循环、迭代、遍历和递归
loop [lu:p]、iterate ['itəreit]、traversal [træ'vɜ:sl]和recursion [rɪˈkɜ:ʃn]
分别翻译为:循环、迭代、遍历和递归。
循环是计算机科学运算领域的用语,也是一种常见的控制流程。
循环是一段在程序中只出现一次,但可能会连续运行多次的代码。
循环中的代码会运行特定的次数,或者是运行到特定条件成立时退出循环,或者是针对某一集合中的所有项目都运行一次。
在计算机科学中,For循环(英语:For loop)是一种编程语言的迭代陈述,能够让程式码反复的执行。
它跟其他的循环,如while循环,最大的不同,是它拥有一个循环计数器,或是循环变量。
这使得For循环能够知道在迭代过程中的执行顺序。
for (counter = 1; counter <= 5; counter++) //statement;
for(int i = 0; i < 5; i++){ //循环语句; }
for i = 1 to 5 '循环语句 Next i
在编程语言中,while循环(英语:While loop)是一种控制流程的陈述。
利用一个返回结果为布林值(布尔值)的表达式作为循环条件,当这个表达式的返回值为“true”(“真”)时,
则反复执行循环体内的程式码;若表达式的返回值为“false”(假),则不再执行循环体内的代码,继续执行循环体下面的代码。

unsigned int counter = 5; unsigned long factorial = 1; while (counter > 0) { factorial *= counter--; /*当满足循环条件(本例为:counter > 0)时会反复执行该条语句 */ } printf("%lu", factorial);
do-while循环(do while loop),也有称do循环,是计算机编程语言中的一种控制流程语句。
主要由一个代码块(作为循环体)和一个表达式(作为循环条件)组成,表达式为布尔(boolean)型。
循环体内的代码执行一次后,程序会去判断这个表达式的返回值,如果这个表达式的返回值为“true”(即满足循环条件)时,
则循环体内的代码会反复执行,直到表达式的返回值为“false”(即不满足循环条件)时终止。
程序会在每次循环体每执行一次后,进行一次表达式的判断。
一般情况下,do-while循环与while循环相似,但也有不同:do-while循环将先会执行一次循环体内的代码,再去判断循环条件。
所以无论循环条件是否满足,do-while循环体内的代码至少会执行一次。

int i = 5; do { i = i - 1; /*循环体*/ } while (i > 0); /*循环条件 */ System.out.println(i);
Foreach循环(Foreach loop)是计算机编程语言中的一种控制流程语句,通常用来循环遍历数组或集合中的元素。
以下代码用于循环打印名称为myArray的整型数组中的每个元素。
foreach (int x in myArray) { Console.WriteLine(x); }
C#不允许在foreach循环中改变数组或集合中元素的值,如以下代码将无法通过编译。
foreach (int x in myArray) { x++; //错误代码,因为改变了元素的值 Console.WriteLine(x); }
Java语言从JDK 1.5.0开始引入foreach循环。
以下代码用于循环打印myArray数组中的每个元素,java中的foreach循环使用for关键字,而非foreach。
for (int x : myArray){ System.out.println(x); }
与C#不同的是,Java允许在foreach循环中改变元素的值,以下代码不会编译出错。
for (int x : myArray){ x++; System.out.println(x); }
迭代 是重复反馈过程的活动,其目的通常是为了逼近所需的目标或结果。
每一次对过程的重复被称为一次“迭代”,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。
数学中的迭代可以指函数迭代的过程,即反复地运用同一函数计算,前一次迭代得到的结果被用于作为下一次迭代的输入。
即使是看上去很简单的函数,在经过迭代之后也可能产生复杂的行为,衍生出具有难度的问题。
在计算机科学中,迭代是程序中对一组指令(或一定步骤)的重复。
它既可以被用作通用的术语(与“重复”同义),也可以用来描述一种特定形式的具有可变状态的重复。
在第一种意义下,递归是迭代的一个例子,但是通常使用一种递归式的表达。比如用0!=1,n!=n*(n-1)!来表示阶乘。而迭代通常不是这样写的。
在第二种(更严格的)意义下,迭代描述了在指令式编程语言中使用的编程风格。与之形成对比的是递归,它更偏向于声明式的风格。
这里是一个依赖于破坏性赋值的迭代的例子,以指令式的伪代码写成:
var i, a = 0 // 迭代前初始化 for i from 1 to 3 // 循环3次 { a = a + i // a的值增加i } print a // 打印出数字6
在这个程序片段中,变量i的值会不断改变,依次取值1、2和3。这种改变赋值——或者叫做可变状态——是迭代的特征。
遍历 是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问题。
遍历在二叉树上最重要的运算之一,是二叉树上进行其它运算之基础。当然遍历的概念也适合于多元素集合的情况,如数组。
在计算机科学里,树的遍历是指通过一种方法按照一定的顺序访问一颗树的过程。
对于二叉树,树的遍历通常有四种:先序遍历、中序遍历、后序遍历、广度优先遍历。
(前三种亦统称深度优先遍历)对于多叉树,树的遍历通常有两种:深度优先遍历、广度优先遍历。
图的遍历方法有深度优先搜索法和广度(宽度)优先搜索法。
深度优先搜索算法(Depth-First-Search),是搜索算法的一种。
是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。
这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,
整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,
利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。
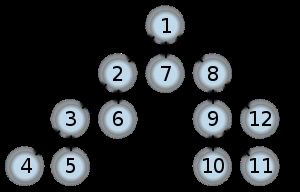
广度优先搜索算法(英语:Breadth-First-Search),是一种图形搜索算法。
又译作宽度优先搜索,或横向优先搜索,简称BFS,
简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
广度优先搜索的实现一般采用open-closed表。BFS是一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。
换句话说,它并不考虑结果的可能位址,彻底地搜索整张图,直到找到结果为止。BFS并不使用经验法则算法。
广度优先搜索算法具有完全性。这意指无论图形的种类如何,只要目标存在,则BFS一定会找到。
然而,若目标不存在,且图为无限大,则BFS将不收敛(不会结束)
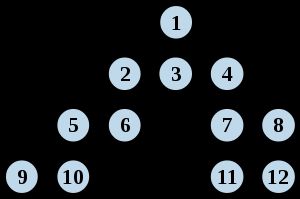
广度优先遍历是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜索;
而深度优先遍历是将某一条枝桠上的所有节点都搜索到了之后,才转向搜索另一条枝桠上的所有节点。
然后再以此邻结点为顶点,继续找它的下一个新的顶点进行访问,重复此步骤,直到所有结点都被访问完为止。
访问完后再访问这些结点中第一个邻接点的所有结点,重复此方法,直到所有结点都被访问完为止。
后者从顶点开始访问该顶点的所有邻接点再依次向下,一层一层的访问。
递归(英语:recursion)在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。
递归式方法可以被用于解决很多的计算机科学问题,因此它是计算机科学中十分重要的一个概念。
绝大多数编程语言支持函数的自调用,在这些语言中函数可以通过调用自身来进行递归。
计算理论可以证明递归的作用可以完全取代循环,因此在很多函数编程语言(如Scheme)中习惯用递归来实现循环。
尾部递归 是一种编程技巧。
递归函数是指一些会在函数内调用自己的函数,如果在递归函数中,递归调用返回的结果总被直接返回,则称为尾部递归。
尾部递归的函数有助将算法转化成函数编程语言,而且从编译器角度来说,亦容易优化成为普通循环。
这是因为从电脑的基本面来说,所有的循环都是利用重复移跳到代码的开头来实现的。
如果有尾部归递,就只需要叠套一个堆栈,因为电脑只需要将函数的参数改变再重新调用一次。
利用尾部递归最主要的目的是要优化,例如在Scheme语言中,明确规定必须针对尾部递归作优化。
可见尾部递归的作用,是非常依赖于具体实现的。
递归是简单的重复调用自己,而迭代则必须有新值出现,而且这个新值是由旧值得来的。
http://www.ibm.com/developerworks/cn/linux/l-recurs.html
计算机科学的新学生通常难以理解递归程序设计的概念。递归思想之所以困难,原因在于它非常像是循环推理(circular reasoning)。
它也不是一个直观的过程;当我们指挥别人做事的时候,我们极少会递归地指挥他们。
对刚开始接触计算机编程的人而言,这里有递归的一个简单定义:当函数直接或者间接调用自己时,则发生了递归。
递归的经典示例
计算阶乘是递归程序设计的一个经典示例。计算某个数的阶乘就是用那个数去乘包括 1 在内的所有比它小的数。
例如,factorial(5) 等价于 5*4*3*2*1,而 factorial(3) 等价于 3*2*1。您很可能会像这样编写阶乘函数:
int factorial(int n) { return n * factorial(n - 1); }
不过,这个函数的问题是,它会永远运行下去,因为它没有终止的地方。函数会连续不断地调用 factorial。
当计算到零时,没有条件来停止它,所以它会继续调用零和负数的阶乘。因此,我们的函数需要一个条件,告诉它何时停止。
由于小于 1 的数的阶乘没有任何意义,所以我们在计算到数字 1 的时候停止,并返回 1 的阶乘(即 1)。因此,真正的递归函数 类似于:
int factorial(int n) { if(n == 1) { return 1; } else { return n * factorial(n - 1); } }
可见,只要初始值大于零,这个函数就能够终止。停止的位置称为 基线条件(base case)。
基线条件是递归程序的 最底层位置,在此位置时没有必要再进行操作,可以直接返回一个结果。
所有递归程序都必须至少拥有一个基线条件,而且 必须确保它们最终会达到某个基线条件;
否则,程序将永远运行下去,直到程序缺少内存或者栈空间。
尾部递归(Tail-recursive)函数
对于递归函数的使用,人们所关心的一个问题是栈空间的增长。确实,随着被调用次数的增加,某些种类的递归函数会线性地增加栈空间的使用
不过,有一类函数,即 尾部递归 函数,不管递归有多深,栈的大小都保持不变。
http://stackoverflow.com/questions/3935501/tail-recursion-in-c
static unsigned factorial_helper( unsigned input, unsigned acc ) { if ( input == 0 ) { return acc; } return factorial_helper( input - 1, acc * input ); } unsigned factorial( int input ) { if ( input < 0 ) { do_something_bad( ); } return factorial_helper( input, 1 ); }
When doing tail recursive functions (especially tail recursive functions)
it is often helpful to have a helper function in addition to another function which has a more friendly interface.
The friendly interface function really just sets up the less friendly function's arguments.
By passing an accumulator value you avoid having to use pointers or do any computations upon returning from called functions,
which makes the functions truely tail recursive.
http://stackoverflow.com/questions/16115657/is-this-function-really-tail-recursive
int factorial( int n ) { return factorial2( n, 1 ); } int factorial2( int n, int accum ) { if ( n < 1 ) { return accum; } else { return factorial2( n - 1, accum * n ); } }
Tail Recursive is a special case of recursion in which the last operation of the function is a recursive call.
In a tail recursive function, there are no pending operations to be performed on return from a recursive call.
The function you mentioned is not a tail recursive because there is a pending operation
i.e multiplication to be performed on the return from a recursive call. In case you did this:
int factorial( int n, int result ) { if ( n > 1 ) { /* Recursive case */ return factorial( n - 1, n * result ); } else { /* Base case */ return result; } }