工作原理 :
基于爬虫对网络上免费的代理公布站进行抓取和分析 , 并将最近的结果保存在本地文件中 , 等待验证 , 可以利用花刺等工具进行批量验证 , 也可以使用笔者编写的Python多线程代理验证脚本进行批量验证
截图
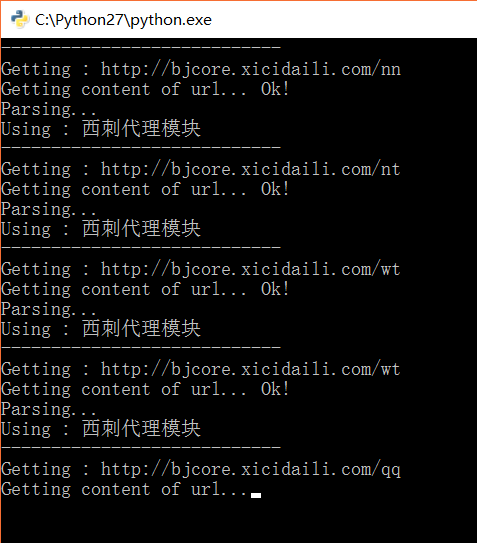
Paste_Image.png
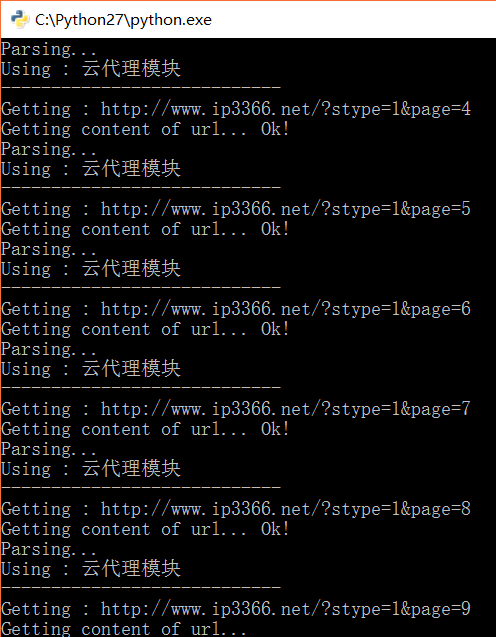
321321321.png
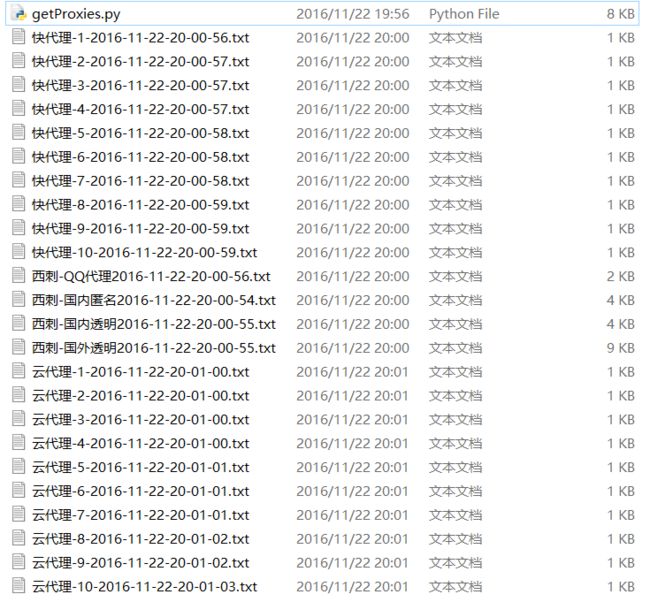
Paste_Image.png

Paste_Image.png
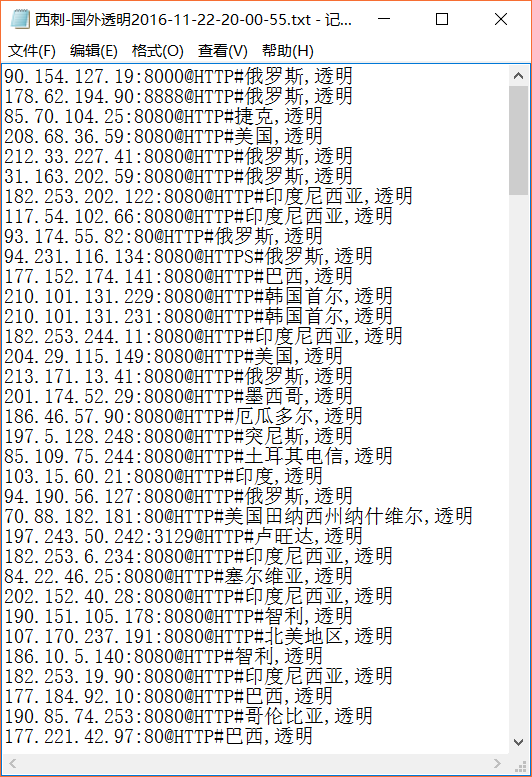
Paste_Image.png
代码实现 :
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import time
import sys
import binascii
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
# config-start
proxiesFileName = "proxies.txt" # 获取到的代理保存的文件名
timeout = 5 # 连接超时时间
urls = [
'http://bjcore.xicidaili.com/nn', # 国内匿名
'http://bjcore.xicidaili.com/nt', # 国内透明
'http://bjcore.xicidaili.com/wt', # 国外匿名
'http://bjcore.xicidaili.com/wt', # 国外透明
'http://bjcore.xicidaili.com/qq', # Socks代理
'http://www.kuaidaili.com/proxylist/1', # 快代理
'http://www.kuaidaili.com/proxylist/2', # 快代理
'http://www.kuaidaili.com/proxylist/3', # 快代理
'http://www.kuaidaili.com/proxylist/4', # 快代理
'http://www.kuaidaili.com/proxylist/5', # 快代理
'http://www.kuaidaili.com/proxylist/6', # 快代理
'http://www.kuaidaili.com/proxylist/7', # 快代理
'http://www.kuaidaili.com/proxylist/8', # 快代理
'http://www.kuaidaili.com/proxylist/9', # 快代理
'http://www.kuaidaili.com/proxylist/10', # 快代理
'http://www.ip3366.net/?stype=1&page=1', # 云代理
'http://www.ip3366.net/?stype=1&page=2', # 云代理
'http://www.ip3366.net/?stype=1&page=3', # 云代理
'http://www.ip3366.net/?stype=1&page=4', # 云代理
'http://www.ip3366.net/?stype=1&page=5', # 云代理
'http://www.ip3366.net/?stype=1&page=6', # 云代理
'http://www.ip3366.net/?stype=1&page=7', # 云代理
'http://www.ip3366.net/?stype=1&page=8', # 云代理
'http://www.ip3366.net/?stype=1&page=9', # 云代理
'http://www.ip3366.net/?stype=1&page=10', # 云代理
# 很奇怪这个网站的所有代理都没有注明协议(这个网站很久没有更新了)
# 'http://www.proxy360.cn/default.aspx', # 综合代理
# 'http://www.proxy360.cn/Proxy', # 免费代理服务器
# 'http://www.proxy360.cn/QQ-Proxy', # 免费QQ代理服务器
# 'http://www.proxy360.cn/MSN-Proxy', # 免费MSN代理服务器
# 'http://www.proxy360.cn/Region/Brazil', # 巴西
# 'http://www.proxy360.cn/Region/China', # 中国
# 'http://www.proxy360.cn/Region/America', # 美国
# 'http://www.proxy360.cn/Region/Taiwan', # 台湾
# 'http://www.proxy360.cn/Region/Japan', # 日本
# 'http://www.proxy360.cn/Region/Thailand', # 泰国
# 'http://www.proxy360.cn/Region/Vietnam', # 越南
# 'http://www.proxy360.cn/Region/bahrein', # 巴林
]
# config-end
def getSimpleContent(url):
headers={'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
return requests.get(url,headers=headers).text.encode('UTF-8')
def analysis(url):
print "Getting content of url...",
content=getSimpleContent(url)
print "Ok!"
results=[]
print "Parsing..."
soup = BeautifulSoup(content, "html.parser")
if "xicidaili" in url:
print u"Using : 西刺代理模块"
trs = soup.findAll('tr')
trs = trs[1:] # 去掉表头
for tr in trs:
tds = tr.findAll('td')
ip = tds[1].string
port = tds[2].string
location = tds[3].string
anonymous = tds[4].string
protocol = tds[5].string
if location == None:
location = u"未知"
else:
location = location.replace(" ","")
location=location.replace('\x0a','')
anonymous=anonymous.replace('\x0a','')
protocol=protocol.replace('\x0a','')
proxyType=url.split("/")[-1]
if proxyType=="nn":
tempName=u"国内匿名"
elif proxyType=="nt":
tempName=u"国内透明"
elif proxyType=="wn":
tempName=u"国外匿名"
elif proxyType=="wt":
tempName=u"国外透明"
elif proxyType=="qq":
tempName=u"QQ代理"
else:
tempName=u""
fileName=u"西刺-"+tempName+str(getNowTime("%Y-%m-%d-%H-%M-%S"))+".txt"
if proxyType=="qq": # 将代理类型从QQ代理替换为SOCKS5
protocol=u"SOCKS5"
# 记录日志文件
appendToFile(fileName,ip+":"+port+"@"+protocol+"#"+location+","+anonymous+"\n")
return
elif "proxy360" in url:
print u"Using : proxy360模块"
divs = soup.findAll(style="float:left; display:block; width:630px;")
for div in divs:
spans=div.findAll('span')
ip=spans[0].string
ip=ip.replace(' ','')
ip=ip.replace('\r\n','')
port=spans[1].string
port=port.replace(' ','')
port=port.replace('\r\n','')
anonymous=spans[2].string
anonymous=anonymous.replace(' ','')
anonymous=anonymous.replace('\r\n','')
location=spans[3].string
location=location.replace(' ','')
location=location.replace('\r\n','')
proxyType=url.split("/")[-1]
if proxyType=="default.aspx":
tempName=u"综合代理"
elif proxyType=="Proxy":
tempName=u"免费代理服务器"
elif proxyType=="QQ-Proxy":
tempName=u"免费QQ代理服务器"
elif proxyType=="MSN-Proxy":
tempName=u"免费MSN代理服务器"
elif proxyType=="Brazil":
tempName=u"巴西"
elif proxyType=="China":
tempName=u"中国"
elif proxyType=="America":
tempName=u"美国"
elif proxyType=="Taiwan":
tempName=u"台湾"
elif proxyType=="Japan":
tempName=u"日本"
elif proxyType=="Thailand":
tempName=u"泰国"
elif proxyType=="Vietnam":
tempName=u"越南"
elif proxyType=="bahrein":
tempName=u"巴林"
else:
tempName=u""
fileName=u"proxy360-"+tempName+str(getNowTime("%Y-%m-%d-%H-%M-%S"))+".txt"
# 这个网站并没有指定代理的协议 , 这里默认使用HTTP协议
protocol="HTTP"
# 记录日志文件
appendToFile(fileName,ip+":"+port+"@"+protocol+"#"+location+","+anonymous+"\n")
return
elif "kuaidaili" in url:
print u"Using : 快代理模块"
trs = soup.findAll('tr')
trs = trs[1:] # 去掉表头
for tr in trs:
tds = tr.findAll('td')
ip=tds[0].string
port=tds[1].string
anonymous=tds[2].string
protocol=tds[3].string
location=tds[5].string
tempName=url.split("/")[-1]
fileName=u"快代理-"+tempName+"-"+str(getNowTime("%Y-%m-%d-%H-%M-%S"))+".txt"
# 记录日志文件
appendToFile(fileName,ip+":"+port+"@"+protocol+"#"+location+","+anonymous+"\n")
return
elif "ip3366" in url:
print u"Using : 云代理模块"
trs = soup.findAll('tr')
trs = trs[1:] # 去掉表头
for tr in trs:
tds = tr.findAll('td')
ip=tds[0].string
port=tds[1].string
anonymous=tds[2].string
protocol=tds[3].string
location=tds[5].string
tempName=url.split("page=")[-1]
fileName=u"云代理-"+tempName+"-"+str(getNowTime("%Y-%m-%d-%H-%M-%S"))+".txt"
# 这里有万恶的编码问题 , 暂时没有能力解决 , 中文的描述就先不写到文件里了
# 记录日志文件
# appendToFile(fileName,ip+":"+port+"@"+protocol+"#"+location+","+anonymous+"\n")
appendToFile(fileName,ip+":"+port+"@"+protocol+"\n")
return
else:
return
def getNowTime(format):
return time.strftime(format,time.localtime(time.time()))
def appendToFile(fileName,content):
file=open(fileName,"a+")
file.write(content)
file.close()
# 批量获取代理
for url in urls:
print "----------------------------"
print "Getting : "+url
analysis(url)