1、@Repository
//在 XML 配置文件中启动 Spring 的自动扫描功能
……
Spring 在容器初始化时将自动扫描 base-package 指定的包及其子包下的所有 class文件,所有标注了 @Repository 的类都将被注册为 Spring Bean。
我的问题1:@Repository与@component @Service等注解有什么区别?
解释:@Repository 只能标注在 DAO 类上,这是因为该注解的作用不只是将类识别为Bean,同时它还能将所标注的类中抛出的数据访问异常封装为 Spring 的数据访问异常类型。
Spring 2.5 在@Repository的基础上增加了功能类似的额外三个注解:@Component、@Service、@Constroller
2、@RequestBody
@Responsebody 注解表示该方法的返回的结果直接写入 HTTP 响应正文(ResponseBody)中。
通常是在使用 @RequestMapping 后,返回值通常解析为跳转路径,加上 @Responsebody 后返回结果不会被解析为跳转路径,而是直接写入HTTP 响应正文中。
@RequestMapping(value = "user/login")
@ResponseBody
// 将ajax(datas)发出的请求写入 User 对象中,返回json对象响应回去
public User login(User user) {
User user = new User();
user .setUserid(1);
user .setUsername("MrF");
user .setStatus("1");
return user ;
}
用@RequestBody获取前端的传值
@RequestBody自动封装成Json,后台可以直接取到值。
前端数据传递:
var str = JSON.stringify( {name:"张三" , age : 15 , param : {number : "1000" , className : "1班"}} );
$.ajax({
url : "http://localhost:88/hello/hello",
type : "post",
contentType: 'application/json',
data: str,
});
实体类
public class User {
private String name;
private int age;
T param;}
后端Controller层
@PostMapping("/hello")
public String helloworld(@RequestBody User user) {
System.out.println(user.getName()+" "+user.getAge()+" "+user.getParam().getNumber()+
" "+user.getParam().getClassName());
return "index";
}
}
PS:必须使用post请求
3、SpringMVC后台控制层获取参数的主要方式
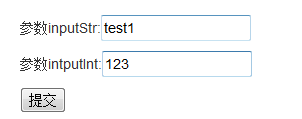
@RequestMapping("testRequestParam")
public String filesUpload(@RequestParam String inputStr, HttpServletRequest request) {
System.out.println(inputStr);
int inputInt = Integer.valueOf(request.getParameter("inputInt"));
System.out.println(inputInt);
return "index";
}
4、ResponseBody
将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML。
@RequestMapping("/login")
@ResponseBody
public User login(User user){
return user;
}
User字段:userName pwd
那么在前台接收到的数据为:'{"userName":"xxx","pwd":"xxx"}'
效果等同于如下代码:
@RequestMapping("/login")
public void login(User user, HttpServletResponse response){
response.getWriter.write(JSONObject.fromObject(user).toString());
}
一、注解的提示
@Component:把普通pojo实例化到spring容器中,相当于配置文件中的:
使用Entry获取映射项
Map map=new HashMap();
map.put("1", 1);
Iterator itor=map.entrySet().iterator();
Map.Entry entry=(Map.Entry)itor.next();
二、为什么需要日志(如Logger):
1、出问题后定位当时问题
2、显示程序当前运行状态
三、Async
异步调用只是发送了调用的指令,调用者无需等待被调用的方法完全执行完毕;而是继续执行下面的流程。
在异步处理的方法上加上@Async注解,调用者无需等待它的完成,即可继续其他的操作。
返回值可以返回Future类型
四、Quartz编程——定时任务调度
Quartz给定一个触发条件,到了时间点,触发相应的Job。Quartz定时任务默认都是并发执行的,不会等待上一次任务执行完毕,只要间隔时间到就会执行。
Scheduler - 用于与调度程序交互的主程序接口。
Job - 我们预先定义的希望在未来时间能被调度程序执行的任务类,Job类必须实现Job接口,接口中只有一个方法:execute()当job的触发器启动时,job的execute方法将被调度器中的某个工作进程调用.
JobDetail - 使用JobDetail来定义定时任务的实例。
Trigger - 触发器,表明任务在什么时候会执行。
scheduler.scheduleJob(job, trigger);
JobDataMap 可以用来保存数据对象。
五、对于@scope作用域的理解
prototype:prototype作用域部署的bean,每一次请求都会产生一个新的bean实例。
Spring不能对一个prototype bean的整个生命周期负责,容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。 清除prototype作用域的对象并释放任何prototype bean所持有的昂贵资源,都是客户端代码的职责。
request:针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效。
session:针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP session内有效
六:JAVA中的泛型T
T代表一个类型,Class
在实例化的时候,T要替换成具体类
public class PageResult
七、@Resourse的重新理解
@Autowired按byType自动注入。而@Resource默认按 byName自动注入,实际过程中如果什么都不指定,就先按照名字查找,如果没找到的话就再按照类型查询。
八、StringUtil工具类
//截取字符串:
StringUtils.substring("china", 2, 4);
//是否为空
//为空的标准是 str==null 或 str.length()==0
isEmpty(String str)
//除去字符串头尾部的空白
StringUtil.trim(" abc ")
//比较两个字符串是否相等
equals(String str1,String str2)
//返回searchChar 在字符串中第一次出现的位置,如果没找到则返回 -1
indexOf(String str,char searchChar)
contains(String str,char searchChar)
//字符串中的大写转小写,小写转换为大写
swapCase(String str)
数据库
问题1:为什么用了@Entity还要用@Table
answer:@Entity说明这个class是实体类,并且使用默认的orm规则,即class名即数据库表中表名,class字段名即表中的字段名。
如果想改变这种默认的orm规则,就要使用@Table来改变class名与数据库中表名的映射规则,@Column来改变class中字段名与db中表的字段名的映射规则。
注:@table中catalog是数据库的名字
2、java.io.Serializable 序列化接口
(场景一)以上面提到的Person.java为例。这个VO类中的两个字段name和age在程序运行后都在堆内存中,程序执行完毕后内存得到释放,name和age的值也不复存在。如果现在计算机要把这个类的实例发送到另一台机器、或是想保存这个VO类的实例到数据库(持久化对象),以便以后再取出来用。这时就需要对这个类进行序列化,便于传送或保存。用的时候再反序列化重新生成这个对象的实例。
(场景二)以搬桌子为例,桌子太大了不能通过比较小的门,我们要把它拆了再运进去,这个拆桌子的过程就是序列化。同理,反序列化就是等我们需要用桌子的时候再把它组合起来,这个过程就是反序列化。
把原本在内存中的对象状态变成可存储或传输的过程称之为序列化
3、sessionfactory
sessionFactory就是用来创建session会话的工厂。
一般情况下,一个项目通常只需要一个SessionFactory就够了,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
hibernate中的session并不是http中所说的session,hibernate中的session用来表示应用程序和数据库的一次交互。
通常将每个Session实例和一个数据库事务绑定,也就是每执行一个数据库事务,都应该先创建一个新的Session实例,在使用Session后,还需要关闭Session。
Session session = sessionFactory.openSession();
session.save();//保存
session.get();//获取
session.delete()//删除
session.update();//修改
4、sqlQuery
//标量查询:
sess.createSQLQuery("SELECT * FROM CATS").list();
返回一个Object数组(Object[])组成的List,数组每个元素都是CATS表的一个字段值。
//实体查询:
sess.createSQLQuery("SELECT * FROM CATS").addEntity(Cat.class);
返回一个List,每个元素都是一个Cat实体。
//预编译SQL语句
Object[] params = new Integer[]{1, 2};
String hqlF = "from Student where id in (?,?)";
Query query = session.createQuery(hqlF);
for (int i = 0; i < params.length; i++)
{
query.setParameter(i, params[i]);
}
//当有使用到in参数来连接条件时 则可以使用setParameterList来使用
String hqlS = "from Student where id in (:valueList)";
Query queryS = session.createQuery(hqlS);
queryS.setParameterList("valueList", params);
5、map与Hashlist的区别
6、dependency的作用
com.timevale.esignproCertSeal
esignproCertSeal-common-service-facade
1.0.27
CreateTempQuickSealModel createTempQuickSealModel = new CreateTempQuickSealModel();
BeanUtils.copyProperties(request,createTempQuickSealModel);
QuickCreateSealTemplateReturn data = sealManageService.createTemplateOfficialSeal(createTempQuickSealModel);
7、持久化类
a)什么是持久化类
持久化类指的是一个Java类与数据库表建立了映射关系,那么这个类称为是持久化类。
b)持久化类的要点
1、持久化类的属性要尽量使用包装类的类型。包装类的类型语义描述更清晰而基本数据类型不容易描述。举个例子:
假设表中有一列员工工资,如果使用double类型,如果这个员工工资忘记录入到系统中,系统会将默认值0存入到数据库,如果这个员工工资被扣完了,也会向系统中存入0.那么这个0就有了多重含义。
而如果使用包装类类型就会避免以上情况,如果使用Double类型,忘记录入工资就会存入null,而这个员工工资被扣完了,就会存入0,不会产生歧义。
持久化类要有一个唯一标识OID与表的主键对应。因为Hibernate中需要通过这个唯一标识OID区分在内存中是否是同一个持久化类。
似乎是Long ID
c)Bean表示可重用组件
d)Hiberbate
hibernate负责把内存中的对象持久化到数据库表中,靠的就是对象标识符OID来区分两个对象是否是同一个。
e)Hibernate的缓存机制
Hibernate的一级缓存就是指Session缓存,Session缓存是一块内存空间,用来存放相互管理的java对象。
在使用Hibernate查询对象的时候,首先会使用对象属性的OID值在Hibernate的一级缓存中进行查找,如果找到匹配OID值的对象,就直接将该对象从一级缓存中取出使用,不会再查询数据库;
如果没有找到相同OID值的对象,则会去数据库中查找相应数据。当从数据库中查询到所需数据时,该数据信息也会放置到一级缓存中。Hibernate的一级缓存的作用就是减少对数据库的访问次数。
f)HQL语句
List specials = (List)session.createQuery("select spe from Special spe").list();
//参数化形式
List students = (List)session.createQuery("select stu from Student stu where name like ?")
.setParameter(0, "%刘%")
.list();
g)session.createQuery
用hql语句进行查询
把生成的Bean为对象装入list返回
sessionFactory.getCurrentSession().createQuery(HQL).list()
h)Hibernate的查询之Criteria查询
Criteria 查询采用面向对象方式封装查询条件,又称为对象查询;就是对SQL 语句进行封装,采用对象的方式来组合各种查询条件。
由Hibernate 自动产生SQL 查询语句
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session session = sessionFactory.openSession();
//声明Criteria对象传入一个持久化类对象类型
Criteria criteria = session.createCriteria(User.class);
List result = criteria.list();
Iterator it = result.iterator();
添加查询条件:
//声明Criteria对象传入一个持久化类对象类型
Criteria criteria=session.createCriteria(Login.class);
//添加查询条件 Restrictions.eq是等于的意思,2个参数,第一个为持久化类的属性,第2个为比较的参数值
criteria.add(Restrictions.eq("username", "Tom"));
//查询使用list方法
result=criteria.list();
8、对于Maven的理解
maven主要是用来解决导入java类依赖的jar,编译java项目主要问题。
pom.xml文件中dependency属性管理依赖的jar包,而jar包包含class文件和一些必要的资源文件。
Maven主要做了两件事:
统一开发规范与工具
统一管理jar包
9、BeanUtils.copyProperties的注意事项
只能拷贝基础数据类型&&String
10、使用JsonObject生成和解析Json
json数据类型
Number 数字型
String 字符串型
Boolean 布尔型
Array 数组
Object 对象
private static void createJson() {
JSONObject obj = new JSONObject();
obj.put("name", "John");
obj.put("sex", "male");
obj.put("age", 22);
obj.put("is_student", true);
obj.put("hobbies", new String[] {"hiking", "swimming"});
//调用toString()方法可直接将其内容打印出来
System.out.println(obj.toString());
}
如果想要直观点看其内容,可以用一些在线的json解析器看
补充:使用JavaBean构建
private static void createJsonByJavaBean() {
PersonInfo info = new PersonInfo();
info.setName("John");
info.setSex("male");
info.setAge(22);
info.setStudent(true);
info.setHobbies(new String[] {"hiking", "swimming"});
JSONObject obj = new JSONObject(info);
System.out.println(obj);
}
JavaBean一定要有getter方法,否则会无法访问存储的数据。
解析Json
public static void main(String[] args) throws IOException {
File file = new File("src/main/java/demo.json");
String content = FileUtils.readFileToString(file);
//对基本类型的解析
JSONObject obj = new JSONObject(content);
System.out.println("name:" + obj.getString("name"));
System.out.println("sex:" + obj.getString("sex"));
System.out.println("age" + obj.getInt("age"));
System.out.println("is_student" + obj.getBoolean("is_student"));
//对数组的解析
JSONArray hobbies = obj.getJSONArray("hobbies");
System.out.println("hobbies:");
for (int i = 0; i < hobbies.length(); i++) {
String s = (String) hobbies.get(i);
System.out.println(s);
}
}
11、Query
1、分页查询
当数据量过大时,可能会导致各种各样的问题发生,例如:服务器资源被耗尽,因数据传输量过大而使处理超时,等等。最终都会导致查询无法完成。
解决这个问题的一个策略就是“分页查询”,也就是说不要一次性查询所有的数据,每次只查询一“页“的数据。这样分批次地进行处理,可以呈现出很好的用户体验,对服务器资源的消耗也不大。
分页参数:
pageIndex:当前页索引
pageSize:每页几条数据。
2、Query类的使用
分页查询:
Query query=session.createQuery("from User u where u.name=:name");
query.setParameter("name","zhansan1");
//指定从哪个对象开始查询,参数的索引位置是从0开始的,
query.setFirstResult(10);
// //分页时,一次最多产寻的对象数
query.setMaxResults(5);
List userList = query.list();
使用query对象,不需要写sql语句,但是写hql语句。
hql和sql区别:sql语句是通过数据库表和字段进行操作,hql是通过实体类和属性进行操作。
Query对象的使用
public void testQuery(){
SessionFactory sessionFactory= null;
Session session = null;
Transaction tx = null;
try {
//1.调用工具类获得sessionfactory
sessionFactory = HibernateUtil.getSessionFactory();
//2.获取session
session = HibernateUtil.getSession();
//3.开启事物
tx = session.beginTransaction();
//1.创建Query对象
//方法里面写hql语句
Query query = session.createQuery("from User");
//2.调用其中的方法得到结果
List list = query.list();
for(User user : list){
System.out.println(user);
}
//提交事物
tx.commit();
} catch (Exception e) {
tx.rollback();
}finally{
//关闭
sessionFactory.close();
}
}
hql语句的使用:
//查询中使用?,通过setParameter的方式可以防止sql注入
List students = (List)session.createQuery("select stu from Student stu where name like ?")
.setParameter(0, "%刘%")
.list();
***********
String hql ="update User set age=23 where age = 20"
Query query = session.createQuery(hql);
query.executeUpdate();
12、SQLQuery
hibernate的查询方式有HQL、Cretiria和SQL
Hibernate提供一个接口SQLQuery, 用于支持原生sql语句查询.
//1、基本查询
SQLQuery sqlQuery = session.createSQLQuery("select * from Customer");
List list = sqlQuery.list();
//2、封装到对象中
SQLQuery sqlQuery = session.createSQLQuery(" select * from Customer");
sqlQuery.addEntity(Customer.class);
List list = sqlQuery.list();
补充:Hibernate setResultTransformer
如果使用原生sql语句进行query查询时,hibernate是不会自动把结果包装成实体的。
有如下两个方法:
1、session.createSQLQuery(sql).addEntity(Class class);
2、session.createSQLQuery(sql).setResultTransformer(Transformers.aliasToBean(Clazz.class))
或者setResultTransformer(new AliasToBeanResultTransformer (Clazz.class))
Query query = sessionFactory
.getCurrentSession()
.createSQLQuery(sql.toString())
.setResultTransformer(
Transformers.aliasToBean(DepartmentEntity.class))
.List();
13、Clazz的使用
clazz表示某种类型
14、操作DOM
由于HTML文档被浏览器解析后就是一棵DOM树,要改变HTML的结构,就需要通过JavaScript来操作DOM。
始终记住DOM是一个树形结构。操作一个DOM节点实际上就是这么几个操作:
更新:更新该DOM节点的内容,相当于更新了该DOM节点表示的HTML的内容;
遍历:遍历该DOM节点下的子节点,以便进行进一步操作;
添加:在该DOM节点下新增一个子节点,相当于动态增加了一个HTML节点;
删除:将该节点从HTML中删除,相当于删掉了该DOM节点的内容以及它包含的所有子节点。
在操作一个DOM节点前,我们需要通过各种方式先拿到这个DOM节点。最常用的方法是document.getElementById()和document.getElementsByTagName()
JavaScript
Java
Python
Scheme
把
JavaScript
添加到var
js = document.getElementById('js'),
list = document.getElementById('list');
list.appendChild(js);
15、如何调用API接口
①找到要调用的API接口
②向指定URL添加参数发送请求
③对返回的字符串进行处理
后端的文档会写明:接口地址、返回格式以及请求方式
使用 HttpClient 封装post请求和get的请求
Get:
public static String doGet(String url) {
try {
HttpClient client = new DefaultHttpClient();
//发送get请求
HttpGet request = new HttpGet(url);
HttpResponse response = client.execute(request);
/**请求发送成功,并得到响应**/
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
/**读取服务器返回过来的json字符串数据**/
String strResult = EntityUtils.toString(response.getEntity());
return strResult;
}
}
catch (IOException e) {
e.printStackTrace();
}
return null;
}
Post:用于参数为Key—value形式的请求
public static String doPost(String url, Map params){
BufferedReader in = null;
try {
// 定义HttpClient
HttpClient client = new DefaultHttpClient();
// 实例化HTTP方法
HttpPost request = new HttpPost();
request.setURI(new URI(url));
//设置参数
List nvps = new ArrayList();
for (Iterator iter = params.keySet().iterator(); iter.hasNext();) {
String name = (String) iter.next();
String value = String.valueOf(params.get(name));
nvps.add(new BasicNameValuePair(name, value));
//System.out.println(name +"-"+value);
}
request.setEntity(new UrlEncodedFormEntity(nvps,HTTP.UTF_8));
HttpResponse response = client.execute(request);
int code = response.getStatusLine().getStatusCode();
if(code == 200){ //请求成功
in = new BufferedReader(new InputStreamReader(response.getEntity()
.getContent(),"utf-8"));
StringBuffer sb = new StringBuffer("");
String line = "";
String NL = System.getProperty("line.separator");
while ((line = in.readLine()) != null) {
sb.append(line + NL);
}
in.close();
return sb.toString();
}
else{ //
System.out.println("状态码:" + code);
return null;
}
}
catch(Exception e){
e.printStackTrace();
return null;
}
}
Post:用于参数为Json形式的请求
public static String doPost(String url, String params) throws Exception {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost(url);// 创建httpPost
httpPost.setHeader("Accept", "application/json");
httpPost.setHeader("Content-Type", "application/json");
String charSet = "UTF-8";
StringEntity entity = new StringEntity(params, charSet);
httpPost.setEntity(entity);
CloseableHttpResponse response = null;
try {
response = httpclient.execute(httpPost);
StatusLine status = response.getStatusLine();
int state = status.getStatusCode();
if (state == HttpStatus.SC_OK) {
HttpEntity responseEntity = response.getEntity();
String jsonString = EntityUtils.toString(responseEntity);
return jsonString;
}
else{
logger.error("请求返回:"+state+"("+url+")");
}
}
ajax调用
$.ajax({
type: "[POST](https://www.baidu.com/s?wd=POST&tn=67012150_cpr&fenlei=mv6quAkxTZn0IZRqIHcvrjTdrH00T1dbnj9BnAfkuhfsnWbYuj0v0ZwV5fKWUMw85HmLnjDznHRsgvPsT6KdThsqpZwYTjCEQLGCpyw9Uz4Bmy-bIi4WUvYETgN-TLwGUv3En1nzn1DzPjnd)",//传输方式
[url](https://www.baidu.com/s?wd=url&tn=67012150_cpr&fenlei=mv6quAkxTZn0IZRqIHcvrjTdrH00T1dbnj9BnAfkuhfsnWbYuj0v0ZwV5fKWUMw85HmLnjDznHRsgvPsT6KdThsqpZwYTjCEQLGCpyw9Uz4Bmy-bIi4WUvYETgN-TLwGUv3En1nzn1DzPjnd): "",//action路径
data: "",//传递参数,可有可无
success: function(msg){
//调用成功后执行操作
}
});
Web API 接口设计的总结
声明接口是Get还是Post
如果是增删改的接口,一般需要声明为POST方式提交数据,而且基于安全性的考虑,需要携带更多的参数。
接口与工厂的关系:
Car car=CarFactory.getSuperCar();
由工厂来提供实例化方法。
Oracle的jdbc调用:
Class.forName("oracle.jdbc.driver.OracleDriver";);
Connection conn=DriverManager.getConnection(jdbcurl,username,password);
SQLServer的jdbc调用:
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver");
Connection conn=DriverManager.getConnection(jdbcurl,username,password);
MySQL的jdbc调用:
Class.forName("com.mysql.jdbc.Driver");
Connection conn=DriverManager.getConnection(jdbcurl,username,password);
在这里,DriverManager就是工厂,通过getConnection()方法来生产出数据库连接对象Connection。Class.forName()是将一个类初始化,该方法会初始化化该Driver类。
16、JD-GUI反编译
怀疑项目没部署到服务器上
去服务器上下载包,JAR格式,用JD-GUI反编译一下
17、Access Token
18、DNS
域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。
19、127.0.0.1和localhost和本机IP
回环地址:
同一台主机上的两项服务若使用环回地址而非分配的主机地址,就可以绕开TCP/IP协议栈的下层。
127.0.0.0到127.255.255.255都是环回地址。
当IP层接收到目的地址为127.0.0.1的数据包时,不调用网卡驱动进行二次封装,而是立即转发到本机IP层进行处理
localhost首先是一个域名,也是本机地址,通常情况下都指向 127.0.0.1
wlan(无线网卡)
20、方便后端人员写前端界面的网站
http://www.ibootstrap.cn/
../ 当前文件的上一层路径
其它:
1、Java中的Runtime():Runtime 类代表着Java程序的运行时环境,每个Java程序都有一个Runtime实例,该类会被自动创建。
RuntimeException:运行时异常。
2、Service层与Dao层的区别:service层是面向功能的。严格的来说,比如在业务层new一个DAO类的对象,调用DAO类方法访问数据库,这样写是不对的,因为在业务层中是不应该含有具体对象,最多只能有引用,如果有具体对象存在,就耦合了。
3、Command+点击 约等于 command+option+B
Command+回车键
command+shift+回车