数据结构
一般将数据结构分为两大类:
线性数据结构和非线性数据结构。
线性数据结构有:
线性表、栈、队列、串、数组和文件;
非线性数据结构有:
散列表、树和图。
线性表
线性表的逻辑结构是n个数据元素的有限序列:
(a1, a2 ,a3,…an)
n为线性表的长度(n≥0),n=0的表称为空表。
数据元素呈线性关系。必存在唯一的称为“第一个”的数据元素;必存在唯一的称为“最后一个”的数据元素;除第一个元素外,每个元素都有且只有一个前驱元素; 除最后一个元素外,每个元素都有且只有一个后继元素。
所有数据元素在同一个线性表中必须是相同的数据类型。
线性表按其存储结构可分为顺序表和链表。用顺序存储结构存储的线性表称为顺序表;用链式存储结构存储的线性表称为链表。
将线性表中的数据元素依次存放在某个存储区域中,所形成的表称为顺序表。一维数组就是用顺序方式存储的线性表。
链表
栈(Stack)也是一种特殊的线性表,是一种后进先出(LIFO)的结构。
栈是限定仅在表尾进行插入和删除运算的线性表,表尾称为栈顶(top),表头称为栈底(bottom)。
栈的物理存储可以用顺序存储结构,也可以用链式存储结构。
队列(Queue)是限定所有的插入只能在表的一端进行,而所有的删除都在表的另一端进行的线性表。
表中允许插入的一端称为队尾(Rear),允许删除的一端称为队头(Front)。
队列的操作是按先进先出(FIFO)的原则进行的。
队列的物理存储可以用顺序存储结构,也可以用链式存储结构。
散列表又称为哈希表。散列表算法的基本思想是:
以结点的关键字为自变量,通过一定的函数关系(散列函数)计算出对应的函数值,以这个值作为该结点存储在散列表中的地址。
当散列表中的元素存放太满,就必须进行再散列,将产生一个新的散列表,所有元素存放到新的散列表中,原先的散列表将被删除。在C#语言中,通过负载因子(load factor)来决定何时对散列表进行再散列。例如:如果负载因子是0.75,当散列表中已经有75%的位置已经放满,那么将进行再散列。
负载因子越高(越接近1.0),内存的使用效率越高,元素的寻找时间越长。负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多。
C#中以接口的方式来区分这些数据结构
数组Array为数据结构中的顺序表
MyArray[0], MyArray[1], MyArray[2]…………MyArray[6]
MyArray [0] = 1
提供对数组的相关操作
Array是抽象的基类,提供 CreateInstance 方法来创建数组
Array obj = Array.CreateInstance(typeof(string),10);
Array obj1 = Array.CreateInstance(typeof(string),2,3,4);
数组的局限性:
元素个数固定,且必须在创建数组时知道元素个数
元素类型必须相同
只能通过索引访问数组元素
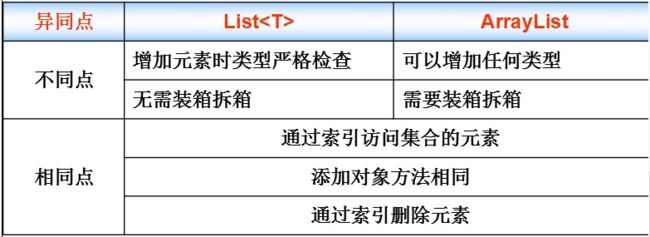
ArrayList
特点:
有序的对象列表 顺序结构
ArrayList 很类似数组
ArrayList 类没有固定大小;可以根据需要不断增长
默认大小为16个元素,当添加第17个元素时会自动扩展到32个
可以显式地指定其容量
可以存储不同类型的元素, 因为所有ArrayList中的元素都是对象(System.Object)
ArrayList 的方法:
Add(object) 把一个对象添加到 ArrayList 的末尾
Insert(index,object) 在指定位置插入一个对象
Remove(object) 移除一个对象
RemoveAt(index) 移除一个对象
Clear() 移除所有元素
Sort 对ArrayList 中的元素进行排序
队列
特点:
先进先出的对象集合
特殊的顺序表
队列(Queue)
对象按照先进先出,先来先服务的原则
对象按顺序存储在默认大小为32的缓冲区中;当缓冲区空间不足时,按增长因子(2.0)创建一个新的缓冲区,并将现有对象拷贝到新缓冲区中(开销大)
Queue的方法:
Enqueue 入队 进队
Dequeue 出队 离队
Peek 查看队头
Clear 清除队列
Contains 询问是否包含
Count 队列中的元素个数
栈
先进后出(后进先出)的对象集合 特殊的顺序表
栈(Stack)
后进先出,最后插入的对象位于栈的顶端
Stack的方法
Push 压栈 进栈 入栈
Pop 出栈 弹栈
Peek 查看栈顶
Clear 清空堆栈
Contains 是否包含
Count 栈内元素个数
哈希表
Hashtable哈希表(Hashtable) HashSet由一对(key , value) 类型的元素组成的集合所有元素的 key 必须唯一key ->value 是一对一的映射,即根据key就可以立刻在集合中找到所需元素 天气预报 书籍索引 北京 晴 ISBN-0101 红与黑
上海 阴 ISBN-0201 老人与海
广州 小雨 ISBN-1211 荆棘鸟
深圳 暴雨 ISBN-2210 简爱
Hashtable方法:
Add(key, value)
根据key而不是根据索引查找,因此速度很快
集合的迭代器
迭代器的工作原理
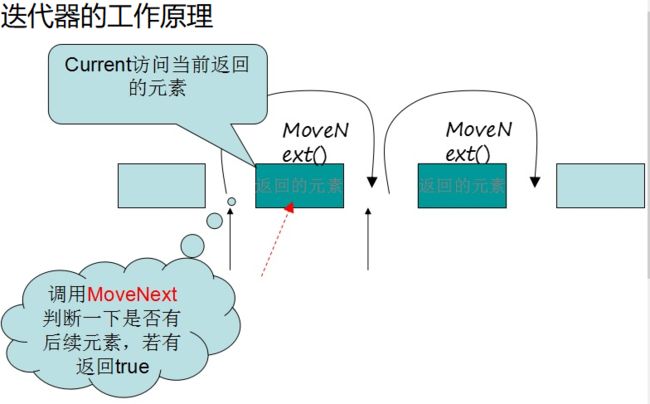
迭代器提供了对集合统一的遍历方案
foreach的本质
foreach(ElementType element in Collection)
{...}
IEnumerator enumerator = collection.GetEnumerator();
try {
while(enumerator.MoveNext())
{
ElementType element = (ElementType)enumerator.Current;
{...}
}
}
数组和集合的比较
数组声明了元素类型,但集合没有,因为集合中所用元素都存储为对象
数组的大小是固定的,不能增加和减少;而集合类可根据需要动态调整大小
检索元素的方式不同
装箱和拆箱
1. 装箱在值类型向引用类型转换时发生
object obj = 1;
这行语句将整型常量1赋给object类型的变量obj; 众所周知常量1是值类型,值类型是要放在栈上的,而object是引用类型,它需要放在堆上;要把值类型放在堆上就需要执行一次装箱操作。
以上就是装箱所要执行的操作了,执行装箱操作时不可避免的要在堆上申请内存空间,并将堆栈上的值类型数据复制到申请的堆内存空间上,这肯定是要消耗内存和cpu资源的。
2. 拆箱在引用类型向值类型转换时发生
object objValue = 4;
int value = (int)objValue;
上面的两行代码会执行一次装箱操作将整形数字常量4装箱成引用类型object变量objValue;然后又执行一次拆箱操作,将存储到堆上的引用变量objValue存储到局部整形值类型变量value中。
拆箱操作的执行过程和装箱操作过程正好相反,是将存储在堆上的引用类型值转换为值类型并给值类型变量。
装箱操作和拆箱操作是要额外耗费cpu和内存资源的,所以在c# 2.0之后引入了泛型来减少装箱操作和拆箱操作消耗。
泛型集合
泛型集合可以约束集合内的元素类型编译时检查类型约束无需装箱拆箱操作加上using System.Collections.Generic;List,Dictionary、表示该泛型集合中的元素类型Liststudents = new List();利用List存储班级集合
Dictionary具有List相同的特性约束集合中元素类型
编译时检查类型约束
无需装箱拆箱操作
与哈希表类似存储Key和Value的集合

泛型集合与传统集合相比类型更安全
泛型集合无需装箱拆箱操作
泛型的重要性
解决了很多需要繁琐操作的问题
提供了更好的类型安全性
链表
LinkedList生成和追加LinkedListlinked = new LinkedList();linked.AddLast("cat");linked.AddLast("dog");linked.AddLast("man");linked.AddFirst("first");查找和插入 LinkedListNodeLinkedListNode node = linked.Find("one");
linked.AddAfter(node, "inserted");
集合的排序
集合中全部为对象类型
所以集合需要排序的时候则必须两个对象需要有可比性
IComparable与IComparer接口
为了能够对数据项进行排序,就要确定两个数据项在列表中的相对顺序,也就是要确定两个对象的“大小”关系。一般来说,可以通过如下两种方式来定义大小关系。
第一种方式是针对对象本身。为了使对象自己能够执行比较操作,该对象必须实现IComparable接口,即至少具有一个CompareTo()成员。
System.IComparable接口中有如下方法:
int CompareTo(object obj);
它根据当前对象与要比较的对象的“大小”返回一个正数、0或一个负数。
第二种方式是提供一个外部比较器,能够比较对象的大小,并实现IComparer接口。
System.Collections.IComparer接口中有如下方法:
int Compare(object obj1, object obj2);
它根据第一个对象与第二个对象的“大小”返回一个正数、0或一个负数。
许多类在进行排序和查找时,都要求提供这样的外部比较器。
自定义集合+迭代器
自定义的集合指实现了符合某种数据存储结构的一种存储方案
若想纳入到C#的整个集合机制内 需要实现C#的集合的框架接口
示例:现在需要一个自定义的并且可以被迭代的自定义集合
需要实现的接口为:
IEnumerable 接口定义:
public interface IEnumerable
{
Ienumerator GetEnumerator();
}
实现IEnumerable的同时也要实现IEnumerator接口。IEnumerator接口为:
public interface IEnumerator
{
object Current
{
get();
}
bool MoveNext();
void Reset();
}
示例:
using System;
using System.Collections; //集合类的命名空间
namespace CustomCollection
{
// 定义集合中的元素MyClass类
class MyClass
{
public string Name;
public int Age;
// 带参构造器
public MyClass(string name,int age)
{
this.Name=name;
this.Age=age;
}
}
// 实现接口Ienumerator和IEnumerable类Iterator
public class Iterator:IEnumerator,IEnumerable
{
// 初始化MyClass 类型的集合
private MyClass[] ClassArray;
int Cnt;
public Iterator()
{
// 使用带参构造器赋值
ClassArray = new MyClass[4];
ClassArray[0] = new MyClass("Kith",23);
ClassArray[1] = new MyClass("Smith",30);
ClassArray[2] = new MyClass("Geo",19);
ClassArray[3] = new MyClass("Greg",14);
Cnt = -1;
}
// 实现IEnumerator的Reset()方法
public void Reset()
{ // 指向第一个元素之前,Cnt为1,遍历是从0开始
Cnt = -1;
}
// 实现IEnumerator的MoveNext()方法
public bool MoveNext()
{ return (++ Cnt < ClassArray.Length); }
// 实现IEnumerator的Current属性
public object Current
{
get { return ClassArray[Cnt]; }
}
// 实现IEnumerable的GetEnumerator()方法
public IEnumerator GetEnumerator()
{ return (IEnumerator)this; }
static void Main()
{
Iterator It=new Iterator();
// 像数组一样遍历集合
foreach(MyClass MY in It)
{
Console.WriteLine("Name : "+MY.Name.ToString()); Console.WriteLine("Age : "+MY.Age.ToString());
}
}
}
}
意义:明白迭代器的迭代原理