护(overdraft protection)
任何系统,任何服务都是有服务能力的 —— 当这能力被透支时,需要一定的应急计划。如果使用拥有auto scaling的云服务(如AWS),动态扩容是最好的解决之道,但受限于所用的解决方案,它并非万灵药,AWS的auto scaling依赖于load balancer,如Amazon自有的ELB,或者第三方的HAProxy,但ELB对某些业务,如websocket,支持不佳;而第三方的load balancer,则需要考虑部署,与Amazon的auto scaling结合(需要写点代码),避免单点故障,保证自身的capacity等一堆头疼事。
在无法auto scaling的场景最通用的做法是back pressure,把压力反馈到源头。就好像你不断熬夜,最后大脑受不了,逼着你睡觉一样。还有一种做法是服务降级,停掉非核心的service/micro-service,如analytical service,ad service,保证核心功能正常。
把设计的成果讲给别人听
完成了分解和组合,也严肃对待了诸多与业务没有直接关系,但又不得不做的必要功能后,接下来就是要把设计在白板上画下来,讲给任何一个利益相关者听。听他们的反馈。设计不是一个闭门造车的过程,全程都需要和各种利益相关者交流。然而,很多人都忽视了设计定型后,继续和外界交流的必要性。很多人会认为:我的软件架构,设计结果和工程有关,为何要讲给工程师以外的人听?他们懂么?
其实pitch本身就是自我学习和自我修正的一部分。当着一个人或者几个人的面,在白板上画下脑海中的设计的那一刻,你就会有直觉哪个地方似乎有问题,这是很奇特的一种体验:你自己画给自己看并不会产生这种直觉。这大概是面对公众的焦灼产生的肾上腺素的效果。:)
此外,从听者的表情,或者他们提的听起来很傻很天真的问题,你会进一步知道哪些地方你以为你搞通了,其实自己是一知半解。太简单,太基础的问题,我们take it for granted,不屑去问自己,非要有人点出,自己才发现:啊,原来这里我也不懂哈。这就是破解 “you don’t know what you don’t know” 之法。
记得看过一个video,主讲人大谈企业文化,有个哥们傻乎乎发问:so what it culture literally? 主讲人愣了一下,拖拖拉拉讲了一堆自己都不能让自己信服的废话。估计回头他就去查韦氏词典了。
最后,总有人在某些领域的知识更丰富一些,他们会告诉你你一些你知道自己不懂的事情。填补了 “you know that you don’t know” 的空缺。
设计时的tradeoff
Rich hickey(clojure作者)在某个演讲中说:
everyone says design is about tradeoffs, but you need to enumerate at least two or more possible solutions, and the attributes and deficits of each, in order to make tradeoff.
所以,下回再腆着脸说:偶做了些tradeoff,先确保自己做足了功课再说。
设计的改变不可避免
设计不是一锤子买卖,改变不可避免。我之前的一个老板,喜欢把 change is your friend 挂在口头。软件开发的整个生命周期,变更是家常便饭,以至于变更管理都生出一门学问。软件的设计期更是如此。人总会犯错,设计总有缺陷,需求总会变化,老板总会指手画脚,PM总有一天会亮出獠牙,不再是贴心大哥,或者美萌小妹。。。所以,据理力争,然后接受必要的改变即可。连凯恩斯他老人家都说:
