Zookeeper是Apache开源的一个分布式框架,它主要为分布式应用提供协调服务。
Zookeeper主要负责存储和管理大家都关心的数据,一旦这些数据的状态发生变化,Zookeeper就会通知那些注册在Zookeeper上的服务。简单来讲就是zookeeper=文件系统+通知机制。
一 Zookeeper的数据结构
Zookeeper的数据结构与Unix文件系统很类似,整体上可以看作是一棵树,与Unix文件系统不同的是Zookeeper的每个节点都可以存放数据,每个节点称作一个ZNode,默认存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
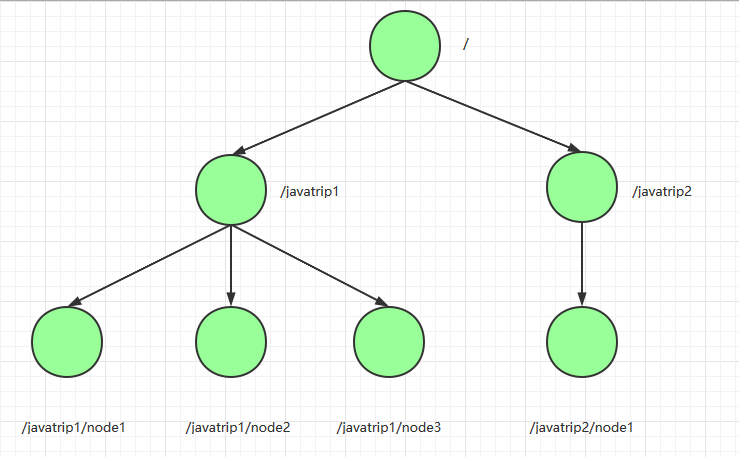
1.1 四种类型的ZNode
- 持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在。
- 持久化顺序编号目录节点:客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称就行顺序编号。
- 临时目录节点:客户端与Zookeeper断开连接后,该节点被删除。
- 临时顺序编号目录节点:客户端与Zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称就行顺序编号。
说明:创建ZNode时设置顺序标识,ZNode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。
1.2 stat结构体
ZNode主要包含以下信息:
- czxid-创建节点的事务 zxid:
每次修改 ZooKeeper 状态都会收到一个 zxid 形式的时间戳,也就是 ZooKeeper 事务 ID。
事务 ID 是 ZooKeeper 中所有修改总的次序。每个修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
-
ctime :znode 被创建的毫秒数(从 1970 年开始)
-
mzxid:znode 最后更新的事务 zxid
-
mtime:znode 最后修改的毫秒数(从 1970 年开始)
-
pZxid:znode 最后更新的子节点 zxid
-
cversion:znode 子节点变化号,znode 子节点修改次数
-
dataversion:znode 数据变化号
-
aclVersion:znode 访问控制列表的变化号
-
ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节
点则是 0
-
dataLength:znode 的数据长度
-
numChildren:znode 子节点数量
二 Zookeeper的应用场景
Zookeeper的主要应用场景有统一命名服务,统一配置管理,统一集群管理,服务器节点动态上下线等。
2.1 统一命名服务
在分布式环境中,经常需要对服务进行统一命名,假如有一个服务部署了2两个副本,直接调用具体的服务肯定有些不合适,因为我们并不清楚哪个服务可以更快的处理我们的请求,这时候我们可以将这三个服务进行统一命名,然后其内部再去负载。这样就可以调用最优的那个服务了。

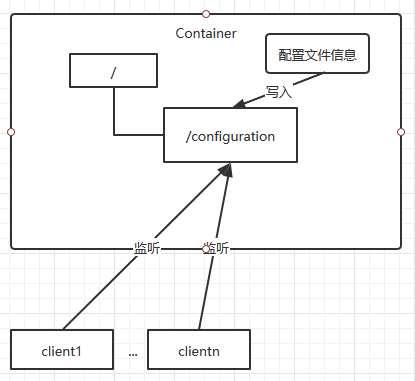
2.2 统一配置管理
分布式环境下,配置文件的同步可以由Zookeeper来实现。
- 将配置文件写入Zookeeper的一个ZNode
- 各个客户端服务监听这个ZNode
- 一旦ZNode发生改变,Zookeeper将通知各个客户端服务
2.3 统一集群管理
Zookeeper可以实现实时监控节点状态变化,当有一个三个节点的服务,假如其他一个宕机了,其他两个节点可立即收到消息,实现实时监控。将这三个节点写入Zookeeper的一个ZNode,每个节点都去监听这个ZNode,当ZNode发生变化时,这些节点可实时收到变化状态。

监听器的原理
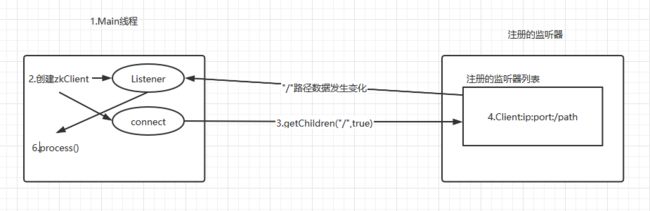
- 创建一个Main()线程
- 在Main()线程中创建两个线程,一个负责网络连接通信(connect),一个负责监听(listener)
- 通过connect线程将注册的监听事件发送给Zookeeper
- 将注册的监听事件添加到Zookeeper的注册监听器列表中
- Zookeeper监听到有数据或路径发生变化时,把这条消息发送给Listener线程
- Listener线程内部调用process()方法
三 Zookeeper集群
Zookeeper集群虽然没有指定Master和Slave。但是,在Zookeeper工作时,会通过内部选举机制产生一个Leader节点,其他节点为Follower或者是Observer。
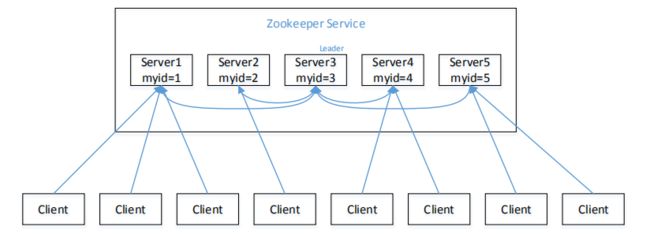
被声明为Observer的节点,不参与选举过程,也不参与写操作的”过半写成功“策略。
过半写成功策略:Leader节点接收到写请求后,这个Leader会将写请求广播给各个server,各个server会将该写请求加入待写队列,并向Leader发送成功信息,当Leader收到一半以上的成功消息后,说明该写操作可以执行。Leader会向各个server发送提交消息,各个server收到消息后开始写。
Follower和Observer只提供数据的读操作,当他们接收的写请求时,会将该请求转发给Leader节点。
集群中只要有半数以上的节点存活,Zookeeper集群就能正常服务。因此Zookeeper集群适合安装奇数台机器。
3.1 选举机制
(1)服务器 1 启动,发起一次选举。服务器 1 投自己一票。此时服务器 1 票数一票,不够半数以上(3 票),选举无法完成,服务器 1 状态保持为 LOOKING;
(2)服务器 2 启动,再发起一次选举。服务器 1 和 2 分别投自己一票并交换选票信息:此时服务器 1 发现服务器 2 的 ID 比自己目前投票推举的(服务器 1)大,更改选票为推举服务器 2。此时服务器 1 票数 0 票,服务器 2 票数 2 票,没有半数以上结果,选举无法完成,服务器 1,2 状态保持 LOOKING;
(3)服务器 3 启动,发起一次选举。此时服务器 1 和 2 都会更改选票为服务器 3。此次投票结果:服务器 1 为 0 票,服务器 2 为 0 票,服务器 3 为 3 票。此时服务器 3 的票数已经超过半数,服务器 3 当选 Leader。服务器 1,2 更改状态为 FOLLOWING,服务器 3 更改状态为 LEADING;
(4)服务器 4 启动,发起一次选举。此时服务器 1,2,3 已经不是 LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器 3 为 3 票,服务器 4 为 1 票。此时服务器 4服从多数,更改选票信息为服务器 3,并更改状态为 FOLLOWING;
(5)服务器 5 启动,同 4 一样当小弟。
点关注、不迷路
如果觉得文章不错,欢迎关注、点赞、收藏,你们的支持是我创作的动力,感谢大家。
如果文章写的有问题,请不要吝啬,欢迎留言指出,我会及时核查修改。
如果你还想更加深入的了解我,可以微信搜索「Java旅途」进行关注。回复「1024」即可获得学习视频及精美电子书。每天7:30准时推送技术文章,让你的上班路不在孤独,而且每月还有送书活动,助你提升硬实力!