IOC总结
1. IOC概述
三个问题:
IOC是什么
- 为什么用它
- 怎么用
1.1 是什么?
两个概念:控制反转,依赖注入
来看一下传统的干活方式:在对象单一职责原则的基础上,一个对象很少有不依赖其他对象而完成自己的工作,所以这个时候就会出现对象之间的依赖。而体现在我们的开发中,就是需要什么对象的时候,就创建什么对象,此时对象创建的控制权在我们自己手里。当对象创建的太多的时候,就会出现一个对象更改,就得更改所有依赖它的对象,耦合性大。自主性体现的同时也出现了对象耦合严重的情况。
这个时候,我们就会思考,能不能我们在用的时候直接拿到这个对象去用,而将创建对象的能力交给第三方,这样我们就不需要关心对象是怎么创建的了。即将自己的控制权交出去。这就是控制反转
这个时候,就会有另一个问题产生了,对象怎么才能直接被我们拿来用呢。对象创建的时候,我们把这个对象注入到这个对象中,然后就可以使用了。这就是依赖注入
另一个问题,耦合性怎么被解决掉的?通过控制反转我们仅仅使用了这个对象,如果对象发生了修改,我们仅仅需要修改第三方创建对象的方式即可,这个时候难道还会出现所谓的对象耦合吗?
完成这些工作的就是IOC容器,它帮助我们创建对象,然后在对象被使用的时候,将对象注入到这个对象中。而由于IOC创建对象是通过反射来创建的,所以其速度不如直接new对象
还不理解???放心,听笔者讲一个故事,笔者最喜欢讲故事了
前段时间,天气逐渐回暖,鉴于家里没有短袖的情况,笔者只能选择购买了。这个时候笔者有两种选择,第一、去生产衣服的厂家直接去买(便宜);第二、去实体店或者网店购买(较昂贵)。之后,由于笔者属于宅男大军的一员,直接网上购物。
这个场景就是一个典型的控制反转的过程。笔者不需要关注衣服怎么生产的,而是仅仅去淘宝(IOC容器)上,寻找自己想要的衣服(对象),然后直接拿过来用即可。但是由于存在中间商赚差价,所以价格更贵(时间更长)
最后两句话:
控制反转:将自己的控制权交给自己信任的第三方,甲乙之间不存在依赖关系
依赖注入:开放一个端口留给A,然后在需要的时候,将B注入到A中。
1.2 为什么用
在上面,笔者已经很清晰的描述了为什么要使用IOC,主要原因就是由于对象之间的耦合。
1.3 怎么用
1.3.1 XML
通过书写XML配置文件,向容器中添加需要注入的Bean
1.3.2 Annotation
通过@Configuration注解指定配置类。
2. IOC架构

一个图搞定,这个就是IOC的架构思路,这不是其执行流程图。
我们接下来一步一步来解读。
2.1 白话版
在第一章中我们了解了IOC是来帮助我们管理和创建对象的。
这个时候我们需要一个承载我们需要创建信息的容器,即图中的XML或者注解,那么有了我们自己的BeanDefiniton信息以后,我们需要一个接口用来读取这些信息,于是出现了BeanDefinitionReader用来读取我们自己的Bean信息。
那么我们需要考虑一个问题了,那么多的对象怎么生产呢?
答案就是工厂模式。Spring默认的工厂是DefaultListableBeanFactory,没错,Spring中的所有对象(容器对象和我们自己创建的对象)都是由他创建的。大批量生产对象
这个时候又有了一个问题,我们不想通过BeanFactory直接生产了,需要对这个工厂进行一些特定处理,于是出现了BeanFactoryPostProcessor,用来对工厂做一些特定的处理。我们自己可以通过实现这个接口,进行自定义BeanFactory。又有兄弟说了:我想单独创建一些我喜欢的对象,安排,FactoryBean诞生了,它可以帮助我们创建一个我们需要的对象(第四部分详细解释他们之间的区别)。
那又有兄弟说了:我想让统一的对象创建之前按照我的方式进行一些特殊的行为,简单,安排
BeanPostProcessor出现了,他提供了两个方法:一个在对象实例化之后初始化之前,执行内部的Before方法,在初始化之后,执行After方法。(Bean生命周期,第四部分详解)
这个时候有兄弟有疑问了,不是说BeanPostProcessor在创建对象之前执行吗?怎么是创建完毕以后才执行的Before方法。
如果各位兄弟了解过指令重排序这个概念,那么一定会听过一个案例,创建一个对象需要三步
- 创建空间(实例化)
- 初始化
- 赋值
其中在初始化和赋值会出现指令重排序
根据这个点,应该可以get到一个点,实例化和初始化不一样。
所以又引出了一个点,我们对Bean进行一些操作,怎么操作,肯定是修改属性,或者添加一些属性等等,需要等待其在堆中开辟空间即实例化完成以后执行吧。
所以BeanPostProcessor的before方法在实例化之后执行,初始化之前执行。
经历过前面一大堆的操作以后,终于我们的对象进入我们兜里了(容器里)。
关于销毁,一般情况下我们通过ApplicationContext拿不到其销毁方法,只能通过其子类实现获取,关于销毁同样的流程,先执行一个销毁之前的操作,然后再销毁。
2.2 实际工作流程
看过Spring源码或者听过的都知道里面有一个方法叫做refresh,他完成了好多事情。当然他的行为也代表了整个IOC容器加载和实例化对象的过程。第三章的代码解读中我们仔细看

执行过程:
- 加载配置文件,初始化系统环境
Environment接口 - 准备上下文环境,初始化一些配置资源
- 创建一个工厂
- 为工厂添加各种环境
- 获取子类自己重写的
BeanFactoryPostProcessor - 执行容器和我们自己的
BeanFactoryPostProcessor - 注册
BeanPostProcessor - 国际化处理
- 转播器
- 子类初始化
Bean - 注册监听器,观察者模式
- 完成
Bean创建 - 发布相应的事件,监听器
3. IOC源码解读
写在之前:IOC的源码比较复杂,所以个人建议视频方式学习,大家可以B站搜索 阁主梧桐(笔者认为讲的不错的一个解读),如果大家不喜欢视频的方式,又想深度学习IOC源码那么推荐 程序员囧辉它的博客对于IOC的讲解非常深入。另外本文接下来的Spring源码,主要是通过图示的方法梳理其流程,作者水平有限。如有错误请留言。
3.1 上下文配置启动
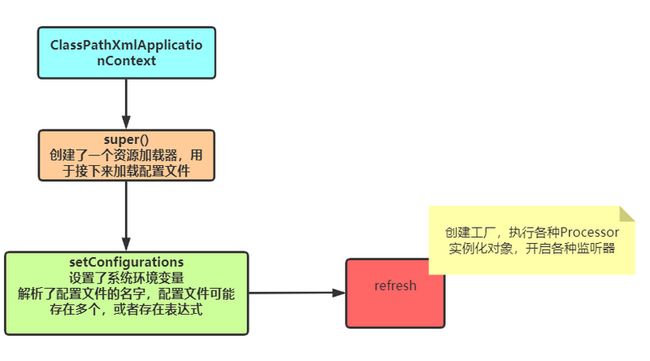
在创建ClassPathXmlApplicationContext的时候,构造方法中执行了这些方法。
说白了,加载了一个解析配置文件路径的加载器;然后又通过系统环境变量拿到这个配置文件,进行一些配置文件的去空格,转换表达式等等操作(没有进行解析);最后就是那个被我标成红色东东,refresh方法中它完成了几乎所有的工作。下面细聊
3.2 refresh

这个方法几乎完成了所有的操作,创建工厂,执行Processor等等,实例化对象,开启事件监听等等。
接下来细聊
3.3.1 prepareRefresh()
这个方法的主要作用是为应用上下文的刷新做一些准备性的工作。校验资源文件,设置启动时间和活跃状态等。
3.3.2 obtainFreshBeanFactory()

可以get到,它主要就是创建了一个工厂BeanFactory,并且解析了配置文件,加载了Bean定义信息(面试的时候直接答这个点就够了,如果想说的可以将下面的bean信息加载聊聊)
没错,标红的就是咱接下来细聊的点

这个就是加载配置文件的过程,注意:此时仍然没有解析,解析在标红的下面

这个就是读取的过程,具体解析流程来自parse中,这个直接调用了Java中的解析XML的类库,有兴趣自行翻阅,最后返回了一个Document对象。
通过Document对象,读取内部的标签,执行不同的方法,逻辑和MyBatis中解析配置文件的思想相同,大家自行翻阅。
此时所有的Bean定义信息都被保存到了BeanDefinitionRegistry接口,然后走子类DefaultListableBeanFactory工厂的注册方法
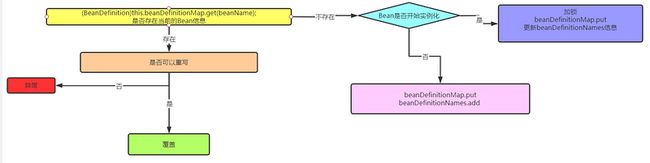
3.3.3 prepareBeanFactory(beanFactory)
为BeanFactory准备一些环境,方便在实例化的时候使用,同时添加容器自己的BeanPostProcessor

3.3.4 postProcessBeanFactory
留给子类扩展的BeanFactoryPostProcessor,
3.3.5 invokeBeanFactoryPostProcessors(beanFactory)
这个类,涉及到了两个接口。
BeanFactoryPostProcessorBeanDefinitionRegistryPostProcessor接口,这个接口是BeanFactoryPostProcessor的子接口,它的优先级比BeanFactoryPostProcessor更高
它的总体执行流程是:先执行BeanDefinitionRegistryPostProcessor的BeanFactoryPostProcessor,然后再执行BeanFactoryPostProcessor
下图是BeanDefinitionRegistryPostProcessor接口的处理过程
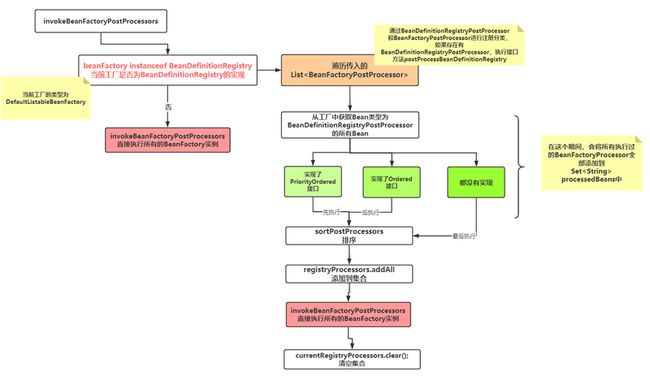
BeanFactoryPostProcessor的处理逻辑
总逻辑就是先分类,已经处理过的直接跳过,没有处理过的,分类处理,逻辑和上面的相同。
3.3.6 registerBeanPostProcessors
这个方法的逻辑和上面的一样,只不过上面是直接执行了BeanFactoryPostProcessor,而这个仅仅注册没执行。
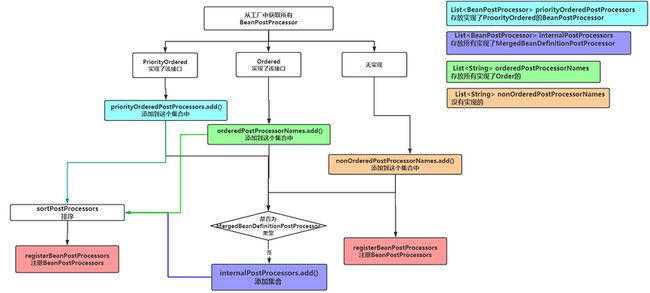
首先拿到工厂中所有的BeanPostProcessor类型的Bean,然后分类处理,排序注册。
3.3.7 initMessageSource()
执行国际化内容
3.3.8 initApplicationEventMulticaster
创建了一个多播器,为添加Listener提供支持。
主要逻辑:
- 容器中是否存在
applicationEventMulticaster,如果存在直接注册 - 如果不存在,创建一个
SimpleApplicationEventMulticaster,注册到容器中。
3.3.9 onRefresh()
子类扩展
3.3.10 registerListeners()
观察者模式的实现
protected void registerListeners() {
// 拿到当前容器中的监听器,注册到多播器中
for (ApplicationListener listener : getApplicationListeners()) {
getApplicationEventMulticaster().addApplicationListener(listener);
}
//拿到容器中为监听器的Bean,注册
String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false);
for (String listenerBeanName : listenerBeanNames) {
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
}
// 清空开始的事件,到广播器中
Set earlyEventsToProcess = this.earlyApplicationEvents;
this.earlyApplicationEvents = null;
if (earlyEventsToProcess != null) {
for (ApplicationEvent earlyEvent : earlyEventsToProcess) {
getApplicationEventMulticaster().multicastEvent(earlyEvent);
}
}
} 3.3.11 finishBeanFactoryInitialization
这一部分的内容太多了,所以采用代码和图解的方式来讲解。
/**
* Finish the initialization of this context's bean factory,
* initializing all remaining singleton beans.
在上下文工厂中完成所有Bean 的初始化
*/
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 初始化上下文转换服务Bean
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
//如果不存在前入值解析器,则注册一个默认的嵌入值解析器,主要是注解属性解析
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// 初始化LoadTimeWeaverAware
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
//实例化,重点
beanFactory.preInstantiateSingletons();
}下图是创建Bean的主要流程

按照途中的序号一个一个说:
BeanDefinition是否需要合并。BeanDefinition根据不同类型的配置文件信息,会将Bean封装到不同的Bean信息定义类中。比如我们常用的配置文件版的GenericBeanDefinition;注解扫描版的ScannedGenericBeanDefinition等等。
而在这个过程中就出现了,父定义和子定义,我们需要在实际处理定义信息的时候进行合并处理,主要有一下三个方面
- 存在父定义信息,使用父定义信息创建一个
RootBeanDefinition,然后将自定义信息作为参数传入。 - 不存在父定义信息,并且当前
BeanDefinition是RootBeanDefintion类型的,直接返回一份RootBeanDefintion的克隆 - 不存在父定义信息,并且当前
BeanDefintion不是RootBeanDefintiton类型的,直接通过该BeanDefintion构建一个RootBeanDefintion返回
上面的流程也是源码中的执行流程

isFactoryBean。判断是否为FactoryBean
简单介绍一下:FactoryBean是让开发者创建自己需要Bean接口。内部提供了三个方法
T getObject() throws Exception;//返回的Bean信息
Class getObjectType();//返回的Bean类型
default boolean isSingleton() {return true;}//是否单例当我们通过GetBean直接该Bean的时候,获取到的是该工厂指定返回的Bean类型。如果想要获取该Bean本身,需要通过一个前缀获得&
@Override
public boolean isFactoryBean(String name) throws NoSuchBeanDefinitionException {
String beanName = transformedBeanName(name); //解析真正的BeanName
Object beanInstance = getSingleton(beanName, false);//获取容器中的bean
if (beanInstance != null) {//如果容器中存在,直接返回该Bean是否为FactoryBea类型
return (beanInstance instanceof FactoryBean);
}
//没有Bean信息,检查这个Bean信息
if (!containsBeanDefinition(beanName) && getParentBeanFactory() instanceof ConfigurableBeanFactory) {
// 从父工厂中获取
return
((ConfigurableBeanFactory) getParentBeanFactory()).isFactoryBean(name);
}
//MergedBeanDefinition来检查beanName对应的Bean是否为FactoryBean
return isFactoryBean(beanName, getMergedLocalBeanDefinition(beanName));
}再来看一个点,这个就是从容器中获取Bean的主要方法,也是解决循环依赖的逻辑
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//查看当前容器中是否存在该Bean
Object singletonObject = this.singletonObjects.get(beanName);
//如果不存在,且当前Bean正在被创建
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从早期的容器中获取Bean
singletonObject = this.earlySingletonObjects.get(beanName);
//如果早期容器也没有且允许创建早期引用
if (singletonObject == null && allowEarlyReference) {
//获取该Bean的ObjectFactory工厂
ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
//如果当前工厂不为空
if (singletonFactory != null) {
//创建一个对象实例,此时处于半初始化状态
singletonObject = singletonFactory.getObject();
//添加到早期引用中
this.earlySingletonObjects.put(beanName, singletonObject);
//移除创建早期引用的工厂,因为该Bean已经创建且添加到了早期容器中,不需要再次进行创建了。
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}来聊一下它是怎么解决循环引用的?
它引入了一个三级缓存的概念
/**存放了所有的单例Bean */
private final Map singletonObjects = new ConcurrentHashMap<>(256);
/** 存放了Bean创建需要的ObejctFactory */
private final Map> singletonFactories = new HashMap<>(16);
/** 存放了早期创建的Bean,此时的Bean没有进行属性赋值,仅仅通过构造方法创建了一个实例 */
private final Map earlySingletonObjects = new HashMap<>(16);
//正在创建的Bean
private final Set singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16)); 在发生循环引用的时候,它首先通过ObejctFactory工厂将Bean创建出来,此时的对象并没有进行属性赋值,仅仅在堆中开辟了空间。然后将此时的Bean添加到earlySingletonObjects容器里,也就是说这个容器中保存的Bean都是半成品。而在之后的属性赋值中,由于对象为单例的,所以其引用地址不会发生变化,即对象最终是完整的。
getBean。通过这个方法直接创建了所有的对象,这也是Spring最核心的方法了
先来看一下它整体的一个流程

它的主要逻辑是:先拿到当前要实例化的Bean的真实名字,主要是为了处理FactoryBean,拿到以后,从当前容器中看是否已经创建过该Bean,如果存在直接返回。
如果不存在,获取其父工厂,如果父工厂不为空,而且当前容器中不存在当前Bean的信息,则尝试从父工厂中获取Bean定义信息,进行Bean实例化
如果父工厂为空,将当前Bean信息存放到alreadyCreated缓存中。
获取当前Bean的合并信息(getMergedLocalBeanDefinition),查看当前Bean是否存在依赖,如果存在则判断当前Bean和依赖Bean是否为循环依赖,如果不是循环依赖则先创建依赖Bean
判断当前Bean的作用域。
如果当前Bean是单例对象,直接创建Bean实例
如果当前Bean是多例对象,将当前Bean信息添加到正在创建多例缓存中,创建完毕以后移除
如果当前Bean是其他类型,如Requtst,Session等类型,则自定义一个ObejctFacotry工厂,重写getObject方法,创建对象
对象创建以后,判断当前对象是否为自己需要的对象,如果是直接返回;如果不是进行类型转换,如果类型转换失败,直接抛异常
接下来看一眼CreateBean的执行

这个方法主要完成的事情是:通过Bean的名字拿到对应的Class对象;如果当前Bean获取到的Class对象不为空且该RootDefintiton可以直接获取到该Bean,克隆一份Bean定义信息,方便之后使用。
验证当前Bean上的@Override信息。执行BeanPostProcessor,返回一个代理对象(如果存在代理的话)
如果不存在代理,则直接创建Bean
接下来我们来聊一下这个玩意——resolveBeforeInstantiation
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
// Make sure bean class is actually resolved at this point.
//当前定义信息不是合并,且存在Bean增强器
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//获取Bean的Class类型
Class targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
//如果不为null,则执行前置处理器
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
//如果前置处理器不为null,则后置处理器执行,跳过spring默认初始化
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
//代表已经再实例化之前进行了解析
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}来吧,继续,看一下那个前置处理器逻辑
protected Object applyBeanPostProcessorsBeforeInstantiation(Class beanClass, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
//拿到工厂中的所有的BeanPostProcessor
if (bp instanceof InstantiationAwareBeanPostProcessor) {
//找到所有我们需要的增强器
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 返回一个代理实例
Object result = ibp.postProcessBeforeInstantiation(beanClass, beanName);
if (result != null) {
return result;
}
}
}
return null;
}后置处理器就不看了,就调用了所有的后置处理器,然后执行了一遍,没有其他逻辑。
接下来继续我们的正题:doCreateBean

其大致流程如上图:
先判断以后是否单例,然后从FactoryBean缓存中看一下是否存在正在创建的Bean,如果存在拿出,如果不存在则创建一个当前Bean的包装类实例。然后拿到这个类的实例和实例类型,执行以后后置处理器。
当前Bean是否为单例,是否允许循环依赖,时候正在进行创建,如果是,创建一个当前Bean的ObejctFactory以解决循环依赖的问题
填充Bean的属性,进行Bean的实例化。
查看早期容器缓存中(缓存中的二级缓存中是否有该Bean)。如果有,则说明存在循环依赖,则进行处理
先看循环依赖吧
if (earlySingletonExposure) {
//从早期的Bean容器中拿到实例对象,此时的Bean必然存在循环依赖
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
} else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
//获取依赖的全部Bean信息
String[] dependentBeans = getDependentBeans(beanName);
Set < String > actualDependentBeans = new LinkedHashSet < > (dependentBeans.length);
for (String dependentBean: dependentBeans) {
//清除这些Bean信息,此时的Bean已经是脏数据了
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
//无法清理存入actualDependentBeans中
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException
}
}
}
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
} catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}接着来,createBeanInstance
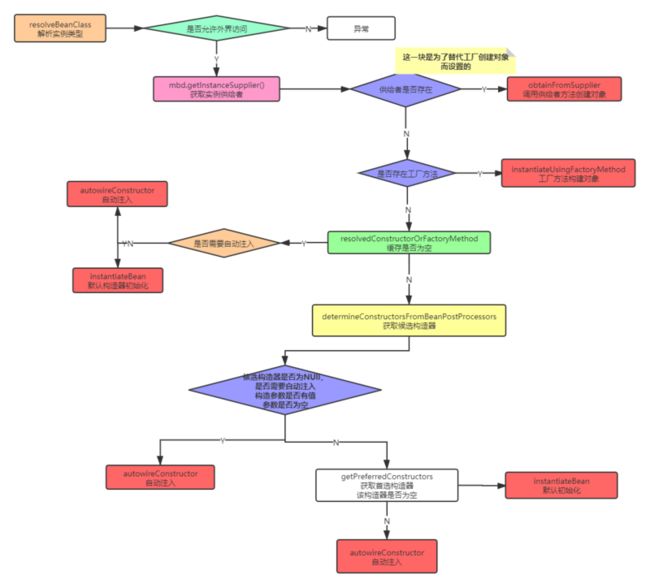
Spring提供了三种方式创建对象的包装:
- 通过供给者对象对象直接创建。
obtainFromSupplier - 通过工厂方法直接创建。
默认创建。
- 构造方法是否需要自动注入
- 构造方法不需要自动注入,调用默认的构造方法
这个方法执行完毕以后,你应该知晓的一个点是:此时对象实例已经创建了,剩下的就是执行一系列增强器和初始化方法,属性填充等等。
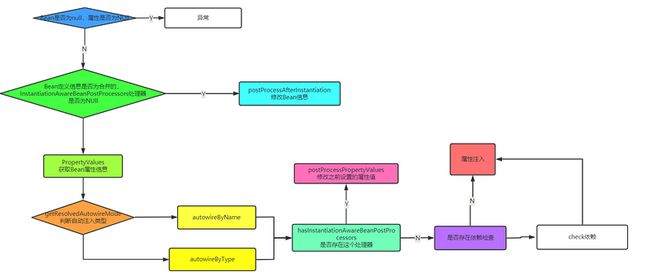
我们按照代码执行顺序来,属性填充即populateBean
这个方法执行逻辑:
首先判断传入的Bean是否为null,如果为null则判断Bean定义信息中是否存在属性值,如果存在,异常;如果不存在跳过
当前Bean定义信息是否为合并以后的,如果是且此时的工厂中存在InstantiationAwareBeanPostProcessors,那么在属性填充之前进行修改Bean的信息
拿到所有的属性值,解析属性值的自动注入方式,Type或者Name,进行自动注入
判断是否存在InstantiationAwareBeanPostProcessors,修改之前设置的属性
判断是否存在依赖检查,检查依赖
属性赋值
接下来看执行初始化方法,就是调用BeanPostprocessor,init等方法
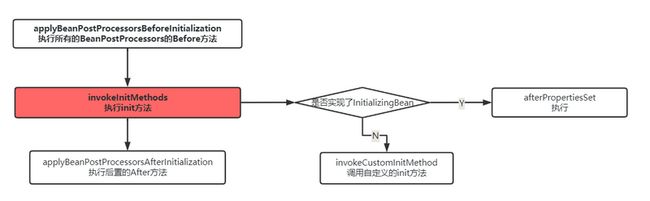
这个就是这个方法的执行流程图,相信到这个地方,大家应该对于为什么BeanPostProcessor的before方法会在init方法执行了解了。这个方法的作用仅仅是用来进行一个生命周期的打印,对象在之前已经创建了。
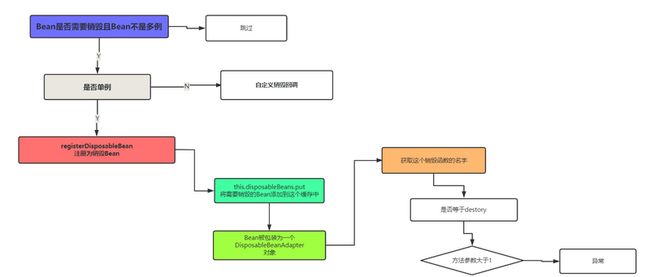
接下来看一下销毁的方法。registerDisposableBeanIfNecessary
对于单例Bean来说,Spring将需要销毁的Bean存放到了disposableBeans缓存中,通过DisposableBeanAdapter封装了销毁Bean
对于其他作用域来说,自定义了销毁回调函数,不过最后还是封装为DisposableBeanAdapter
在封装为DisposableBeanAdapter的过程中,会首先判断该Bean中是否存在destroy方法,然后给赋值给destroyMethodName变量。再次判断这个方法的参数,如果参数的个数大于1,则抛出异常
3.3.12 finishRefresh
这个方法进行了一系列的资源清理和
protected void finishRefresh() {
// 清空上下文资源缓存
clearResourceCaches();
// 初始化生命周期处理器
initLifecycleProcessor();
// 将已经刷新完毕的处理器传播(扔到)生命周期处理器中
getLifecycleProcessor().onRefresh();
// 推送上下文刷新完毕的时间到相应的监听器
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
LiveBeansView.registerApplicationContext(this);
}initLifecycleProcessor,这个方法极具简单,就看一下当前Bean中是否存在生命周期处理器,如果存在直接使用这个,如果不存在则创建一个默认的,并且注册为一个单例的扔到容器中。
4. 常见题目
4.1 Bean的生命周期?
Spring官方解释在BeanDefinition接口的注释里
答:Bean完整的生命周期是:
- 设置一系列
Aware接口的功能 - 实例化Bean
- 调用
BeanPostProcessor的before方法 - 执行
InitializingBean接口方法afterPropertiesSet - 执行
init方法 - 调用
BeanPostProcessor的postProcessAfterInitialization方法 - 调用
DestructionAwareBeanPostProcessors接口的postProcessBeforeDestruction方法 - 调用
destory方法
4.2 FactoryBean和BeanFactory的区别
答:BeanFactory是Spring默认生产对象的工厂。
FactoryBean是Spring提供的一个生产特定类型和特定对象的工厂。例如Mybatis-spring中的SqlSessionFactoryBean就是通过这种方法创建的。
4.3 什么是循环依赖?Spring如何处理循环依赖的?
答:循环依赖是指:在创建A对象的时候需要注入B对象;在创建B对象的时候需要注入A对象,两者互相依赖。
出现循环依赖有两种情况:
- 构造器依赖(无法解决)
- 属性注入(可以解决)
解决循环依赖,Spring引入了三级缓存的概念。上面的源码讲解中介绍过
singletonObjects存放了所有的单例Bean,此时所有的Bean信息都是完整的earlySingletonObjects存放了早期的Bean,此时仅仅创建了一个Bean实例,未进行属性填充singletonFactories存放了Bean的工厂
Spring通过将创建Bean的工厂暴露出来,然后在出现循环依赖的时候通过这个工厂常见一个bean,然后将这个Bean注入,由于对象是单例的,所以在接下来的属性填充中,可以保证为同一个对象,至此,循环依赖解除。
使用 三太子敖丙的一句话: 解决循环依赖的过程就是力扣中的第一题两数之和的过程
4.4 什么是IOC
答:IOC存在两个点:
- 控制反转。将常见对象的控制权交给第三方,这里的第三方就是
Spring - 依赖注入。在类中需要使用到的对象,全部通过反射从第三方容器注入而不是自己创建。这里的第三方容器即
Spring
4.5 ApplicationContext和BeanFactory的区别
答:
ApplicationContext采用了立即加载,即加载配置文件的时候就创建了对象。BeanFactory采用了延时加载的方式,使用的时候才创建。- 对于
BeanPostProcessor和BeanFactoryProcessor而言,BeanFactory是手动注册,ApplicationContext采用了自动注册。
4.6 Spring 框架中都用到了哪些设计模式?
答:
- 单例模式。这个不需要多说
- 代理模式。
AOP使用到的 - 装饰着模式。
BeanWrapper - 工厂模式。BeanFactory,创建对象的时候
- 模板方法模式。JDBCTemplate
- 观察者模式。各种事件监听
- ……
更多原创文章和Java系列教程请关注公众号@MakerStack