原文
1概览
TensorOnSpark是一个可扩展的分布式深度学习框架。它可以在Spark上利用一个新的Spark概念——SparkSession(分布式机器学习上下文)无缝地运行TensorFlow程序。用户可以使用普通的TensorFlow接口来编写机器学习和DNN程序,然后分布式运行它们,底层机制对用户透明。与Tensorflow节点的分布式模式相比,TensorOnSpark使用可靠和可扩展的分布式系统(例如Hadoop和Spark)和更少的网络流量来更好的管理计算机资源和更快速地处理大容量数据。
TensorOnSpark的特点如下:
易于大容量数据准备;
高效的计算机资源分配;
可靠,灵活的并行参数更新。
高度兼容Tensorflow
低网络流量和高学习准确性
2 SparkSession
SparkSession是TensorOnSpark的核心模块。TensorFlow session(包括图形和相关联的参数值)与SparkSession的实例一一对应。SparkSession向用户公开TensorFlow模型图的单个实例和模型参数?(还不太懂什么意思)。使用SparkSession,用户可以像在单机中构建TensorFlow学习模型一样构建训练模型,让SparkSession处理分布式RDD数据集的分布式训练和分布式模型参数值的同步。
3 架构
SparkSession架构如图1所示
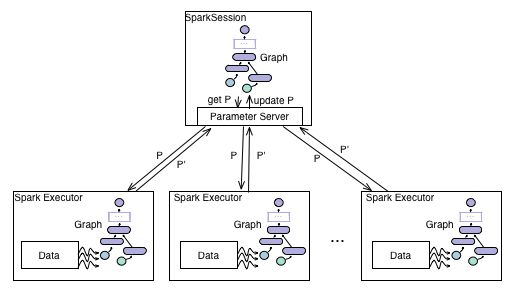
SparkSession采用主从结构,SparkSession应用主从架构,其中主节点是Spark作业的应用程序主节点,从节点是Spark执行器。主节点维护TensorFlow图的单个实例和参数值,并托管(hosts)Tensor参数服务器(TPS)用于并行参数更新。每个worker将RDD数据的分区作为训练输入进行前向反馈(feed forward)并且周期性地与TPS同步以更新训练的参数值。
4 如何工作?
在运行学习程序之前,用户需要建立学习模型并为模型准备训练输入数据。
SparkSession主节点中模型图的构造与构建TensorFlow图完全相同,即用户将变量和操作定义为具有连接的图节点。在SparkSession数据准备阶段,训练输入数据通常存储在诸如HDFS和HBase的分布式存储系统中。用户可以使用Spark导入和处理RDD格式的数据,其中RDD的每个条目都是输入Tensor的数据条目。
建立TensorFlow模型后的训练工作流程如下:
1.SparkSession主节点将包括初始参数值的模型图持久化到(persist)HDFS,以便从Spark executors进一步检索。
2.主节点向executors广播TPS的信息和输入Tensor(或feed)和输出Tensor(或fetch)的元数据信息。
3.executors从HDFS检索模型图并在本地构造图,这与主节点中的一致。
4.每个executor将对应的RDD分区中准备好的数据反馈到图形并更新局部参数值。
5.对于executor中的每个指定的训练步骤,该executor将新的参数值推送到TPS并从TPS中取回新更新的参数值。
6.当每个executor用完输入数据的整个分区时,训练的一个epoch结束。
7.输入的RDD数据可以从步骤4开始重新分割并重新排序用于训练的下一个epoch。
在步骤5中,executors在每个?里程碑(milestone)?处用TPS更新参数值,但不同的executors不需要在同一里程碑处等待来同步参数。也就是说,不同的executors异步更新TPS。换句话说,不同里程碑的executors可以同时用TPS更新参数。 TPS通过灵活的参数组合器控制异步参数更新。 TPS提供了几种高效的内置组合器,并允许用户自定义组合器。
5 例子
TensorOnSpark安装教程在 homepage里,其中演示使用TensorSpark与MNIST的例子。 MNIST是识别图像中的手写数字的学习程序。我们在TensorOnSpark中显示MNIST程序的一部分,并解释python中的代码。完整版本可以在 spark_mnist.py中找到。
# Extract the images and labels from the file in HDFS
image_rdd = mnist.extract_images(sc, mnist.train_image_path)
label_rdd = mnist.extract_labels(sc, mnist.train_label_path, num_class=10, one_hot=True)
# image_label is the rdd where each entry is the tuple of (image, label)
image_label_rdd = image_rdd.join(label_rdd, numPartitions=num_partition).mapPartitions(mnist.flatten_image_label).cac he()
# Build up the normal TensorFlow graph and initialize the variables. This procedure is exactly the same as the noraml TensorFlow program
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# Indicate the feed and fetch variables for a SparkSession run.
feed_name_list = [x.name, y_.name]
param_list = [W, b]
# initial the SparkSession with the Spark context, TensorFlow session and other running configuration information.
spark_sess = sps.SparkSession(sc, sess, user='liangfengsid', name='spark_mnist', server_host='localhost', server_port=10080, sync_interval=100, batch_size=100)
# run the SparkSession and repartition between epochs
partitioner = par.RandomPartitioner(num_partition)
for i in range(num_epoch):
spark_sess.run(train_step, feed_rdd=image_label_rdd, feed_name_list=feed_name_list, param_list=param_list, shuffle_within_partition=True)
if i != num_epoch-1:
temp_image_label_rdd = image_label_rdd.partitionBy(num_partition, partitioner).cache()
image_label_rdd.unpersist()
image_label_rdd = temp_image_label_rdd
(Cont.)进一步细节介绍运行机制和设计考虑即将到来。