摘要:数据仓库建设过程中,总是会涉及到不同平台、同一平台物理环境搬迁,由于数据仓库数据量庞大,往往数据搬迁不可能在一个短周期内完成,会涉及数据同步、校验、追批并跑、再校验过程。
本文主要阐述数据校验过程设计,供相关人员借鉴。
数据一致性校验最核心内容项
校验手段
根据常见数据存储类型,主要完成对象级记录一致性校验,字段级数值、时间、字符类型的数据一致性校验,即常规提到的表级count、字段级数值的sum、时间类型差值sum、字符类型的checksum。
下文以TD搬迁GaussDB(DWS)为例,
1. 记录数
a) 表级count(*)
2. 数据类型
a) 汇总Sum(cola)
b) 平均Avg(cola)
c) 例外,针对float类型这种存在精度缺失场景,或直接不校验,或比对两个平台差异小于5%范围即可接受;
d) 注意事项,不同平台可能存在sum放大小数点位数问题,可通过指定小数点位置,让两个平台数值完全一致;
3. 时间类型
a) 汇总Sum(时间转换数字)
b) Date类型实现样式
i. DWS:select extract(epoch from '20200819'::date);
ii. TD:sel (date'2020-08-19'-date'1970-01-01')*86400;
c) Time类型实现样式
i. DWS:select extract(epoch from '12:12:12'::time);
ii. TD:sel extract(hour from time'12:12:12')3600+extract(minute from time'12:12:12')60+extract(second from time'12:12:12');
d) TimeStamp类型实现
i. DWS:select extract(epoch from '2020-08-19 12:12:12'::timestamp);
ii. TD:sel ( (timestamp'2020-08-19 12:12:12'(date))-date'1970-01-01')86400+extract(hour from timestamp'2020-08-19 12:12:12')3600+extract(minute from timestamp'2020-08-19 12:12:12')*60+extract(second from timestamp'2020-08-19 12:12:12');
e) 即将两个平台将采用同一周期进行时间类型汇总,保证数据求和一致性;
4. 字符类型
a) 整体思路是将字符串在同一字符集条件下计算MD5值,再进行MD5串切分、异或(XOR),得到相对较小数值,再进行数值sum求和;
注,若两个平台均支持自定义聚合函数,可以直接进行每个字符串MD5值计算,再进行全部MD5值异或操作,得到最终值,用于识别数据一致性;
b) DWS实现逻辑
创建自定义函数,
Create or replace function xor_md5(text) returns bigint immutable as $$
select ('x'||lpad(substr(md5($1),1,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5($1),9,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5($1),17,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5($1),25,8),16,'0'))::bit(64)::bigint;
$$ language sql;
create function xor_md5_latin(text) returns bigint immutable as $$
select ('x'||lpad(substr(md5(convert($1,'GB18030')),1,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5(convert($1,'GB18030')),9,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5(convert($1,'GB18030')),17,8),16,'0'))::bit(64)::bigint
# ('x'||lpad(substr(md5(convert($1,'GB18030')),25,8),16,'0'))::bit(64)::bigint;
$$ language sql;c) TD实现逻辑
i. 方式一:创建SQL自定义函数
replace function xor_md5(inpt varchar(32000))
returns bigint
language sql
deterministic contains sql
sql SECURITY DEFINER
collation INVOKER
INLINE TYPE 1
return
bitxor( bitxor ( bitxor (
cast(from_bytes(to_bytes(
translate(substr(hash_md5(udf_utf16to8(udf_w936to16(inpt,''))),1,8)
using latin_to_unicode),'base16'),'base10') as bigint)
,cast(from_bytes(to_bytes(
translate(substr(hash_md5(udf_utf16to8(udf_w936to16(inpt,''))),9,8)
using latin_to_unicode),'base16'),'base10') as bigint))
,cast(from_bytes(to_bytes(
translate(substr(hash_md5(udf_utf16to8(udf_w936to16(inpt,''))),17,8)
using latin_to_unicode),'base16'),'base10') as bigint))
,cast(from_bytes(to_bytes(
translate(substr(hash_md5(udf_utf16to8(udf_w936to16(inpt,''))),25,8)
using latin_to_unicode),'base16'),'base10') as bigint));注,TD通常实践中以Latin存储GBK中文数据,而GaussDB(DWS)一般推荐采用主流UTF8字符集存储数据,则双方进行字符md5计算时,需转换成同一个字符集,其中涉及hash_md5、udf_utf16to8、udf_w936to16三个非TD内置函数,需要https://downloads.teradata.co...
ii. 方式二:创建C自定义函数
replace function xor_md5_latin ( arg varchar(32000) character set latin)
returns bigint
language c
no sql
external name 'ci:md5:md5.h:cs:xor_md5:xor_md5_latin.c:cs:md5:md5.c:F:xor_md5'
parameter style td_general;
replace function xor_md5(inpt varchar(32000))
returns bigint
language sql
deterministic contains sql
sql SECURITY DEFINER
collation INVOKER
INLINE TYPE 1
return
xor_md5_latin(udf_utf16to8(udf_w936to16(inpt,'')));C代码若有需要私聊留言
d) 测试数据如下
i. TD执行情况
Select xor_md5(‘a’);
------------------------
2491710610
Select xor_md5_latin(‘中国’);
------------------------
66934228
Select xor_md5(‘中国’);
------------------------
1004201695
ii. GS执行情况
Select xor_md5(‘a’);
------------------------
2491710610
Select xor_md5_latin(‘中国’);
------------------------
66934228
Select xor_md5(‘中国’);
------------------------
1004201695校验数据范围
根据数据仓库数据特性,进行切片粒度数据收集,除记录数统计之外,其它均以字段级粒度收集数据,即一个切片一个字段产生一条记录信息。
_
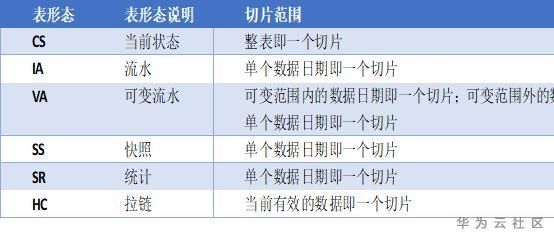
_
注:针对VA类型,存在多日流水数据发生变化场景,将最新变化流水数据打包成一个切片进行校验;
通过以上切片粒度,实现数据增量校验;而每隔一个周期,再进行全量校验,保障数据完整、一致;
校验方式
根据数据仓库特性,可以分为常规批量校验和自定义校验;
通常,可以将校验嵌入批量过程中,即对应作业的数据表发生变化后,直接触发相关数据表校验,这样实现数据准实时校验,保证两个平台并跑期间数据一致性;另外,在确保两个平台数据稳定前提下,可以固定时间段或用户直接发起实时校验,用于核对平台一致性;
校验策略
可进行数据表分级分类,将有限校验计算资源投入到数据一致性校验中,可参照以下分类,
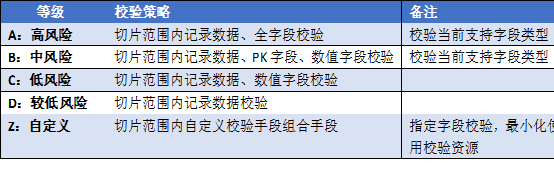
自动化服务
以上阐述了相关实现的方法论,最后再探讨一下如何实践;
自动化校验框架,建议常驻rest服务,用于接收客户端触发的校验请求,分发各数据平台执行校验采集工作,利用rest服务实现跨服务器交互问题;采用一个portal展现界面,用于用户录入自定义校验规则以及查看数据校验情况。