在开发分布式高并发系统时有三把利器用来保护系统:缓存、降级、限流
缓存
缓存的目的是提升系统访问速度和增大系统处理容量;
降级
降级是当服务出现问题或者影响到核心流程时,需要暂时屏蔽掉,待高峰或者问题解决后再打开;
限流
限流的目的是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理;
问题描述
1、某天A君突然发现自己的接口请求量突然涨到之前的10倍,没多久该接口几乎不可使用,并引发连锁反应导致整个系统崩溃。如何应对这种情况呢?
生活给了我们答案:比如老式电闸都安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏。同理我们的接口也需要安装上“保险丝”,以防止非预期的请求对系统压力过大而引起的系统瘫痪,当流量过大时,可以采取拒绝或者引流等机制。
2、缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;
而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一种手段来限制这些场景的并发/请求量,即限流。
3、系统在设计之初就会有一个预估容量,长时间超过系统能承受的TPS/QPS阈值,系统可能会被压垮,最终导致整个服务不够用。为了避免这种情况,我们就需要对接口请求进行限流。
4、限流的目的是通过对并发访问请求进行限速或者一个时间窗口内的的请求数量进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待。
5、一般开发高并发系统常见的限流模式有控制并发和控制速率,一个是限制并发的总数量(比如数据库连接池、线程池),一个是限制并发访问的速率(如nginx的limitconn模块,用来限制瞬时并发连接数),另外还可以限制单位时间窗口内的请求数量(如Guava的RateLimiter、nginx的limitreq模块,限制每秒的平均速率)。其他还有如限制远程接口调用速率、限制MQ的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
相关概念:
PV:
page view 页面总访问量,每刷新一次记录一次。
UV:
unique view 客户端主机访问,指一天内相同IP的访问记为1次。
QPS:
query per second,即每秒访问量。qps很大程度上代表了系统的繁忙度,没次请求可能存在多次的磁盘io,网络请求,多个cpu时间片,一旦qps超过了预先设置的阀值,可以考量扩容增加服务器,避免访问量过大导致的宕机。
RT:
response time,每次请求的响应时间,直接决定用户体验性。
本文主要介绍应用级限流方法,分布式限流、流量入口限流(接入层如NGINX limitconn和limitreq 模块)
1.应用级限流
一、控制并发数量
属于一种较常见的限流手段,在实际应用中可以通过信号量机制(如Java中的Semaphore)来实现。操作系统的信号量是个很重要的概念,Java 并发库 的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
举个例子,我们对外提供一个服务接口,允许最大并发数为10,代码实现如下:
public class DubboService {
private final Semaphore permit = new Semaphore(10, true);
public void process(){
try{
permit.acquire();
//业务逻辑处理
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
permit.release();
}
}
} 在以上代码中,虽然有30个线程在执行,但是只允许10个并发的执行。Semaphore的构造方法Semaphore(int permits) 接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。
Semaphore的用法也很简单,首先线程使用Semaphore的acquire()获取一个许可证,使用完之后调用release()归还许可证,还可以用tryAcquire()方法尝试获取许可证,信号量的本质是控制某个资源可被同时访问的个数,在一定程度上可以控制某资源的访问频率,但不能精确控制,控制访问频率的模式见下文描述。
二、控制访问速率
在工程实践中,常见的是使用令牌桶算法来实现这种模式,常用的限流算法有两种:漏桶算法和令牌桶算法。
漏桶算法
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
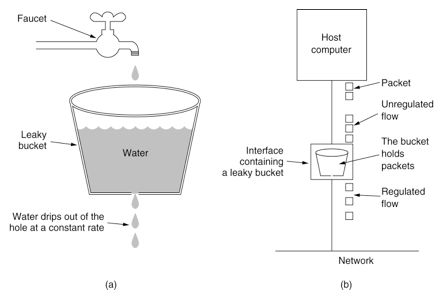
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
令牌桶算法
如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务,令牌桶算法通过发放令牌,根据令牌的rate频率做请求频率限制,容量限制等。

在Wikipedia上,令牌桶算法是这么描述的:
1、每过1/r秒桶中增加一个令牌。
2、桶中最多存放b个令牌,如果桶满了,新放入的令牌会被丢弃。
3、当一个n字节的数据包到达时,消耗n个令牌,然后发送该数据包。
4、如果桶中可用令牌小于n,则该数据包将被缓存或丢弃。
令牌桶控制的是一个时间窗口内通过的数据量,在API层面我们常说的QPS、TPS,正好是一个时间窗口内的请求量或者事务量,只不过时间窗口限定在1s罢了。以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。令牌桶的另外一个好处是可以方便的改变速度,一旦需要提高速率,则按需提高放入桶中的令牌的速率。
在我们的工程实践中,通常使用Google开源工具包Guava提供的限流工具类RateLimiter来实现控制速率,该类基于令牌桶算法来完成限流,非常易于使用,而且非常高效。如我们不希望每秒的任务提交超过1个;
首先通过RateLimiter.create(1.0);创建一个限流器,参数代表每秒生成的令牌数,通过limiter.acquire(i);来以阻塞的方式获取令牌,令牌桶算法允许一定程度的突发(允许消费未来的令牌),所以可以一次性消费i个令牌;当然也可以通过tryAcquire(int permits, long timeout, TimeUnit unit)来设置等待超时时间的方式获取令牌,如果超timeout为0,则代表非阻塞,获取不到立即返回,支持阻塞或可超时的令牌消费。
从输出来看,RateLimiter支持预消费,比如在acquire(5)时,等待时间是4秒,是上一个获取令牌时预消费了3个两排,固需要等待3*1秒,然后又预消费了5个令牌,以此类推。
RateLimiter通过限制后面请求的等待时间,来支持一定程度的突发请求(预消费),在使用过程中需要注意这一点,Guava有两种限流模式,一种为稳定模式(SmoothBursty:令牌生成速度恒定,平滑突发限流),一种为渐进模式(SmoothWarmingUp:令牌生成速度缓慢提升直到维持在一个稳定值,平滑预热限流) 两种模式实现思路类似,主要区别在等待时间的计算上。
SmoothBursty 模式:
RateLimiter limiter = RateLimiter.create(5); RateLimiter.create(5)表示桶容量为5且每秒新增5个令牌,即每隔200毫秒新增一个令牌;limiter.acquire()表示消费一个令牌,如果当前桶中有足够令牌则成功(返回值为0),如果桶中没有令牌则暂停一段时间,比如发令牌间隔是200毫秒,则等待200毫秒后再去消费令牌,这种实现将突发请求速率平均为了固定请求速率。
SmoothWarmingUp模式:
RateLimiter limiter = RateLimiter.create(5,1000, TimeUnit.MILLISECONDS);
创建方式:
**RateLimiter.create(doublepermitsPerSecond, long warmupPeriod, TimeUnit unit),permitsPerSecond表示每秒新增的令牌数,**warmupPeriod表示在从冷启动速率过渡到平均速率的时间间隔。速率是梯形上升速率的,也就是说冷启动时会以一个比较大的速率慢慢到平均速率;然后趋于平均速率(梯形下降到平均速率)。可以通过调节warmupPeriod参数实现一开始就是平滑固定速率。
放在Controller中用Jemter压测
注:RateLimiter控制的是速率,Samephore控制的是并发量。RateLimiter的原理就是令牌桶,它主要由许可发出的速率来定义,如果没有额外的配置,许可证将按每秒许可证规定的固定速度分配,许可将被平滑地分发,若请求超过permitsPerSecond则RateLimiter按照每秒 1/permitsPerSecond 的速率释放许可。注意:RateLimiter适用于单体应用,且RateLimiter不保证公平性访问。
使用上述方式使用RateLimiter的方式不够优雅,自定义注解+AOP的方式实现(适用于单体应用),详细见下面代码:
自定义注解:
import java.lang.annotation.*;
/**
* 自定义注解可以不包含属性,成为一个标识注解
*/
@Inherited
@Documented
@Target({ElementType.METHOD, ElementType.FIELD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface RateLimitAspect {
} 自定义切面类
import com.google.common.util.concurrent.RateLimiter;
import com.test.cn.springbootdemo.util.ResultUtil;
import net.sf.json.JSONObject;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@Component
@Scope
@Aspect
public class RateLimitAop {
@Autowired
private HttpServletResponse response;
private RateLimiter rateLimiter = RateLimiter.create(5.0); //比如说,我这里设置"并发数"为5
@Pointcut("@annotation(com.test.cn.springbootdemo.aspect.RateLimitAspect)")
public void serviceLimit() {
}
@Around("serviceLimit()")
public Object around(ProceedingJoinPoint joinPoint) {
Boolean flag = rateLimiter.tryAcquire();
Object obj = null;
try {
if (flag) {
obj = joinPoint.proceed();
}else{
String result = JSONObject.fromObject(ResultUtil.success1(100, "failure")).toString();
output(response, result);
}
} catch (Throwable e) {
e.printStackTrace();
}
System.out.println("flag=" + flag + ",obj=" + obj);
return obj;
}
public void output(HttpServletResponse response, String msg) throws IOException {
response.setContentType("application/json;charset=UTF-8");
ServletOutputStream outputStream = null;
try {
outputStream = response.getOutputStream();
outputStream.write(msg.getBytes("UTF-8"));
} catch (IOException e) {
e.printStackTrace();
} finally {
outputStream.flush();
outputStream.close();
}
}
}
测试controller
import com.test.cn.springbootdemo.aspect.RateLimitAspect;
import com.test.cn.springbootdemo.util.ResultUtil;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class TestController {
@ResponseBody
@RateLimitAspect
@RequestMapping("/test")
public String test(){
return ResultUtil.success1(1001, "success").toString();
}压测结果:
三、控制单位时间窗口内请求数
某些场景下,我们想限制某个接口或服务 每秒/每分钟/每天 的请求次数或调用次数。例如限制服务每秒的调用次数为50,实现如下:
private LoadingCache < Long, AtomicLong > counter = CacheBuilder.newBuilder().expireAfterWrite(2, TimeUnit.SECONDS).build(new CacheLoader < Long, AtomicLong > () {@
Override
public AtomicLong load(Long seconds) throws Exception {
return new AtomicLong(0);
}
});
public static long permit = 50;
public ResponseEntity getData() throws ExecutionException {
//得到当前秒
long currentSeconds = System.currentTimeMillis() / 1000;
if (counter.get(currentSeconds).incrementAndGet() > permit) {
return ResponseEntity.builder().code(404).msg("访问速率过快").build();
}
//业务处理
}
到此应用级限流的一些方法就介绍完了。假设将应用部署到多台机器,应用级限流方式只是单应用内的请求限流,不能进行全局限流。因此我们需要分布式限流和接入层限流来解决这个问题。
分布式限流
自定义注解+拦截器+Redis实现限流 (单体和分布式均适用,全局限流)
自定义注解:
@Inherited
@Documented
@Target({ElementType.FIELD,ElementType.TYPE,ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface AccessLimit {
int limit() default 5;
int sec() default 5;
} 拦截器:
public class AccessLimitInterceptor implements HandlerInterceptor {
@Autowired
private RedisTemplate redisTemplate; //使用RedisTemplate操作redis
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (handler instanceof HandlerMethod) {
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
if (!method.isAnnotationPresent(AccessLimit.class)) {
return true;
}
AccessLimit accessLimit = method.getAnnotation(AccessLimit.class);
if (accessLimit == null) {
return true;
}
int limit = accessLimit.limit();
int sec = accessLimit.sec();
String key = IPUtil.getIpAddr(request) + request.getRequestURI();
Integer maxLimit = redisTemplate.opsForValue().get(key);
if (maxLimit == null) {
redisTemplate.opsForValue().set(key, 1, sec, TimeUnit.SECONDS); //set时一定要加过期时间
} else if (maxLimit < limit) {
redisTemplate.opsForValue().set(key, maxLimit + 1, sec, TimeUnit.SECONDS);
} else {
output(response, "请求太频繁!");
return false;
}
}
return true;
}
public void output(HttpServletResponse response, String msg) throws IOException {
response.setContentType("application/json;charset=UTF-8");
ServletOutputStream outputStream = null;
try {
outputStream = response.getOutputStream();
outputStream.write(msg.getBytes("UTF-8"));
} catch (IOException e) {
e.printStackTrace();
} finally {
outputStream.flush();
outputStream.close();
}
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
} controller:
@Controller
@RequestMapping("/activity")
public class AopController {
@ResponseBody
@RequestMapping("/seckill")
@AccessLimit(limit = 4,sec = 10) //加上自定义注解即可
public String test (HttpServletRequest request,@RequestParam(value = "username",required = false) String userName){
//TODO somethings……
return "hello world !";
}
} 配置文件:
/*springmvc的配置文件中加入自定义拦截器*/
访问效果如下,10s内访问接口超过4次以上就过滤请求,原理和计数器算法类似:

接入层限流
主要介绍nginx 限流,采用漏桶算法。
限制原理:可一句话概括为:“根据客户端特征,限制其访问频率”,客户端特征主要指IP、UserAgent等。使用IP比UserAgent更可靠,因为IP无法造假,UserAgent可随意伪造。
用limit_req模块来限制基于IP请求的访问频率:
http://nginx.org/en/docs/http...
也可以用tengine中的增强版:
http://tengine.taobao.org/doc...
1、并发数和连接数控制的配置:
nginx http配置:
#请求数量控制,每秒20个
limit_req_zone $binary_remote_addr zone=one:10m rate=20r/s;
#并发限制30个
limit_conn_zone $binary_remote_addr zone=addr:10m;
server块配置
limit_req zone=one burst=5;
limit_conn addr 30;2、ngxhttplimitconnmodule 可以用来限制单个IP的连接数:
ngxhttplimitconnmodule模块可以按照定义的键限定每个键值的连接数。可以设定单一 IP 来源的连接数。
并不是所有的连接都会被模块计数;只有那些正在被处理的请求(这些请求的头信息已被完全读入)所在的连接才会被计数。
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
...
server {
...
location /download/ {
limit_conn addr 1;
}