MPEG音频编码 基本原理和C语言代码分析
背景
MPEG(Moving Picture Experts Group)在汉语中译为活动图像专家组,特指活动影音压缩标准。
MPEG 音频文件是MPEG1 标准中的声音部分,也叫MPEG 音频层,它根据压缩质量和编码复杂程度划分为三层,即 Layer-1、Layer2、Layer3,且分别对应MP1、MP2、MP3 这三种声音文件,并根据不同的用途,使用不同层 次的编码。MPEG音频编码的层次越高,编码器越复杂,压缩率也越高,MP1 和MP2 的压缩率分别为4:1 和 6:1-8:1,而MP3 的压缩率则高达10:1-12:1。
本次实验针对Layer2,即编码生成mp2音频文件。
心理声学模型
频域掩蔽效应
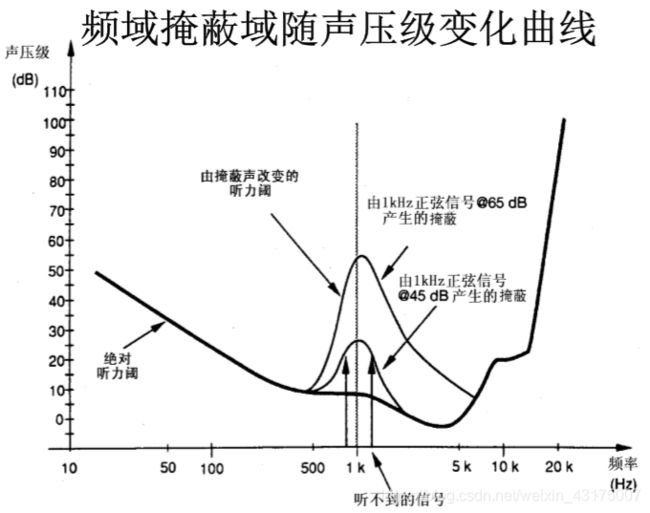
一个强纯音会掩蔽在其频域上附近同时发声的弱纯音,这称为频域掩蔽。
由上图可知,不同频率的音频信号会产生不同的掩蔽效应曲线,当另一个声音在这条掩蔽曲线下方时,会被这个音频信号掩盖,人耳无法听到。
当没有多种声音同时存在,人耳也不能完全得到声音信息。人耳对不同频率的声音有不同的绝对听力阈值(也称静听阈),可以理解为对不同频率声音的敏感度不同。
因此我们可以对即将编码的音频信号作以下处理:
- **对被掩蔽的信号分量进行去除。**因为不会被听见。
- **对被掩蔽的量化噪声不予理会。**只要保证量化后噪声在同听阈以下即可。
时域掩蔽效应
除了频域掩蔽,时间上相邻的声音也会有掩蔽现象,即一个时域上强音对附近的其他弱音有掩蔽效应。分为超前掩蔽和滞后掩蔽。
超前掩蔽很短,约为5-20ms,滞后掩蔽有20-200ms。
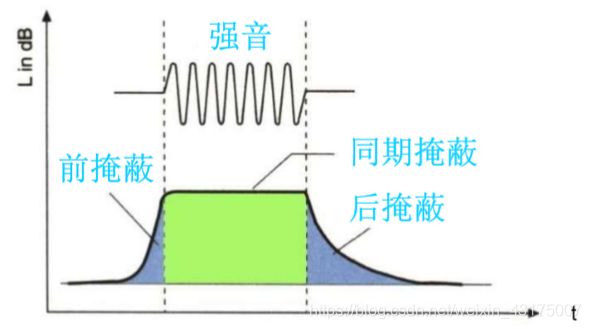
根据时域掩蔽,对同一子带的中相邻的三个比例因子,可以选择丢弃其中较小的因子以减少传输用的比特数。
具体过程将在下面的内容中解释。
临界频带
人耳的听觉系统可以等效为一个0-20kHz由25个重叠的带通滤波器组成的带通滤波器组。
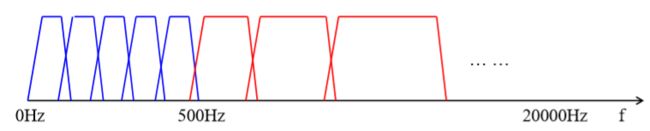
这些频带是临界频带(critical band),单位为巴克(Bark)。注意每个临界频带并不是等带宽的。
临界频带具体定义为:指当某个纯音被以它为中心频率、且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好 被听到时的功率等于这一频带内的噪声功率,这个带宽为临界频带宽度。
我们一般认为20Hz-16kHz有25个临界频带。**人耳不能区分同一频带内发生的不同声音,且只有同一频带内的噪声才能对该频带内的声音信号有干扰,掩蔽等效果。**1bark为一个临界频带的宽度。
1 b a r k = { f 100 f < 500 H z 13 t a n − 1 ( 0.76 f 1000 ) + 3.5 t a n − 1 ( f 7500 ) 2 f ≥ 500 H z 1 \quad bark=\begin{cases}\frac{f}{100}&f<500Hz\\13tan^{-1}(\frac{0.76f}{1000})+3.5tan^{-1}(\frac{f}{7500})^2&f\geq500Hz\end{cases} 1bark={ 100f13tan−1(10000.76f)+3.5tan−1(7500f)2f<500Hzf≥500Hz
MPEG Layer2 中的心理声学模型
在代码实现中提供了两种心理声学模型:
- 心理声学模型1:计算复杂度较低,但对可能听不到的部分压缩很严重。
- 心理声学模型2:提供了适合Layer3的更多特征。
在模型1中,经过多项滤波器后采用了Hanning加窗的办法减小了边界效应,Layer2采用了1024点FFT变换来达到更精细的频率分辨力以适应心理声学模型的需求(Layer中为512点)。
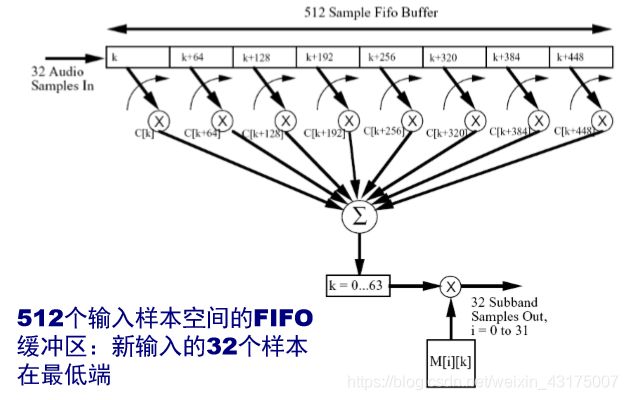
多项滤波器组
在MPEG音频编码中,音频信号压缩编码采用了子带编码SBC(sub-band coding)的方法。
有以下好处:
- 对每个自带分别进行自适应控制,量化阶可以按照每个子带的能量电平加以调节。
- 根据每个自带在感觉上的重要性,对每个自带分配不同的位数,即动态比特分配。
会在后面内容中进行解释。
在Layer2中,输入信号以帧为单位。一帧样本分为了32个子带,每个子带12个块,每个块3个样本值,即总样本32 * 12 * 3 = 1152。抽样频率为48kHz时,一个音频帧长为24ms。
要达到子带分解的目的,对输入的PCM样本的第一步处理就是用多项滤波器进行处理,变为32个子带的频域信号。如下图所示
不过这里要注意,各等宽子带并不能和人耳听觉中的临界频带一一对应起来:
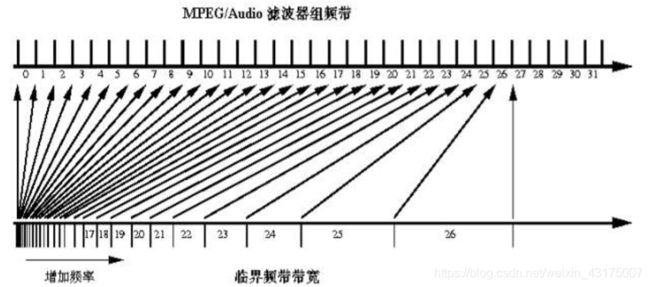
此外,多项滤波器组子带间频率有一定混叠,且它和它的逆过程不是无失真的,只是误差非常小,基本察觉不到。
MPEG1Layer2音频编码器
系统框图如下:
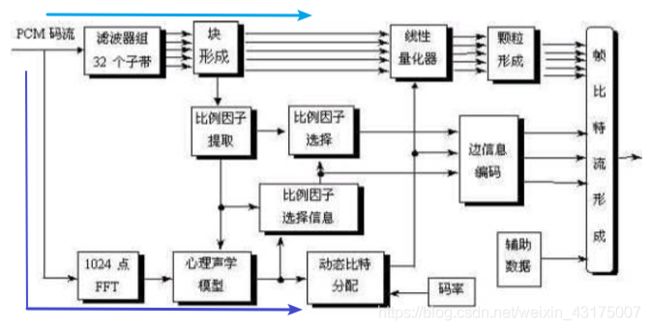
根据实验要求注意几个问题:
两条线
如图所示,输入信号分两条线分别进行处理,分别起到了不同作用。
第一路经过多项滤波器组变为32个子带信号,形成块,提取比例因子,然后输入到量化器根据动态比特分配确定的量化阶数进行量化,最后形成帧比特流输出。
第二路则直接进行FFT,FFT的目的是使信号具有高频率分辨力,使符合心理声学模型的要求。经过心理声学模型后确定动态比特分配和比例因子选择信息(SCFSI,即三个比例因子是否全部传输)。最后相关信息进行边信息编码,一起封装成帧比特流进行传输,从而接收端可以顺利解码。
时频分析矛盾
根据之前信号与系统,数字信号处理课程中学习的知识,要提高频域的分辨力,必然会对时域分辨力油馊限制,反之亦然。可以看出视频分析的矛盾无法解决,我们所能做的就是在两者之间选择一个综合效果最好的折中方案。
接下来对一些重点步骤进行简单陈述,具体过程将结合代码分析:
比例因子(SCF)提取和选择
首先要对每一个块提取三个比例因子,提取方法为查表法。在程序中直接设置好相关比例因子系数,直接插标读取即可。
比例因子的选择,即决定三个比例因子是否要全部传输。当三个比例因子变化很小时,往往只会传送最大的一个比特因子。在具体实现过程中,有许多不同的比例因子选择模型。每个子带的比例因子选择信息长2bit。
比特分配,量化,编码
比特分配首先要计算各子带的掩蔽噪声比MNR。掩蔽噪声比等于信噪比减信掩比。
M N R = S N R − S M R MNR=SNR-SMR MNR=SNR−SMR
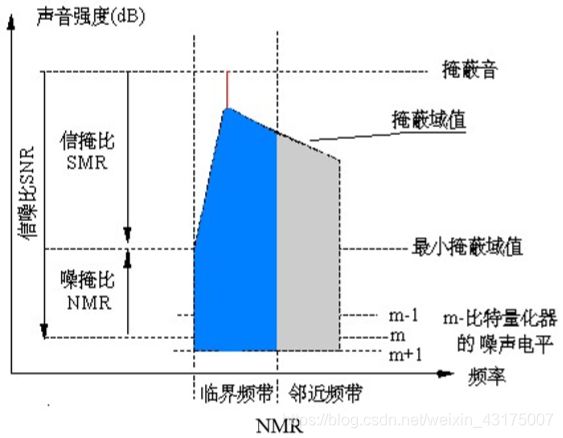
总的原则是使音频帧期间总掩蔽噪声比达到最小。为此,要使量化信噪比SMR>最小掩蔽比SMR。
具体实现流程为循环算法:
每次循环计算NMR为最高NMR的子带分配1比特,即使获益最大子带的量化级别增加1级。
分配结束后,一些高频子带比特数量可能为0.
最后根据各子带分配的比特数量,即量化阶数,对子带样本进行量化编码。
在Layer1中,对样本先除以比例因子得到X,量化表达式为
A X + B AX+B AX+B
A,B均为量化系数,可以通过查表得到。

Layer2在Layer1的基础上进行改进,对量化级别在3,5,9的样本采用颗粒量化。
改进后压缩比可从4:1提高到6:1-8:1。
程序整体框架
main函数很长,结合上述原理分步骤进行解析。解析过程中适当介绍较为细节的过程原理。
初始化缓存,变量定义声明部分,读取输入音频文件信息等部分略过。
1.子带滤波
首先对滑动窗口内的音频样本进行32子带滤波。
...定义声明,读取输入音频信息等代码...
while (get_audio (musicin, buffer, num_samples, nch, &header) > 0) {
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf (stderr, "[%4u]\r", frameNum);
fflush (stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits (&header, &glopts);//number of available bits
lg_frame = adb / 8;
if (header.dab_extension) {
/* in 24 kHz we always have 4 bytes */
if (header.sampling_frequency == 1)
header.dab_extension = 4;
/* You must have one frame in memory if you are in DAB mode */
/* in conformity of the norme ETS 300 401 http://www.etsi.org */
/* see bitstream.c */
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
/* New polyphase filter
Combines windowing and filtering. Ricardo Feb'03 */
for( gr = 0; gr < 3; gr++ )
for ( bl = 0; bl < 12; bl++ )
for ( ch = 0; ch < nch; ch++ )//Layer 2 3*12*32
WindowFilterSubband( &buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0] );//sb_xample存储子带数据
}
...后续的单帧处理代码...
}
musicin存储输入的音频信号,buffer即为滑动窗口,通过一个很大的循环每次输出一帧样本存储到了sb_sample中。这里要注意的是,如果输入的是双通道音频信息,即一帧的样本数其实为3 * 12 * 32 * 2,nch存储的即为通道数,默认为2。后续会将最有通道合为一个通道 后进行后续处理。
后续的处理都在这个逐帧读取的大循环中。
2.双通道合并,选取比例因子,计算选择信息
...
#else
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);//计算比例因子scalar
pick_scale (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);//各个子带左右声道结合,结合后的为j_sample
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);//计算比例因子j_scale
}
#endif
...
这部分代码计算了子带的比例因子scalar,双通道的情况下则讲左右声道合并后(j_sample)计算比例因子j_scale。
计算比例因子的函数scale_factor_calc的原理很简单,即查表法,在此不展开细说。
3.选定心理声学模型,计算SMR
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
//quickmode不计算心理声学模型
/* We're using quick mode, so we're only calculating the model every
'quickcount' frames. Otherwise, just copy the old ones across */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
} else {
/* calculate the psymodel */
switch (model) {
case -1:
psycho_n1 (smr, nch);
break;
case 0: /* Psy Model A */
psycho_0 (smr, nch, scalar, (FLOAT) s_freq[header.version][header.sampling_frequency] * 1000);
break;
case 1:
psycho_1 (buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
/* Modified psy model 1 */
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
/* Modified Psycho Model 2 */
for (ch = 0; ch < nch; ch++) {
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
/* Model 5 comparse model 1 and 3 */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1 ");
smr_dump(smr,nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3 ");
smr_dump(smr,nch);
break;
case 6:
/* Model 6 compares model 2 and 4 */
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2 ");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4 ");
smr_dump(smr,nch);
break;
case 7:
fprintf(stdout,"Frame: %i\n",frameNum);
/* Dump the SMRs for all models */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1");
smr_dump(smr, nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1 (smr, nch);
fprintf(stdout,"0");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
default:
fprintf (stderr, "Invalid psy model specification: %i\n", model);
exit (0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
这一部分代码准备了许多可供选择的SMR计算模型,以变量model为依据选择.有普通的心理声学模型,改进的心理声学模型,两个心理声学模型结合等,最终目的都是得出SMR,缓存区为smr.
这部分计算SMR的代码很重要,下文中将以程序默认的model=1的情况使用的函数psycho_1()为例说明SMR的计算过程.
4.根据SMR进行比特分配,比特选择
...
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
...
transmission_pattern()函数的作用是根据比例因子选择信息选择比例因子.
main_bit_allocation(双声道立体声)是根据计算得到的SMR进行子带比特分配.这部分代码很重要,将在下文进行详细分析.
5.CRC计算
if (error_protection)//置1说明有错误保护,计算CRC
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
根据具体需要可以选择是否计算CRC并进行编码.
6.量化编码
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);//量化
sample_encoding (*subband, bit_alloc, &frame, &bs);
比特分配后根据比例因子和比例因子选择信息对样本进行量化编码,基本原理已经在上文陈述,在此不展开细说.
7.封装成帧
......
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit (&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits (&bs, 0, header.dab_length * 8);
for (i = header.dab_extension - 1; i >= 0; i--) {
CRC_calcDAB (&frame, bit_alloc, scfsi, scalar, &crc, i);
/* this crc is for the previous frame in DAB mode */
if (bs.buf_byte_idx + lg_frame < bs.buf_size)
bs.buf[bs.buf_byte_idx + lg_frame] = crc;
/* reserved 2 bytes for F-PAD in DAB mode */
putbits (&bs, crc, 8);
}
putbits (&bs, 0, 16);
}//大循环结束
frameBits = sstell (&bs) - sentBits;
if (frameBits % 8) {
/* a program failure */
fprintf (stderr, "Sent %ld bits = %ld slots plus %ld\n", frameBits,
frameBits / 8, frameBits % 8);
fprintf (stderr, "If you are reading this, the program is broken\n");
fprintf (stderr, "email [mfc at NOTplanckenerg.com] without the NOT\n");
fprintf (stderr, "with the command line arguments and other info\n");
exit (0);
}
根据MPEG音频流的帧结构将相应数据打包输入比特流缓存bs,这部分也在大循环中进行.最后程序崩溃时命令行会输出信息进行提示,程序结束.
重要函数分析和原理解构
SMR的计算
//头文件中
typedef struct
{
int line;
double bark, hear, x;
}
g_thres, *g_ptr;
typedef struct
{
double x;
int type, next, map;
}
mask, *mask_ptr;
//
//
//psycho_1.c
void psycho_1 (short buffer[2][1152], double scale[2][SBLIMIT],
double ltmin[2][SBLIMIT], frame_info * frame)
{
frame_header *header = frame->header;
int nch = frame->nch;
int sblimit = frame->sblimit;
int k, i, tone = 0, noise = 0;
static char init = 0;
static int off[2] = {
256, 256 };
double sample[FFT_SIZE];
double spike[2][SBLIMIT];
static D1408 *fft_buf;
static mask_ptr power;
static g_ptr ltg;
FLOAT energy[FFT_SIZE];
/* call functions for critical boundaries, freq. */
if (!init) {
/* bands, bark values, and mapping */
fft_buf = (D1408 *) mem_alloc ((long) sizeof (D1408) * 2, "fft_buf");
power = (mask_ptr) mem_alloc (sizeof (mask) * HAN_SIZE, "power");
if (header->version == MPEG_AUDIO_ID) {
psycho_1_read_cbound (header->lay, header->sampling_frequency);//读取时域样本信息
psycho_1_read_freq_band (<g, header->lay, header->sampling_frequency);//临界频带信息
} else {
psycho_1_read_cbound (header->lay, header->sampling_frequency + 4);
psycho_1_read_freq_band (<g, header->lay, header->sampling_frequency + 4);
}
psycho_1_make_map (power, ltg);
for (i = 0; i < 1408; i++)
fft_buf[0][i] = fft_buf[1][i] = 0;
psycho_1_init_add_db (); /* create the add_db table */
init = 1;
}
for (k = 0; k < nch; k++) {
/* check pcm input for 3 blocks of 384 samples */
/* sami's speedup, added in 02j
saves about 4% overall during an encode */
int ok = off[k] % 1408;
for (i = 0; i < 1152; i++) {
fft_buf[k][ok++] = (double) buffer[k][i] / SCALE;
if (ok >= 1408)
ok = 0;
}
ok = (off[k] + 1216) % 1408;
for (i = 0; i < FFT_SIZE; i++) {
sample[i] = fft_buf[k][ok++];
if (ok >= 1408)
ok = 0;
}
off[k] += 1152;
off[k] %= 1408;
psycho_1_hann_fft_pickmax (sample, power, &spike[k][0], energy);//FFT,Hann加窗
psycho_1_tonal_label (power, &tone);//标记乐音
psycho_1_noise_label (power, &noise, ltg, energy);//标记噪音
//psycho_1_dump(power, &tone, &noise) ;//输出乐音噪音成分
psycho_1_subsampling (power, ltg, &tone, &noise);//去除静听阈以下的
psycho_1_threshold (power, ltg, &tone, &noise,
bitrate[header->version][header->bitrate_index] / nch);//计算单个掩蔽阈值和全局掩蔽阈值进行相应去除
psycho_1_minimum_mask (ltg, <min[k][0], sblimit);//子带掩蔽阈值
psycho_1_smr (<min[k][0], &spike[k][0], &scale[k][0], sblimit);//SMR计算,传递
}
}
这一部分很重要的一点是分出乐音(tone)和噪音(noise).全部流程如下:
1.转换到频域
要进行SMR计算首先要将样本从时域转换到频域.Layer2采用的是1024点的FFT.上述代码中, psycho_1_read_cbound()和psycho_1_read_freq_band先分别读取了时域上的样本和临界频带的信息.
为了减弱边界效应还要进行Hann加窗.同时实现FFT和Hann加窗的函数为psycho_1_hann_fft_pickmax().
2.确定声压级别
3.考虑绝对阈值
绝对阈值存储在ltg中,由psycho_1_make_map()函数产生.
4.分解乐音和噪音
乐音也可称为"有调成分",噪音也可称为"无调成分".可以区分两者的原理为两者的掩蔽能力不同.
代码中psycho_1_tonal_label()和psycho_1_noise_label()函数分别标记了乐音和噪音
由局部最大功率为依据进行分捷,以乐音标记函数psycho_1_tonal_label()为例,具体过程如下:
void psycho_1_tonal_label (mask power[HAN_SIZE], int *tone)
/* this function extracts (tonal) sinusoidals from the spectrum */
{
int i, j, last = LAST, first, run, last_but_one = LAST; /* dpwe */
double max;
*tone = LAST;
for (i = 2; i < HAN_SIZE - 12; i++) {
if (power[i].x > power[i - 1].x && power[i].x >= power[i + 1].x) {
//确定局部最大值
power[i].type = TONE;
power[i].next = LAST;
if (last != LAST)
power[last].next = i;
else
first = *tone = i;
last = i;
}
}
last = LAST;
first = *tone;
*tone = LAST;
while ((first != LAST) && (first != STOP)) {
/* the conditions for the tonal */
if (first < 3 || first > 500)
run = 0; /* otherwise k+/-j will be out of bounds */
else if (first < 63)
run = 2; /* components in layer II, which */
else if (first < 127)
run = 3; /* are the boundaries for calc. */
else if (first < 255)
run = 6; /* the tonal components */
else
run = 12;
max = power[first].x - 7; /* after calculation of tonal */
for (j = 2; j <= run; j++) /* components, set to local max */
if (max < power[first - j].x || max < power[first + j].x) {
//确定是否为可调成份 x(k)-x(k+j)>=7dB(所有情况都满足)即为可调成份
power[first].type = FALSE;
break;
}
if (power[first].type == TONE) {
/* extract tonal components 是乐音成分*/
int help = first;
if (*tone == LAST)
*tone = first;
while ((power[help].next != LAST) && (power[help].next - first) <= run)
help = power[help].next;
help = power[help].next;
power[first].next = help;
if ((first - last) <= run) {
if (last_but_one != LAST)
power[last_but_one].next = first;
}
if (first > 1 && first < 500) {
/* calculate the sum of the *///余留谱线功率相加
double tmp; /* powers of the components */
tmp = add_db (power[first - 1].x, power[first + 1].x);
power[first].x = add_db (power[first].x, tmp);
}
for (j = 1; j <= run; j++) {
power[first - j].x = power[first + j].x = DBMIN;
power[first - j].next = power[first + j].next = STOP;
power[first - j].type = power[first + j].type = FALSE;
}
last_but_one = last;
last = first;
first = power[first].next;
} else {
int ll;
if (last == LAST); /* *tone = power[first].next; dpwe */
else
power[last].next = power[first].next;
ll = first;
first = power[first].next;
power[ll].next = STOP;
}
}
}
- 标明局部最大。如果x(k)比相邻的两个谱线都大,则x(k)为局部最大值
- 列出有调成份,计算声压级。如果x(k)-x(k+j)>=7dB,则x(k)列为有调成份。j随谱线的位置不同。
- 列出无调成分,计算功率。在每个临界频带内将所有余留谱线的功率加起来形成临界频带内无调成分的声压级。并列出以下参数:最接近临界频带几何平均值的谱线标记k,声压级以及无调指示。
5.掩蔽成分消除
将绝对阈值以下的成分消除,在每个频带内只保留最高频率成分.代码中由psycho_1_subsampling()完成.
6.单个掩蔽阈值,全局掩蔽阈值计算
由psycho_1_threshold()完成.
6.子带掩蔽阈值计算
由psycho_1_minimum_mask ()完成.子带掩蔽阈值为ltmin.
7.计算SMR
根据所得的掩蔽阈值计算SMR,SMR=信号能量/掩蔽阈值,并传回编码单元,由psycho_1_smr()完成.
实际上函数结束后回传到编码单元的知识ltmin,但这也足够下一步进行比特分配等操作了.
码率分配
即比特分配.上述分析中,比特分配涉及到了main_bit_allocation()函数.
void main_bit_allocation (double perm_smr[2][SBLIMIT],
unsigned int scfsi[2][SBLIMIT],
unsigned int bit_alloc[2][SBLIMIT], int *adb,
frame_info * frame, options * glopts)
{
......
if ((mode = frame->actual_mode) == MPG_MD_JOINT_STEREO) {
frame->header->mode = MPG_MD_STEREO;
frame->header->mode_ext = 0;
frame->jsbound = frame->sblimit;
if ((rq_db = bits_for_nonoise (perm_smr, scfsi, frame)) > *adb) {
frame->header->mode = MPG_MD_JOINT_STEREO;
mode_ext = 4; /* 3 is least severe reduction */
lay = frame->header->lay;
do {
--mode_ext;
frame->jsbound = js_bound (mode_ext);
rq_db = bits_for_nonoise (perm_smr, scfsi, frame);
}
while ((rq_db > *adb) && (mode_ext > 0));
frame->header->mode_ext = mode_ext;
} /* well we either eliminated noisy sbs or mode_ext == 0 */
}
/* decide on which bit allocation method to use */
if (glopts->vbr == FALSE) {
/* Just do the old bit allocation method */
noisy_sbs = a_bit_allocation (perm_smr, scfsi, bit_alloc, adb, frame);
} else {
......
frame->header->bitrate_index = guessindex;
*adb = available_bits (frame->header, glopts);
......
}
一开始的一串代码和动态表比特率VBR有关,本次实验比特分配为固定码率,即old bit allocation method,与此无关,略过。其中主要作用的函数为a_bit_allocation()。
int a_bit_allocation (double perm_smr[2][SBLIMIT],
unsigned int scfsi[2][SBLIMIT],
unsigned int bit_alloc[2][SBLIMIT], int *adb,
frame_info * frame)
{
......
do {
count++;
/* locate the subband with minimum SMR */
maxmnr (mnr, used, sblimit, nch, &min_sb, &min_ch);
if (min_sb > -1) {
/* there was something to find */
/* find increase in bit allocation in subband [min] */
increment =
SCALE_BLOCK * ((*alloc)[min_sb][bit_alloc[min_ch][min_sb] + 1].group *
(*alloc)[min_sb][bit_alloc[min_ch][min_sb] + 1].bits);
if (used[min_ch][min_sb])
increment -=
SCALE_BLOCK * ((*alloc)[min_sb][bit_alloc[min_ch][min_sb]].group *
(*alloc)[min_sb][bit_alloc[min_ch][min_sb]].bits);
/* scale factor bits required for subband [min] */
oth_ch = 1 - min_ch; /* above js bound, need both chans */
if (used[min_ch][min_sb])
scale = seli = 0;
else {
/* this channel had no bits or scfs before */
seli = 2;
scale = 6 * sfsPerScfsi[scfsi[min_ch][min_sb]];
if (nch == 2 && min_sb >= jsbound) {
/* each new js sb has L+R scfsis */
seli += 2;
scale += 6 * sfsPerScfsi[scfsi[oth_ch][min_sb]];
}
}
/* check to see enough bits were available for */
/* increasing resolution in the minimum band */
if (ad >= bspl + bscf + bsel + seli + scale + increment) {
ba = ++bit_alloc[min_ch][min_sb]; /* next up alloc */
bspl += increment; /* bits for subband sample */
bscf += scale; /* bits for scale factor */
bsel += seli; /* bits for scfsi code */
used[min_ch][min_sb] = 1; /* subband has bits */
mnr[min_ch][min_sb] =
-perm_smr[min_ch][min_sb] + snr[(*alloc)[min_sb][ba].quant + 1];
/* Check if subband has been fully allocated max bits */
if (ba >= (1 << (*alloc)[min_sb][0].bits) - 1)
used[min_ch][min_sb] = 2; /* don't let this sb get any more bits */
} else
used[min_ch][min_sb] = 2; /* can't increase this alloc */
if (min_sb >= jsbound && nch == 2) {
/* above jsbound, alloc applies L+R */
ba = bit_alloc[oth_ch][min_sb] = bit_alloc[min_ch][min_sb];
used[oth_ch][min_sb] = used[min_ch][min_sb];
mnr[oth_ch][min_sb] =
-perm_smr[oth_ch][min_sb] + snr[(*alloc)[min_sb][ba].quant + 1];
}
}
}
while (min_sb > -1); /* until could find no channel */
/* Calculate the number of bits left */
ad -= bspl + bscf + bsel;
*adb = ad;
for (k = 0; k < nch; k++)
for (i = sblimit; i < SBLIMIT; i++)
bit_alloc[k][i] = 0;
return 0;
}
分配码率请安首先要确定各子带可用的比特数。这在之前main’函数中的相关调用已经实现了。
此函数的主要思路为:先找到子带的最小SMR,计算得到MNR。
通过do while 循环,每一次循环对MNR最高的子带加一个比特分配(变量bspl),同时判断是否超出可用比特数。
如此循环往复,完成比特分配(old bit allocation method)。
实验输出结果
音频采样率和目标码率
源代码已经有将音频采样率和目标码率输出命令行的代码。编译源程序即可得到,以上课时使用过的“关门.wav”为例输入,设置命令行参数为:
关门.wav 关门_output.mp2
得到如下输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dOvj1Z9Z-1591802782527)(E:\大三下\数据压缩\实验6_MPG音频编码\输出.png)]
特定帧的分配比特数,比例因子,比特分配结果
一个帧得数据就是一个大循环,因此可以在进入循环前打开文件,循环结束后关闭。设置一个判断是否要输出当前帧信息。根据之前的分析可知,输出的分配比特数为变量adb,比例因子为scalar,比特分配结果为bit_alloc。
添加代码如下:
int frameNum = 0;
int spec_frameNum = 1;//newly added 指定的帧数
int main (int argc, char **argv)
......
FILE* result;
result = fopen("output_result.txt", "w");
if (result == NULL){
printf("error opening txt file.");
system("pause");
exit(-1);}//newly added
if(frameNum == spec_frameNum)
fprintf (stderr, "[%4u]\r", frameNum);
while (get_audio (musicin, buffer, num_samples, nch, &header) > 0) {
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf (stderr, "[%4u]\r", frameNum);
fflush (stderr);
output = (frameNum == spec_frame);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits (&header, &glopts);//number of available bits
//输出可用比特数
if(output)
fprintf(result,"可用比特数:%d\n",adb);//newly added
......
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);//计算比例因子scalar
pick_scale (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);//各个子带左右声道结合,结合后的为j_sample
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);//计算比例因子j_scale
}
if (frameNum == spec_frameNum)
{
//输出比例因子
fprintf(result, "比例因子:\n");
for (int k = 0; k < nch; k++)//声道
{
fprintf(result, "声道:%d:\n", k + 1);
for (int i = 0; i < SBLIMIT; i++)//子带三个比例因子
{
fprintf(result, "子带:%d:\t", i);
for (int j = 0; j < 3; j++)
{
fprintf(result, "%d\t", scalar[k][j][i]);
}
fprintf(result, "\n");
}
}
}
......
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//输出比特分配结果
if (frameNum == spec_frameNum)
{
fprintf(result, "比特分配结果\n");
for (int k = 0; k < nch; k++)//声道
{
fprintf(result, "声道%d:\n", k + 1);
for (int i = 0; i < SBLIMIT; i++)//每个子带有一个比特分配结果
{
fprintf(result, "子带%d:\t", i);
fprintf(result, "%d\n", bit_alloc[k][i]);
}
}
}
......
fclose(result);
......
输出结果如下:
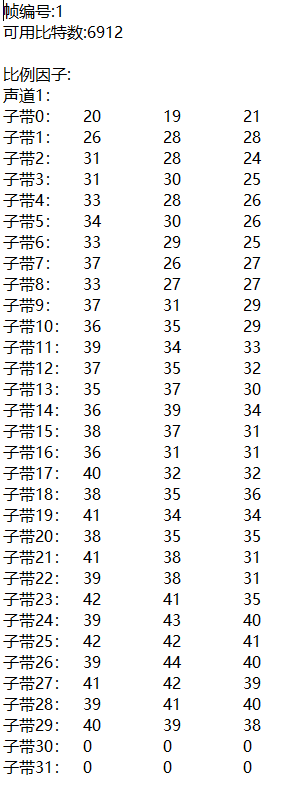

可以看到频带频率越高分配到的比特数越少,这与原理要达到的效果一致。