前言
上回我们建立了 tensorflow 的开发环境,跑测试模型比较方便,但对于树莓派来说,还是太庞大了。仅有 0.3fps 无法满足实时的生产环境需求,这篇我们部署一下专门为移动端和嵌入式设备而生的 TensorFlow Lite,并跑几个模型,测试一下纯树莓派上的极限帧率。

TensorFlow Lite 是一组工具,可帮助开发者在移动设备、嵌入式设备和 IoT 设备上运行 TensorFlow 模型。它支持设备端机器学习推断,延迟较低,并且二进制文件很小。
TensorFlow Lite 包括两个主要组件:
- TensorFlow Lite 解释器,它可在手机、嵌入式 Linux 设备和微控制器等很多不同类型的硬件上运行经过专门优化的模型。
- TensorFlow Lite 转换器,它可将 TensorFlow 模型转换为高效形式以供解释器使用,并可引入优化以减小二进制文件的大小和提高性能。
转换器一般在主电脑上完成,主要是为了静态化计算图,转换权重类型后,生成 .tflite 文件。而解释器主要在嵌入式设备上运行,我们这里先在树莓派上安装一下 tensorflow lite。
安装 TensorFlow Lite
1. 建立虚拟环境
python3 -m venv --system-site-packages ~/my_envs/tf_lite
source ~/my_envs/tf_lite/bin/activate2. 安装 2.1.0 版本
# 可以在官网里下载各个版本
# https://www.tensorflow.org/lite/guide/python
wget https://dl.google.com/coral/python/tflite_runtime-2.1.0.post1-cp37-cp37m-linux_armv7l.whl
pip install tflite_runtime-2.1.0.post1-cp37-cp37m-linux_armv7l.whl3. 启用 opencv
cd ~/my_envs/tf_lite/lib/python3.7/site-packages
ln -s /usr/local/lib/python3.7/site-packages/cv2 cv24. 安装完成
import tflite_runtime.interpreter as tflite
tflite.Interpreter
配置树莓派摄像头
1. 测试摄像头
先保证摄像头排线已插入树莓派的 CSI 接口,并在 raspi-config 里 Interfacing options -> camera 选项里启用了摄像头。

# 拍摄照片
raspistill -o demo.jpg
# 录制视频
raspivid -o vid.h264看一下目录里是否有拍摄的 demo.jpg 照片和 vid.h264 视频文件,保证硬件没有问题。
2. 使用 picamera 控制摄像头
pip install picamera拍摄一张照片
import picamera
from time import sleep
camera = picamera.PiCamera()
try:
# 设置分辨率
camera.resolution = (1024, 768)
camera.brightness = 60
camera.start_preview()
# 增加文本
camera.annotate_text = 'Raspberry Pi'
sleep(3)
# 捕捉一张照片
camera.capture('image1.jpeg')
finally:
camera.stop_preview()
camera.close()Tip:
一定要记得用完摄像头后用 camera.close() 关闭,或是用 With 子句自动释放资源。否则会收到 picamera.exc.PiCameraMMALError: Failed to enable connection: Out of resources 的错误信息,只能 Kill python 进程强制释放了。
录制一段视频
with picamera.PiCamera() as camera:
camera.resolution = (640, 480)
camera.start_preview()
camera.start_recording('video.h264')
camera.wait_recording(10)
camera.stop_recording()3. 使用 opencv 控制摄像头
import cv2
cap = cv2.VideoCapture(0)
cap.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
while True:
# 获取一帧图像
ret, frame = cap.read()
# 显示窗口
cv2.imshow("capture", frame)
# 按 q 退出
if(cv2.waitKey(1) == ord('q')):
cv2.destroyAllWindows()
breakTip:
如果在OpenCV中调用CSI摄像头会出现无数据的现象,这是因为树莓派中的camera module是放在/boot/目录中以固件形式加载的,不是一个标准的V4L2的摄像头驱动,所以加载起来之后会找不到/dev/video0的设备节点。我们在/etc/modules里面添加一行bcm2835-v4l2 就能解决问题。
$sudo nano /etc/modules
添加:bcm2835-v4l2,保存关闭即可。
4. 查询其他 usb 视频设备
ls -ltrh /dev/video*使用 jupyter notebook
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含代码、方程式、可视化和文本的文档。广泛的用于各种云平台上,为了后续代码的可移植性,我们这里先安装一下。
1. 安装 jupyter
sudo apt install jupyter2. 创建配置文件
创建Jupyter notebook的配置文件jupyter_notebook_config.py,在终端中输入:
jupyter notebook --generate-config
sudo nano ~/.jupyter/jupyter_notebook_config.py编辑配置文件 jupyter_notebook_config.py
c.NotebookApp.ip = '127.0.0.1'
c.NotebookApp.open_browser = True
这两个去除注释,监听本机端口地址 127.0.0.1 即可。
3. 配置虚拟环境到 jupyter 内
pip install ipykernel用 python -m ipykernel install --user --name 虚拟环境名 --display-name Jupyter中要显示的名字,来绑定已有的虚拟环境。
# 配置 pytorch 环境
python -m ipykernel install --user --name pytorch --display-name pytorch
# 配置 opencv 环境
python -m ipykernel install --user --name opencv --display-name opencv
# 配置 tensorflow 环境
python -m ipykernel install --user --name tensorflow --display-name tensorflow
# 配置 tensorflow 2.x 环境
python -m ipykernel install --user --name tf2 --display-name tf2
# 配置 tf_lite 环境
python -m ipykernel install --user --name tf_lite --display-name tf_lite4. 启动 notebook,切换不同的环境
jupyter notebook菜单里 服务 -> 改变服务 -> 列出了所有的虚拟环境。

Tensorflow Lite 应用
1. 克隆官方示例
git clone https://github.com/tensorflow/examples --depth 12. 图像分类应用
首先安装依赖包,再下载一个 MobileNet 模型文件和分类标签文件到 tmp 目录中。
cd examples/lite/examples/image_classification/raspberry_pi
bash download.sh /tmp3. 在 notebook 中运行一下推理
jupyter notebook我们新建一个 classify_picamera.ipynb 文件,读入tflite模型,
labels = load_labels('/tmp/labels_mobilenet_quant_v1_224.txt')
interpreter = Interpreter('/tmp/mobilenet_v1_1.0_224_quant.tflite')
interpreter.allocate_tensors()
_, height, width, _ = interpreter.get_input_details()[0]['shape']调用 interpreter.invoke() 来推理,
def classify_image(interpreter, image, top_k=1):
"""Returns a sorted array of classification results."""
set_input_tensor(interpreter, image)
interpreter.invoke()
output_details = interpreter.get_output_details()[0]
output = np.squeeze(interpreter.get_tensor(output_details['index']))
# If the model is quantized (uint8 data), then dequantize the results
if output_details['dtype'] == np.uint8:
scale, zero_point = output_details['quantization']
output = scale * (output - zero_point)
ordered = np.argpartition(-output, top_k)
return [(i, output[i]) for i in ordered[:top_k]]最后在 opencv 的窗口来展示一下分类结果。
with picamera.PiCamera(resolution=(640, 480), framerate=30) as camera:
camera.start_preview()
try:
stream = io.BytesIO()
for _ in camera.capture_continuous(
stream, format='jpeg', use_video_port=True):
stream.seek(0)
image = Image.open(stream).convert('RGB').resize((width, height),
Image.ANTIALIAS)
start_time = time.time()
results = classify_image(interpreter, image)
elapsed_ms = (time.time() - start_time) * 1000
label_id, prob = results[0]
camera.annotate_text = '%s %.2f\n%.1fms' % (labels[label_id], prob,
elapsed_ms)
# print(camera.annotate_text)
data = np.frombuffer(stream.getvalue(), dtype=np.uint8)
dst = cv2.imdecode(data, cv2.IMREAD_UNCHANGED)
cv2.imshow("img", dst)
stream.seek(0)
stream.truncate(0)
if(cv2.waitKey(1) == ord('q')):
cv2.destroyAllWindows()
break
finally:
camera.stop_preview()
print('end')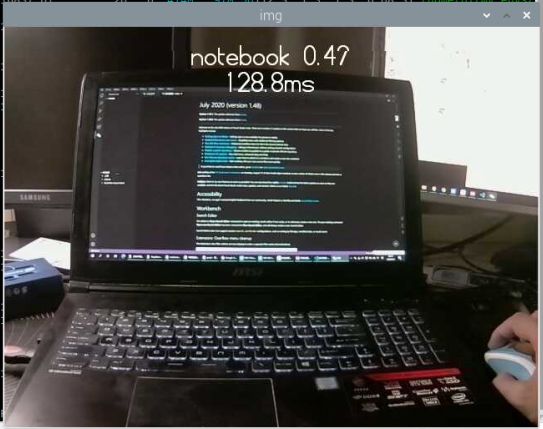
速度还是比较快的,130ms一帧,能达到大约是7-8fps,准确率也很高,可见提升还是很明显的。这既得益于 MobileNet 的小巧,也得益于 tflite 的精简模型的加速,可达到准实时的效果。
4. 目标检测应用
cd examples/lite/examples/object_detection/raspberry_pi
bash download.sh /tmp下载一个 MobileNet ssd v2 模型文件和 coco 标签文件到 tmp 目录中。
5. 在 notebook 中运行一下推理
jupyter notebook我们新建一个 detect_picamera.ipynb 文件,读入tflite模型,
labels = load_labels('/tmp/coco_labels.txt')
interpreter = Interpreter('/tmp/detect.tflite')
interpreter.allocate_tensors()
_, input_height, input_width, _ = interpreter.get_input_details()[0]['shape']调用 interpreter.invoke() 来推理,
def detect_objects(interpreter, image, threshold):
"""Returns a list of detection results, each a dictionary of object info."""
set_input_tensor(interpreter, image)
interpreter.invoke()
# Get all output details
boxes = get_output_tensor(interpreter, 0)
classes = get_output_tensor(interpreter, 1)
scores = get_output_tensor(interpreter, 2)
count = int(get_output_tensor(interpreter, 3))
results = []
for i in range(count):
if scores[i] >= threshold:
result = {
'bounding_box': boxes[i],
'class_id': classes[i],
'score': scores[i]
}
results.append(result)
return results获得标注目标,转换标注框和类别标签
def annotate_objects(annotator, results, labels):
"""Draws the bounding box and label for each object in the results."""
for obj in results:
# Convert the bounding box figures from relative coordinates
# to absolute coordinates based on the original resolution
ymin, xmin, ymax, xmax = obj['bounding_box']
xmin = int(xmin * CAMERA_WIDTH)
xmax = int(xmax * CAMERA_WIDTH)
ymin = int(ymin * CAMERA_HEIGHT)
ymax = int(ymax * CAMERA_HEIGHT)
# Overlay the box, label, and score on the camera preview
annotator.bounding_box([xmin, ymin, xmax, ymax])
annotator.text([xmin, ymin],
'%s\n%.2f' % (labels[obj['class_id']], obj['score']))最后用 opencv 合并一下视频流和标注层,在 cv2 窗口展示。
with picamera.PiCamera(
resolution=(CAMERA_WIDTH, CAMERA_HEIGHT), framerate=30) as camera:
camera.start_preview()
try:
stream = io.BytesIO()
annotator = Annotator(camera)
for _ in camera.capture_continuous(
stream, format='jpeg', use_video_port=True):
stream.seek(0)
image = Image.open(stream).convert('RGB').resize(
(input_width, input_height), Image.ANTIALIAS)
start_time = time.monotonic()
results = detect_objects(interpreter, image, 0.4)
elapsed_ms = (time.monotonic() - start_time) * 1000
annotator.clear()
annotate_objects(annotator, results, labels)
annotator.text([5, 0], '%.1fms' % (elapsed_ms))
annotator.update()
data = np.frombuffer(stream.getvalue(), dtype=np.uint8)
dst = cv2.imdecode(data, cv2.IMREAD_UNCHANGED)
dst2 = cv2.cvtColor(np.asarray(annotator._buffer),cv2.COLOR_RGB2BGR)
dst = cv2.add(dst, dst2)
cv2.imshow("img", dst)
stream.seek(0)
stream.truncate(0)
if(cv2.waitKey(1) == ord('q')):
cv2.destroyAllWindows()
break
finally:
camera.stop_preview()
180-200ms一帧,5 fps左右,工作量上升了些,所以比分类任务稍慢了一些,这应该已达到树莓派 4代的极限。若要再提升性能,就要用上 intel 神经棒或 google coral 这类 usb 扩展资源了。
安装包和源码下载
本期相关文件资料,可在公众号后台回复:“rpi06”,获取下载链接。
下一篇预告
我们将在 tersorflow lite 上,
做一些有趣的应用,
敬请期待...
