论文翻译:Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism
论文地址:https://www.aclweb.org/anthology/P18-1047.pdf
通讯作者主页:http://people.ucas.ac.cn/~zhaojun
论文出处:中国科学院大学
代码地址:https://github.com/xiangrongzeng/copy_re
文章标题:Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism(基于复制机制的端到端神经模型提取关联事实)ACL2018
Abstract
句子中的关系事实往往比较复杂。不同的关系三连词在一个句子中可能有重叠。根据句子的三重重叠程度,我们将句子分为三种类型,即正常重叠、完全重叠和单一性重叠。现有的方法主要集中在普通类上,不能准确提取关系三元组。在本文中,我们提出了一种基于复制机制的端到端学习模型,该模型可以从任意一个类的句子中联合提取相关事实。在译码过程中,我们采用了两种不同的译码策略:一种是采用一个联合译码器,另一种是采用多个独立译码器。我们在两个公共数据集中测试了我们的模型,我们的模型明显优于基线方法。
一、Introduction
近年来,为了构建大型结构知识库,人们在从自然语言文本中提取关系事实方面做了大量工作。关系事实通常表示为由两个实体(一个实体对)和它们之间的语义关系组成的三元组,例如< Chicago,country,US>。
到目前为止,大多数的方法主要集中在关系提取或分类的任务,识别两个预先分配的实体之间的语义关系。虽然取得了很大的进展(Hendrickx等,2010;曾等,2014;Xu et al., 2015a,b),他们都假设实体是预先识别的,而忽略了实体的提取。实体和关系的提取,早期的著作(Zelenko et al., 2003;Chan和Roth(2011)采用了流水线方式,首先进行实体识别,然后预测提取实体之间的关系。然而,流水线框架忽略了实体识别和关系预测的相关性(Li和Ji, 2014)。最近的研究试图联合提取实体和关系。于和林(2010);Li and Ji (2014);Miwa和Sasaki(2014)设计了几个复杂的特性来构建这两个子任务之间的桥梁。与其他自然语言处理(NLP)任务类似,它们需要复杂的特征工程,并且严重依赖于已有的NLP工具进行特征提取。
近年来,随着深度学习在许多NLP任务上的成功,它也被应用于相关事实的提取。曾等(2014);Xu等(2015a,b)使用CNN或RNN进行关系分类。Miwa和Bansal (2016);Gupta等人(2016);Zhang等人(2017)将关系提取任务视为端到端的(end2end)表格填充问题。Zheng等(2017)提出了一种新的标记模式,并采用基于递归神经网络(RNN)的序列标记模型来联合提取实体和关系。
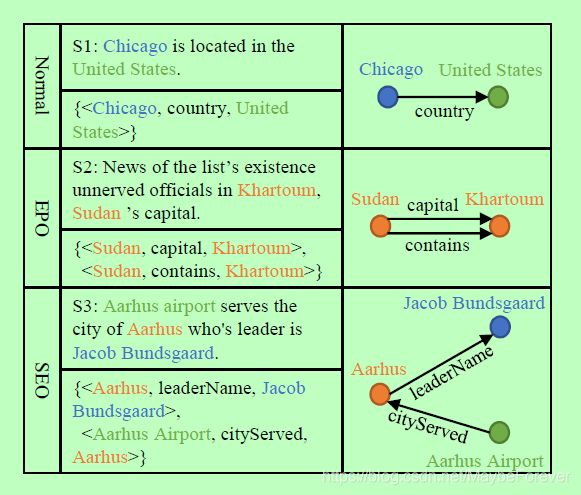
图一:正常重叠、完全重叠、单一重叠的例子。重叠的实体被标注为黄色。
然而,句子中的关系事实往往是复杂的。不同的关系三连词在一个句子中可能有重叠。这种现象使得上述方法,无论是基于深度学习的模型还是基于传统特征工程的联合模型,都无法准确提取出相关的三元组。一般情况下,根据我们的观察,我们将句子按照三重重叠程度分为三种类型,分别是Normal, EntityPairOverlap (EPO)和SingleEntityOverlap (SEO)。如图1所示,如果一个句子的三元组都没有重叠的实体,那么它就属于普通类。如果它的一些三元组有重叠的实体对,那么这个句子属于EntityPairOverlap类。如果一个句子的某些三元组有重叠的实体而这些三元组没有重叠的实体对,那么这个句子就属于单列重叠类。在我们的知识中,以往的方法大多集中于一般类型,很少考虑其他类型。即使是基于神经网络的联合模型(Zheng et al., 2017),它也只给一个单词分配一个标签,这意味着一个单词最多只能参与一个三元组。因此,三重重叠的问题实际上并没有得到解决。
为了解决上述挑战,我们的目标是设计一个模型,该模型可以从正常的、EntityPairOverlap和SingleEntityOverlap类的语句中提取三联体,包括实体和关系。为了处理三重重叠的问题,必须允许一个实体自由地参与多个三重。与以往的神经方法不同,我们提出了一种基于复制机制的序列-序列学习的end2end模型,该模型可以联合提取任意一个类的句子中的相关事实。该模型的主要组成部分包括编码器和解码器两部分。编码器将自然语言语句(源语句)转换为固定长度的语义向量。然后,解码器读取这个向量并直接生成三个一组。为了生成三元组,首先由解码器生成关系。其次,解码器采用复制机制,从源句中复制第一个实体(头实体)。最后,解码器从源语句中复制第二个实体(尾部实体)。这样就可以提取出多个三元组。具体来说,我们在解码过程中采用了两种不同的策略:使用一个统一的解码器(一个解码器)来生成所有的三元组,或者使用多个分离的解码器(多解码器),每个解码器生成一个三元组)。在我们的模型中,当一个实体需要参与不同的三元组时,它可以被多次复制。因此,我们的模型可以处理三连词重叠问题,并同时处理全句和单句重叠。此外,由于在单个end2end神经网络中提取实体和关系,我们的模型可以联合提取实体和关系。
我们工作的主要贡献如下:
- 提出了一种基于复制机制的基于序列-序列学习的end2end神经模型,用于从句子中提取关系事实,实现实体和关系的联合提取。
- 我们的模型可以通过复制机制来考虑关系三重重叠问题。在我们的知识中,有关三重重叠的问题从来没有被解决过。
- 我们在两个公共数据集上进行了实验。实验结果表明,我们的技术进步分别为39.8%和31.1%。
二、Related Work
Hendrickx等人(2010)通过给出带有注释实体的句子;曾等(2014);Xu等(2015a,b)将句子中的关系识别问题视为一个多类分类问题。Zeng等(2014)最早将CNN引入关系分类。Xu等人(2015a)和Xu等人(2015b)通过CNN或RNN学习最短依赖路径的关系表示。尽管这些模型取得了成功,但它们忽略了从句子中提取实体,不能真正提取关系事实。
通过给出一个没有任何注释实体的句子,研究人员提出了几种提取实体和关系的方法。基于管道的方法,如Zelenko et al.(2003)和Chan and Roth(2011),忽略了实体提取和关系预测的相关性。为了解决这一问题,提出了几种联合模型。早期作品(Yu and Lam, 2010;Li and Ji, 2014;Miwa和Sasaki(2014)需要复杂的特征工程过程,特征提取严重依赖于NLP工具。近期的模型,如Miwa和Bansal (2016);Gupta等人(2016);Zhang等(2017);Zheng等(2017)基于神经网络联合提取实体和关系。这些模型基于标记框架,该框架为单词或单词对分配关系标记。尽管它们取得了成功,但是这些模型都不能完全处理第一部分中提到的三重重叠问题。原因在于他们的假设,即一个单词(或一对单词)只能被分配一个关系标签。
本工作是基于复制机制的序列-序列学习,它已被用于一些NLP任务。Dong和Lapata(2016)提出了一种基于注意力增强的编码-解码器模型的方法,该方法对输入话语进行编码并生成其逻辑形式。Gu等(2016);He等(2017)将复制机制应用于句子生成。它们将一个段从源序列复制到目标序列。
三、Our Model
在本节中,我们介绍了一个基于复制机制的可微神经模型,它能够以一种end2end的方式提取多个相关事实。
我们的神经模型首先将一个变长句子编码成一个固定长度的向量表示,然后将这个向量解码成相应的关系事实(三元组)。解码时,我们可以用一个统一的译码器来解码所有的三元组,也可以用一个独立的译码器来解码每一个的三元组。我们分别将它们表示为一个解码器模型和多个解码器模型。
3.1、OneDecoder Model
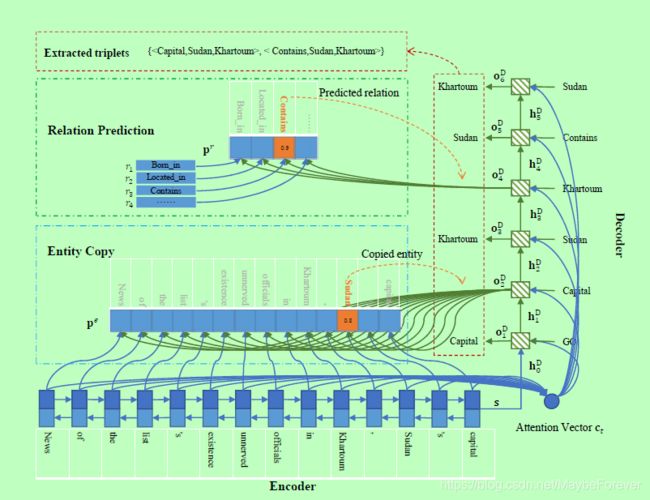
图二:一个解码器模型的整体结构。使用双向RNN对源语句进行编码,然后使用解码器直接生成三元组。对关系进行预测,并从源语句中复制实体。
3.1.1、Encoder
编码一个句子s = [w1,…,wn],其中wt表示第t个单词,n为源句长度,首先将其转化为矩阵X = [x1,…,xn],其中xt为第t个单词的嵌入。
标准的RNN编码器读取矩阵X,并且通过如下公式生成输出ot和隐藏状态ht:
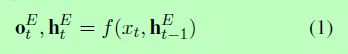
在上述公式中,f(.)表示编码器功能。
跟随(Gu et al., 2016),我们的编码器使用双向RNN (Chung et al., 2014)对输入的句子进行编码。前向和后向RNN分别得到输出序列。我们将对应的输出序列合并来表示每个位置上的单词。我们采用Oe来表示连接的结果,类似地,前向和后向RNN的串联隐藏状态作为句子的表示,采用s。
3.1.2、Decoder
解码器用于直接生成三元组。首先,解码器生成三元组的关系。其次,解码器从源句中复制一个实体作为三元组的第一个实体。最后,解码器从源语句中复制第二个实体。重复这个过程,解码器可以产生多个三元组。当所有有效的三元组生成后,解码器将生成NA三元组,这意味着“停止”,类似于神经语句生成中的“eos”符号。请注意,NA三元组由NA-关系和NA-实体对组成。
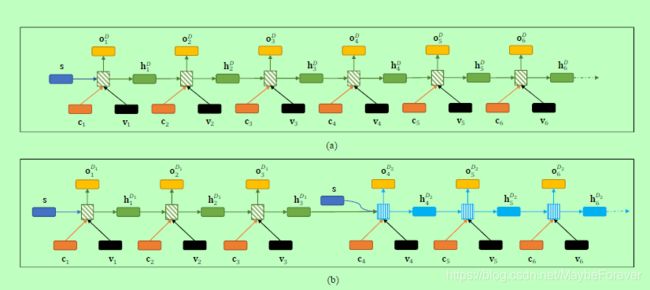
图三:一个解码器模型和多解码器模型的解码器的输入和输出。(a)是一个解码器模型的解码器。我们可以看到,只有一个解码器(带阴影的绿色矩形)被使用,这个编码器是用句子表示s初始化的。(b)是多解码器模型的解码器。有两个解码器(绿色矩形和带阴影的蓝色矩形)。用s初始化第一译码器;其他解码器用s和先前解码器的状态初始化。
如图3所示:在第t个时间步,我们计算解码器的输出ot和隐藏状态ht。
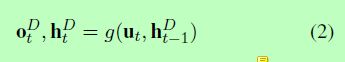
f(.)是表示解码器功能,并且ht-1表示第t-1个时间步上隐藏层状态。我们初始化h0代表源句子。
ut是第t个时间步上解码器的输入,计算方法如下:
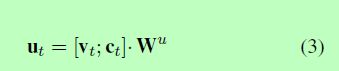
ct表示注意力向量并且vt是复制实体的嵌入或t-1时间步上关系的预测,Wu表示权重矩阵。
(1)Attention Vector
注意力向量ct的计算方法如下:
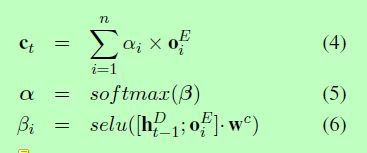
其中,oi表示第i个时间步上编码器的输出,α、β表示向量,Wc是向量的权重,selu(.)是激活函数。
当我们在第t(1<=t)个时间步上得到解码器输出ot之后,如果t%3=1(t=1,4,7,…),我们使用ot来预测一个关系,这意味着我们正在解码一个新的三元组。否则,如果t%3=2(t=2,5,8,…),我们使用ot从源句中复制第一个实体,如果t%3=0(t=3,6,9,…),我们复制第二个实体。
(2)Predict Relation
假设总共有m个有效关系。我们使用全连通层来计算置信向量qr = [qr1,…,qrm 所有有效关系:
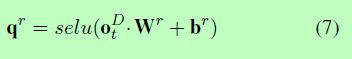
其中Wr为权重矩阵,br为偏差。当预测关系时,当模型试图生成NA-triplet时,预测NA-relation是可能的。考虑到这一点,我们计算NA-relation的置信值为:
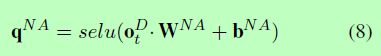
其中WNA为权重矩阵,bNA为偏差。然后我们将qr和qNA连接起来,形成所有关系(包括NA-relation)的置信向量,并应用softmax得到概率分布pr = [pr 1,…,pr m + 1]:
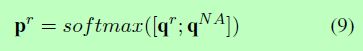
我们选择概率最大的关系作为预测关系,利用它的嵌入作为下一个时间步长输入vt+1。
(3)Copy the First Entity
要复制第一个实体,我们计算源句中所有单词的置信向量qe = [qe 1,…,qe n]:
![]()
We表示向量权重。与关系预测相似,我们将qe和qNA串联起来形成置信向量,应用softmax得到概率分布pe = [pe 1,…,pe n + 1]:
![]()
类似地,我们选择概率最高的单词作为预测单词,并使用它作为下一次的时间步长输入vt+1。
(4)Copy the Second Entity
复制第二个实体几乎与复制第一个实体相同。唯一的区别是在复制第二个实体时,我们不能再次复制第一个实体。这是因为在一个有效的三元组中,两个实体必须是不同的。假设第一个被复制的实体是原句中的第k个单词,我们引入一个带n (n是原句的长度)元素的掩码向量M,其中:

然后计算概率分布pe为:
![]()
其中⊕是元素乘法。就像复制第一个实体一样,我们选择概率最高的单词作为预测单词,并使用它作为下一次的时间步长输入vt+1。
3.2、MultiDecoder Model
多解码器模型是单解码器模型的扩展。主要的区别是当解码三元组时,多解码器模型用几个分开的解码器解码三元组。图3 (b)显示了多解码器模型的解码器的输入和输出。有两个解码器(带阴影的绿色和蓝色矩形)。解码器按顺序工作:第一解码器生成第一三元组,然后第二解码器生成第二个三元组。
与公式2类似,我们计算他t时间步长上的隐藏状态ht和第i个解码器的输出ot,公式如下:
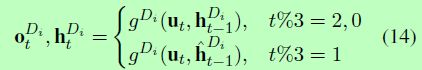
g(.)表示解码器,ut表示t时间步上解码器的输入(同公式3)。ht-1表示在t-1时间步长上第i个解码器的隐藏状态。h^t-1表示第i个解码器的初始隐藏状态,计算方法如下:
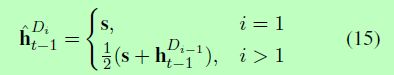
3.3、Training
一个解码器和多解码器模型都使用负对数似然损失函数进行训练。给定一批含有B个句子的数据S与目标结果Y,其中yi为si的目标结果,损失函数定义如下:
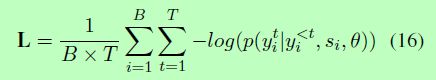
T是解码器的最大时间步长。p(x|y)表示给定y后x的条件概率。
四、Experiments
4.1、Dataset
为了评估我们的方法的性能,我们在两个广泛使用的数据集上进行了实验。
第一个是 《纽约时报》(New York Times, NYT)的数据集,它是通过远距离监控方法产生的(Riedel et al., 2010)。该数据集包含从294k 1987-2007年《纽约时报》新闻文章中抽取的118万个句子。共有24个有效关系。在本文中,我们将该数据集视为与Zheng等人(2017)相同的监督数据。我们过滤了100多个单词的句子和不包含正三联句的句子,剩下66195个句子。我们从其中随机选取5000个句子作为测试集,5000个句子作为验证集,其余的56195个句子作为训练集。
第二个是WebNLG数据集(Gardent等,2017)。它最初是为自然语言生成(NLG)任务而创建的。该数据集包含246个有效关系。在这个数据集中,一个实例包括一组三联体和几个标准句(由人工编写)。每个标准句都包含这个实例的所有三元组。在我们的实验中,我们只使用第一个标准句,如果在这个标准句中没有找到所有的三胞胎实体,我们就过滤掉这些实例。原点WebNLG数据集包含训练和发展集合。在我们的实验中,我们对待起源发展集作为测试集和随机分割原点为验证组和训练集训练。过滤和分离后,列车集包含5019实例,测试集包含703个实例和验证集包含500个实例。
NYT和WebNLG数据集中每个类的句子数如表1所示。值得注意的是,一个句子可以同时属于EntityPairOverlap类和SingleEntityOverlap类。
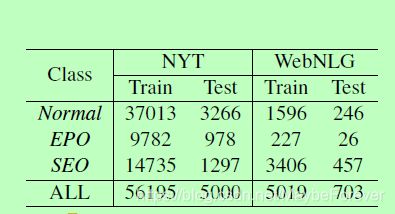
表一:正常、完整重叠(EPO)和单个重叠(SEO)类的句子数。值得注意的是,一个句子可以同时属于EPO类和SEO类。
4.2、Settings
在我们的实验中,对于这两个数据集,我们使用LSTM (Hochreiter和Schmidhuber, 1997)作为模型单元;单元数设置为1000;嵌入维数设置为100;批处理大小为100,学习率为0.001;最大时间步长T为15,这意味着我们预测每个句子最多有5个三胞胎(因此,在多解码器模型中有5个解码器)。这些超参数在验证集上进行调优。我们使用Adam (Kingma和Ba, 2015)来优化参数,当我们在验证集中找到最佳结果时,我们就停止训练。
4.3、Baseline and Evaluation Metrics
我们将我们的模型与NovelTagging模型(Zheng et al., 2017)进行了比较,后者在相关事实提取方面表现最好。我们直接运行Zheng等人(2017)发布的代码来获取结果。
在Zheng等人(2017)之后,我们使用了标准的微精度、召回率和F1分数来评估结果。当三元组的关系和实体都是正确的,则认为三元组是正确的。在复制实体时,我们只复制实体的最后一个字。当且仅当一个三元组的关系是三元组,且三元组有一个NA-entity对时,三元组才被认为是na -三元组。预测的na -三元组将被排除在外。
4.4、Results
表2显示了NovelTagging模型(Zheng et al., 2017)和我们的OneDecoder和MultiDecoder模型的精度、查全率和F1值。
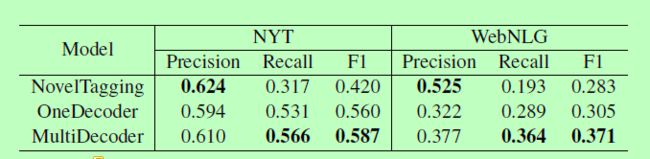
表二:不同模型在NYT数据集和WebNLG数据集上的结果。
可以看出,在NYT数据集中,我们的多解码器模型取得了最好的F1分数,为0.587。与NovelTagging的0.420相比,改进了39.8%。此外,我们的OneDecoder模型也优于NovelTagging模型。在webnlg数据集中,多解码器模型的F1得分最高(0.371)。多解码器和单解码器模型的性能分别比NovelTagging模型提高了31.1%和7.8%。这些观察结果验证了我们模型的有效性。
我们还可以观察到,在NYT和WebNLG的数据集中,NovelTagging模型的精度值最高,召回值最低。相比之下,我们的模型更加平衡。我们认为原因在于所提出的模型的结构。中篇小说标签法是通过给单词加标签来发现三元组的。然而,他们假设只能为一个单词分配一个标签。因此,一个单词最多只能参与一个三元组。因此,新颖标签模型只能召回少量的三元组,不利于召回性能的提高。与NovelTagging模型不同的是,我们的模型应用复制机制来查找一个三元组的实体,当一个单词需要参与多个不同的三元组时,可以多次复制这个单词。毫不奇怪,我们的模型召回更多的三元组,并实现更高的召回价值。进一步的实验证实了这一点。
4.5、Detailed Results on Different Sentence Types
为了验证我们的模型处理重叠问题的能力,我们在NYT数据集上进行了进一步的实验。
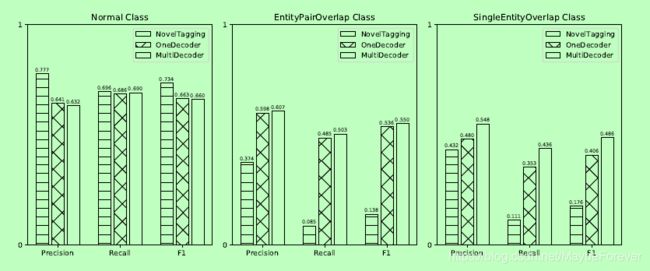
图四:在NYT数据集中正常、完整的roverlap和单列重叠类中,NovelTagging、OneDecoder和MultiDecoder模型的结果。
图4显示了NovelTagging、OneDecoder和MultiDecoder模型在Normal、EntityPairOverlap和SingleEntityOverlap类中的结果。正如我们所看到的,我们提出的模型在Entity-PairOverlap类和SingleEntityOverlap类中比NovelTagging模型执行得好得多。具体地说,我们的模型在所有指标上实现了更高的性能。另一个观察结果是NovelTagging模型在普通班中表现最好。这是因为NovelTagging模型更适合于普通类。然而,我们提出的模型更适合三重态重叠问题。此外,我们的模型仍然很难判断输入语句需要多少个三联体。结果,我们的正常类模型出现了丢失。然而,所提出的模型的整体性能仍然优于NoverTagging。此外,我们注意到EntityPairOverlap和SingleEntityOverlap类的整体提取性能低于正常类。这证明从EntityPairOverlap和singleentityoverlap类中提取关系事实比从普通类中提取更有挑战性。
我们还比较了该模型从包含不同数量的三元组的句子中提取关系的能力。我们将NYT测试集中的句子分为5个子类。每个类包含1、2、3、4或>= 5个三元组的句子。结果如图5所示。当从包含1个三元组的句子中提取关系时,中篇小说标注模型的效果最好。但随着三元组数目的增加,小说标记模型的性能显著下降。我们也可以观察到小说标记模型的回忆价值大幅下降。这些实验结果证明了我们的模型处理多重关系提取的能力。
4.6、OneDecoder vs. MultiDecoder
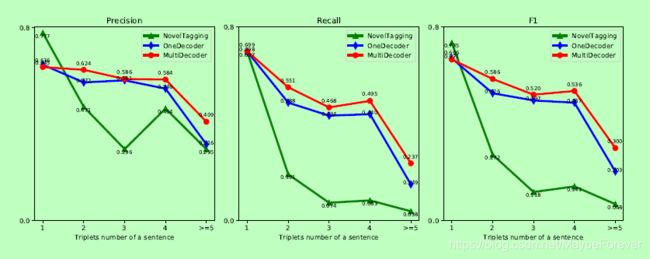
图五:从包含不同数量的三元组的句子中提取关系。我们将NYT测试集的句子分为5个子类。每个类包含1、2、3、4或>= 5个三元组的句子。
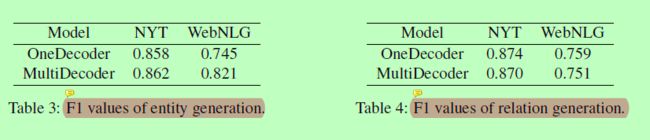
表三:实体生成的F1值
表四:关系生成的F1值
如之前的实验(表2、图4、图5)所示,我们的MultiDecoder模型比OneDecoder模型和NovelTagging模型的性能要好。为了找出多解码器模型优于单解码器模型的原因,我们分析了多解码器模型的实体生成和关系生成能力。实验结果见表3和表4。我们可以观察到,在NYT和WebNLG数据集上,这两个模型在关系生成方面具有可比性。然而,多解码器在生成实体时的性能要优于单解码器模型。我们认为这是因为多解码器模型利用不同的解码器生成不同的三元组,使得实体生成结果更加多样化。
Conclusions and Future Work
在本文中,我们提出了一个基于Seq2Seq学习框架和复制机制的end2end神经模型,用于关联事实的提取。我们的模型可以联合从句子中提取关系和实体,特别是当句子中的三元组重复时。此外,我们分析了不同的重叠类型,并采取了两种策略,包括一个统一解码器和多个分离解码器。我们在两个公共数据集上进行了实验,以评估我们的模型的有效性。实验结果表明,所建立的模型较基线方法有较好的性能,并能较好地提取三个类的相关事实。这个具有挑战性的任务还远远没有解决。我们今后的工作将集中于如何进一步提高业绩。另一个未来的工作是在其他NLP任务(如事件提取)中测试我们的模型。