博客园期刊杂志格式规范(讨论稿)
跟本文相关的代码可以从这里下载
昨天发了一个关于博客园电子杂志格式设想,今天把我设计的一个实施方案放上来,并说说我的思路。
我做了三个文件,一个XML Schema,用来规范期刊上文章的格式,还有一个测试用的XML文件,以及我自己设计的一个样式XSL(大家可根据自己需要自行定制格式信息,包括XSL以及CSS规范)。如果大家安装了XMLSPY 2004的化,查看起来可能更方便一些。
XML Schema的内容如下:
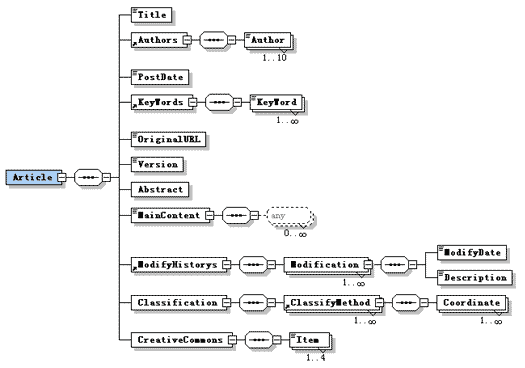
其中大多数内容都不用我再解释,我只解释其中一部分:
CreativeCommons
CreativeCommons为创作共用标记,由一系列标记值组成,其Schema是:
<xs:simpleType name="CreativeCommonsType">
<xs:restriction base="xs:string">
<xs:enumeration value="Attribution"/>
<xs:enumeration value="Noncommercial"/>
<xs:enumeration value="No Derivative Works"/>
<xs:enumeration value="Share Alike"/>
</xs:restriction>
</xs:simpleType>
是一个枚举类型,其值可以是"Attribution"、"Noncommercial"、"No Derivative Works"和"Share Alike"中的一个或多个。
MainContent
MainContent是文章正文部分,为了能够解析正常,不要忘了在XML文件对应的MainContent节点下应用HTML的命名空间。例如:
<MainContent>
<DIV xmlns="http://www.w3.org/TR/REC-html40">
......
</DIV>
</MainContent>
这样DIV内部的所有元素默认命名空间都是HTML命名空间了,防止出现命名冲突。
Classification
Classification为文章分类节点。我的思路是:博客园可以定制多种分类方法,今后甚至允许个人定义自己的分类算法,某篇文章在这一系列分类中拥有自己的"坐标"和"权重(关联度)"。未来在检索时,我们可以用不同分类进行交叉检索,并依据权重排序。
例如:
我们设立如下两个分类:
按语言分(ClassifyMethodID:001)
C#(ClassificationID:001001)
VB.NET(ClassificationID:001002)
VC++(ClassificationID:001002)
按技术分(ClassifyMethodID:002)
开源技术(ClassificationID:002001)
DNN 3.0(ClassificationID:002001001)
NHibernate(ClassificationID:002001002)
ASP.NET(ClassificationID:002002)
ADO.NET(ClassificationID:002003)
假如有篇文章是关于ASP.NET网站开发的,用C#编写,用到了ADO.NET技术以及NHibernate技术,我们就可以在XML中如下描述其分类:
<Classification>
<ClassifyMethod ClassifyMethodID="001">
<Coordinate ClassificationID="001001" Weight="0.6"/>
</ClassifyMethod>
<ClassifyMethod ClassifyMethodID="002">
<Coordinate ClassificationID="002001002" Weight="0.9"/>
<Coordinate ClassificationID="002002" Weight="1"/>
<Coordinate ClassificationID="002003" Weight="0.3"/>
</ClassifyMethod>
</Classification>
可以从中看出,文章最贴近的技术是ASP.NET,与NHibernate也有很大关联。但ADO.NET技术应用不很多。未来想检索ASP.NET中应用NHibernate技术的文章,通过交叉定位就可以很容易找到相关内容。权重也可用来对结果排序(排序方案我还没有想好)。
分类方案一旦确定后,由博客园统一进行编码,并定期发布最新编码方案(也可以用XML格式)。这些编码一旦确立后,就不允许再进行修改。同时可以开放一个编码段,供用户自己设置编码。未来一旦期刊采用智能客户端技术,这些自己定义的分类方案可以附加在XML文章后,供自己参考(说得有些远了,而且这一点我还没有考虑好)。
XSL格式输出
XSL文件可以自己编写,我提供了一个方案,不太好看,但足以说明问题。这样文章就具有了换肤的功能。大家可以下载文件,用IE打开XML文件看看应用样式后的结果。自己也可以修改XSL文件和CSS样式表,提供新的界面效果。
其它
上篇随笔中我建议使用GUID作为图片名,后来我发现博客园每篇文章都有ID号(从地址栏中可以看出来)。如果这个ID号不重复的化,就可以作为期刊文章ID使用。另外,该文章的所有图片可以在文章ID后面添加"-1"、"-2"序号。这样可以很容易找到某文章所包含的图片。就像我在images目录下给出的两个图片的命名一样。
另外,目前我在Schema中设置的分类权重是从0.1~1。但我认为太细了。一个评阅人很难评阅出关联度到底是几。所以是否可以考虑1、0.6、0.3这三个档次,分别表示非常关联、很关联和有些关联。这样反而会提高分类准确度。因为每个评阅人的心理评价标准各不相同,如果一个人认为0.5,另外一个人可能认为0.6,这样的化还不如设置三个权重档次好。
既然是XML,那么要求所有文章的HTML必须遵循XML规范,这可以使用FrontPage 2003实现。将修正好的HTML放到MainContent节点下面(不要忘了命名空间的事![]() )。
)。