1. ArrayList
ArrayList是最最常用的集合类了,真的没有之一。下面的分析是基于1.8.0_261源码进行分析的。
1.1 ArrayList特点介绍
动态数组,使用的时候,只需要操作即可,内部已经实现扩容机制。
- 线程不安全
- 有顺序,会按照添加进去的顺序排好
- 基于数组实现,随机访问速度快,插入和删除较慢一点
- 可以插入null元素,且可以重复
1.2 实现的接口和继承的类
首先,我们看看ArrayList实现的类和继承的类: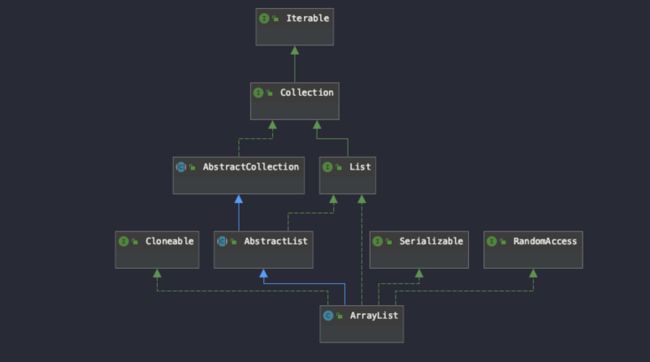
class ArrayList extends AbstractList implements List, RandomAccess, Cloneable, java.io.Serializable ArrayList 继承了AbstractList接口,实现了List,以及随机访问,可克隆,序列化接口。不是线程安全的,如果需要线程安全,则需要选择其他的类或者使用Collections.synchronizedList(arrayList)
允许存储null元素,也允许相同的元素存在。
其底层实际上是数组实现的,那为什么我们使用的时候只管往里面存东西,不用关心其大小呢?因为ArrayList封装了这样的功能,容量可以动态按需变化,不需要使用者关心。扩容之后不会自动缩小容量。
2. 成员变量
elementData是真正存储数据元素的地方,transient表示这个属性不需要自动序列化。
关于上面的transient,找到一个靠谱的说法:
在ArrayList中的elementData这个数组的长度是变长的,java在扩容的时候,有一个扩容因子,也就是说这个数组的长度是大于等于ArrayList的长度的,我们不希望在序列化的时候将其中的空元素也序列化到磁盘中去,所以需要手动的序列化数组对象,所以使用了transient来禁止自动序列化这个数组。
// 真正存取数据的数组
transient Object[] elementData;
// 实际元素个数(不是elementData的大小,是具体存放的元素的数量)
private int size;那在哪里去实现对西那个的序列化和反序列化的呢?
这个需要我们看源码里面的readOject()和writeOject()两个方法。其实就除了默认的序列化其他字段,这个elementData字段,还需要手动序列化和反序列化。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// 序列之前需要保存原本的修改的次数,序列化的过程中不允许新修改
int expectedModCount = modCount;
// 将当前类的非静态和非transient的字段写到流中,其实就是默认的序列化
s.defaultWriteObject();
// 将大小写到输出流中
s.writeInt(size);
// 按照顺序序列化里面的每一个元素,注意使用的是`writeOject()`
for (int i=0; i 0) {
// 和clone()类似,根据size分配空间,而不是容量
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// 循环读取每一个元素
for (int i=0; i 很多人可能会有疑问,为什么这个函数没有看到有调用呢?在哪里调用的呢?
其实就是在对象流中,通过反射的方式进行调用的,如果有自己的实现,就会调用到这里的实现,这里就不展开了,下次一定!!!有兴趣可以看看。
如果我们创建的时候不指定大小,那么就会初始化一个默认大小为10,DEFAULT_CAPACITY就是默认大小。
private static final int DEFAULT_CAPACITY = 10;里面定义了两个空数组,EMPTY_ELEMENTDATA名为空数组,DEFAULTCAPACITY_EMPTY_ELEMENTDATA名为默认大小空数组,用来区分是空构造函数还是带参数构造函数构造的ArrayList,第一次添加元素的时候使用不同的扩容方式。
之所以是一个空数组,不是null,是因为使用的时候我们需要制定参数的类型,如果是null,那就根本不知道元素类型是什么了。
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};还有一个特殊的成员变量modCount,这是快速失败机制所需要的,也就是记录修改操作的次数,主要是迭代遍历的时候,防止元素被修改。如果操作前后的修改次数对不上,那么有些操作就是非法的。transient表示这个属性不需要自动序列化。
protected transient int modCount = 0;序列化idserialVersionUID如下:
为什么需要这个字段呢?这是因为如果没有显示声明这个字段,那么序列化的时候回自动生成一个序列化的id,写到序列化文件中去,这样子的话,假设序列化完成之后,往原来的类里面添加了一个字段,那么这个时候反序列化会失败,因为默认的序列化id已经改变了。假设我们给它指定了序列化id的话,就可以避免这种问题,只是增加的字段反序列化的时候是空的。
private static final long serialVersionUID = 8683452581122892189L;3. 构造方法
构造方法有三个,可以指定容量,可以指定初始的元素集合,也可以什么都不指定。
// 指定初始化的大小
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 什么都不指定,默认是空的元素集
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 传入一个集合,转成数组之后,复制一份作为显得数据集
public ArrayList(Collection c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}4. 常用增删改查方法
添加元素
add()方法有两个:
add(E e):添加一个元素,默认是在末尾添加add(int index, E element):在指定位置index添加(插入)一个元素
public boolean add(E e) {
// 确定容量是不是足够,足够就不会增加
ensureCapacityInternal(size + 1);
// size+1的地方,赋值为现在的e
elementData[size++] = e;
return true;
}
// 在指定的位置插入一个元素
public void add(int index, E element) {
// 检查插入的位置,是否合法
rangeCheckForAdd(index);
// 检查是不是需要扩容,容量是否足够
ensureCapacityInternal(size + 1); // Increments modCount!!
// 复制index后面的元素,都往后面移动一位(这是c++实现的底层原生方法)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 在index处插入元素
elementData[index] = element;
// 实际的存储元素个数增加
size++;
} 查询元素
get()方法相对比较简单,获取之前检查参数是否合法,就可以返回元素了。
public E get(int index) {
// 检查下标
rangeCheck(index);
return elementData(index);
}
// 检查下标
private void rangeCheck(int index) {
if (index >= size)
// 数组越界
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
} 更新元素
set()和之前的get()有点像,但是必须制定修改的元素下标,检查下标之后,修改,然后返回旧的值。
public E set(int index, E element) {
// 检查下标
rangeCheck(index);
// 获取旧的值
E oldValue = elementData(index);
// 修改元素
elementData[index] = element;
// 返回旧的值
return oldValue;
}删除元素
按照元素移除,或者按照下标移除元素
public E remove(int index) {
// 检查下标
rangeCheck(index);
// 修改次数改变
modCount++;
// 获取旧的元素
E oldValue = elementData(index);
// 计算需要移动的下标(往前面移动一位)
int numMoved = size - index - 1;
if (numMoved > 0)
// 调用native方法将后面的元素复制,移动往前一步
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将之前的元素置为空,让垃圾回收方便进行
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
// 为空的元素
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 遍历,如果equals,则调用删除
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
// 快速删除方法
private void fastRemove(int index) {
// 修改次数增加1
modCount++;
// 计算移动的位置
int numMoved = size - index - 1;
if (numMoved > 0)
// 前面移动一位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 置空
elementData[--size] = null; // clear to let GC do its work
}5.自动扩容和手动缩容机制
5.1 自动扩容
ArrayList是基于数组动态扩容的,那它什么时候扩容的呢?好像上面的源代码中我们没有看到,其实是有的,所谓扩容嘛,就是容量不够了,那么容量不够的时候只会发生在初始化一个集合的时候或者是增加元素的时候,所以是在add()方法里面去调用的。
在最小调用的时候容量不满足的时候,会调用grow(),grow()是真正扩容的函数,这里不展开了。
如果元素是默认初始haul的空数据,那么所需要的最小容量就是默认容量和最小容量对比,两者取最大,也就是突然有加入有6个元素加到集合中来,那么默认容量是10,会直接初始化为10,如果一下子有11个元素加进来,那么最小的容量应该取11。
// 计算所需最小容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果元素是默认初始haul的空数据,那么所需要的最小容量就是默认容量和最小容量对比,两者取最大。
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 确保容量足够
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
// 修改次数增加
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
// 真正实现容量增长的函数
grow(minCapacity);
}真正实现扩容的代码如下:
private void grow(int minCapacity) {
// 获取旧的容量
int oldCapacity = elementData.length;
// 新容量是翻了一倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果新的容量还是小于最小容量,则最新容量更新为最小容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果最新的容量大于最大的容量,则需要调用hugeCapacity函数将容量调小一点
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 底层是调用数组直接复制
elementData = Arrays.copyOf(elementData, newCapacity);
}- 如果所需最小容量小于0,抛出异常
- 如果所需最小容量大于最大的容量,那么直接返回int类型的最大值作为容量
- 如果所需的最小容量小于等于最大容量,那么直接返回最大的容量。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}如果需要手动扩容,其实也是有提供函数的,其参数是所需要的最小的容量,内部调用也是上面说的ensureExplicitCapacity函数。
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}5.2 手动扩容
手动缩容的函数相对简单,修改次数增加,然后,将数组元素copy到新的数组中即可。
public void trimToSize() {
// 修改次数增加
modCount++;
// 只要真实使用的个数小于数组长度,都会缩容
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}6. 其他函数
获取大小:
public int size() {
return size;
}判断是不是空集合:
public boolean isEmpty() {
return size == 0;
}是否包含某个对象:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}返回对象的下标,从左到右遍历,分为object为null和非null来处理:
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}放回对象最后出现的下标,从右往左遍历:
public int lastIndexOf(Object o) {
if (o == null) {
// 为null的时候不能使用equals
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}克隆ArrayList对象,先拷贝ArrayList,然后再把内部的数组也拷贝一份:
public Object clone() {
try {
// 调用默认的拷贝
ArrayList v = (ArrayList) super.clone();
// 将内部的数组也拷贝一份
v.elementData = Arrays.copyOf(elementData, size);
// 修改次数只为0
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}转化为数组,我们看到内部其实是复制了一份引用,所以如果我们修改数组里面的元素,也会修改到ArrayList元素的。
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}将元素拷贝到指定的数组中:
public T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
} 根据index索引位置获取迭代器位置:
public ListIterator listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
// 默认是在开始的位置
public ListIterator listIterator() {
return new ListItr(0);
} 截取一段,返回新的list,返回的是一个内部类SubList对象。
public List subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
} 遍历方法,其实就是lambda的方式进行调用,将行为参数化,将行为传进去,处理。
@Override
public void forEach(Consumer action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}根据条件移除元素,也是lambda表达式:
@Override
public boolean removeIf(Predicate filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
} // 替换所有
public void replaceAll(UnaryOperator operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
} 排序,lambda表达式:
public void sort(Comparator c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}7. 迭代器
源码中一共定义了三个迭代器:
Itr:实现了Iterator接口,是AbstractList.Itr的优化版本。ListItr:继承了Itr,实现了ListIterator,是AbstractList.ListItr优化版本。ArrayListSpliterator:继承于Spliterator,Java 8 新增的迭代器,基于索引,二分的,懒加载器。
7.1 Itr
Itr这是一个比较初级的迭代器,实现了Iterator接口,有判断是否有下一个元素,访问下一个元素,删除元素的方法以及遍历对每一个元素处理的方法。
里面有两个比较重要的属性:
- cursor:下一个即将访问的元素下标
- lastRet:上一个返回的元素下标,初始化为-1
两个重要的方法:
- next():获取下一个元素
- remove():移除当前元素,需要在next()方法调用之后,才能调用,要不会报错。
private class Itr implements Iterator {
// 下一个返回元素的下标
int cursor;
// 上一个返回元素的下标,初始化为-1
int lastRet = -1;
int expectedModCount = modCount;
// 无参构造
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
// 检查是否被修改
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
// 修改上一个返回元素的下标,返回该位置的值
return (E) elementData[lastRet = i];
}
public void remove() {
// 如果在调用next之前,调用了remove方法,此时的lastRet就是-1,就是非法的。
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
// 调用数组的remove方法
ArrayList.this.remove(lastRet);
// remove的是lastRet位置的元素,那么cursor(下一个即将返回的元素下标位置)就相当于往前面移动了一位,因为之前的lastRet位置的元素被删除了,后面所有元素都往前面移动了一位
cursor = lastRet;
// 上一个返回的元素下标没有意义了,已经被删除了,直接置为-1
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 对里面的每一个元素进行处理
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
// 检查过程中是否被修改
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
} 7.2 ListItr
继承了Itr,实现了ListIterator,主要增加的功能有:
- 根据index获取该位置的迭代器
- 判断是否有前面的元素
- 获取下一个返回元素的下标
- 获取上一个返回元素的下面
- 获取上一个元素
- 更新元素
- 增加元素
总结来说,就是在Itr的基础上,增加了更多的功能。
private class ListItr extends Itr implements ListIterator {
// 根据index获取该位置的迭代器
ListItr(int index) {
super();
cursor = index;
}
// 判断是否有前面的元素
public boolean hasPrevious() {
return cursor != 0;
}
// 获取下一个返回元素的下标
public int nextIndex() {
return cursor;
}
// 获取上一个返回元素的下面
public int previousIndex() {
return cursor - 1;
}
// 获取上一个元素
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
// 更新元素
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
// 更新元素
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
// 增加元素
public void add(E e) {
// 检查是否被更改
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
// 插入元素后,下一个元素的下标递增1
cursor = i + 1;
// 上一个元素为-1
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
} 7.3 ArrayListSpliterator
直接看源码,这是一个用来适应多线程并行迭代的迭代器,可以将集合分成多端,进行处理,每一个线程执行一段,那么就不会相互干扰,它可以做到线程安全。
static final class ArrayListSpliterator implements Spliterator {
// 存放ArrayList对象,
private final ArrayList list;
// 当前位置
private int index;
// 结束位置,-1表示最后一个元素
private int fence;
// 期待的修改次数,用于比较是不是被修改了
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
ArrayListSpliterator(ArrayList list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList lst;
if ((hi = fence) < 0) {
if ((lst = list) == null)
hi = fence = 0;
else {
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
// 分割ArrayList,每调用一次,将原来的迭代器等分为两份,并返回索引靠前的那一个子迭代器。
public ArrayListSpliterator trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator(list, lo, index = mid,
expectedModCount);
}
// 返回true时,表示可能还有元素未处理
// 返回falsa时,没有剩余元素处理了
public boolean tryAdvance(Consumer action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// 遍历处理剩下的元素
public void forEachRemaining(Consumer action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
// 估算大小
public long estimateSize() {
return (long) (getFence() - index);
}
// 返回特征值
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
} 以上三种迭代器,各有千秋,Itr功能比较简单,提供了常用的功能,ListItr,提供了双向遍历和更新,插入等操作,而ArrayListSpliterator则是专注于切分迭代。使用的时候按需使用即可。
8. 小结一下
- ArrayList是基于动态数组实现的,增加元素的时候,可能会触发扩容操作。扩容之后会触发数组的拷贝复制。remove操作也会触发复制,后面的元素统一往前面挪一位,原先最后面的元素会置空,这样可以方便垃圾回收。
- 默认的初始化容量是10,容量不够的时候,扩容时候增加为原先容量的一般,也就是原来的1.5倍。
- 线程不安全,但是元素可以重复,而且可以放null值,这个需要注意一下,每次取出来的时候是需要判断是不是为空。
- 查询效率比较高,因为底层是数组,但是插入和删除操作,成本相对高一点。
【作者简介】:
秦怀,公众号【秦怀杂货店】作者,技术之路不在一时,山高水长,纵使缓慢,驰而不息。这个世界希望一切都很快,更快,但是我希望自己能走好每一步,写好每一篇文章,期待和你们一起交流。
此文章仅代表自己(本菜鸟)学习积累记录,或者学习笔记,如有侵权,请联系作者核实删除。人无完人,文章也一样,文笔稚嫩,在下不才,勿喷,如果有错误之处,还望指出,感激不尽~