在互联网市场的头部效应下,企业所面临的竞争压力越来越大,如何有效解决获客成本高、用户黏性低、变现能力弱等问题,正是越来越多的企业开始构建大数据平台的初衷。
但由于大数据解决方案所涉及的组件错综复杂、技术门槛较高,且初期投入的资源和后期的维护成本较大,十分考验企业的大数据平台组建和运维能力。因此,UCloud大数据团队于近期上线了大数据智能平台(UCloud Smart Data Platform,下文简称 USDP) ,旨在帮助企业快速搭建大数据分析处理平台,并对大数据集群进行集中管理,从而降低企业的大数据开发、维护成本。
一站式大数据智能管理平台
USDP是帮助企业构建云端托管型的一站式大数据采集、存储、分析、应用和运维的智能平台。其产品架构图如下:

从上图可以看出,USDP是构建在UCloud公有云IaaS基础资源之上,提供 Hadoop生态的服务系统,如HDFS、Hive、HBase、Spark、Flink、Presto、Atlas、Ranger 等众多开源大数据服务组件,并对这些组件进行配置管理、监控告警、故障诊断等智能化的运维管理,从而帮助企业快速构建起大数据的分析处理能力。
用户可通过 USDP 方便快速地部署大数据集群中的各类服务与组件,并集中式地运维这些组件。且在部署服务与组件的过程中,USDP 可以全自动化完成整个流程,大大降低了部署成本。
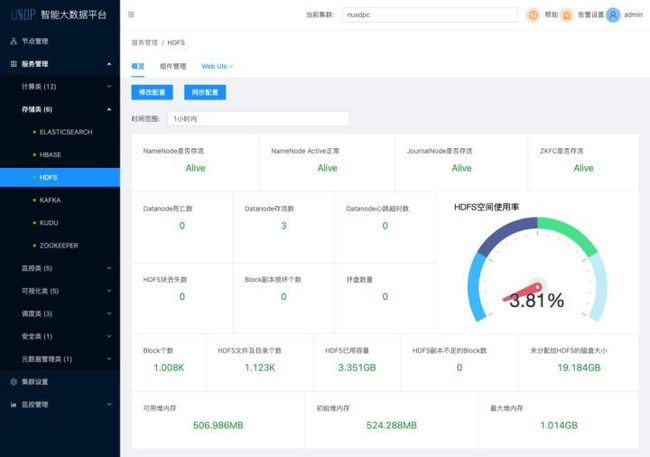
同时,USDP 中集成的实时监控视图与告警策略可以帮助运维人员及时获取异常告警信息,快速定位和排查问题。
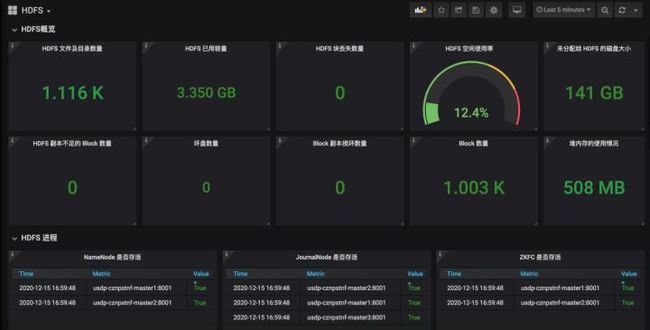
除此之外,USDP 高度集成了 Hadoop 生态中的服务与组件,并且全部基于 Apache 版本完成适配,无深度修改,因此用户无需担心服务组件使用过程中造成的 API 不兼容问题,用户业务也无需担心被非 Apache 开源协议之外的服务框架所绑定。
轻量级、自动化运维的大数据“管家”
USDP 作为纯国产化、UCloud自研的大数据管理服务,可以实现云上、云下交互的便捷统一,其具体特点如下:
- 全面的组件支持
基于开放式的管理架构,USDP 集成了 30 余款开源的大数据组件,涵盖数据集成、数据存储、计算引擎、任务调度、权限管理等大数据处理的各个环节,全面性为业界之最。企业可以根据自身业务特点和需求,从中选择相应的组件来搭建自己的大数据处理平台。
- 完善的监控告警机制
源自多年的大数据运维经验积淀,USDP 为每款组件预置了完善的监控和告警模板,丰富的监控指标和灵活的告警方式,帮助用户及时掌握各个组件的运行状况,进行必要的维护和优化。与此同时,智能化的故障诊断工具和专业的技术支持团队,为大数据集群的稳定运行保驾护航。
- 可视化工作流UDS
UDS(UCloud Data Studio)是一款UCloud自研的轻量级、分布式、易扩展的可视化DAG工作流任务调度系统。通过拖拽式的工作流开发 IDE,简单 Web 式拖拽操作来完成整个大数据工作流的任务开发。内置了丰富的处理器,多样化的任务支持:Shell、Python、Hive、Spark、MR、SQL、子流程等。
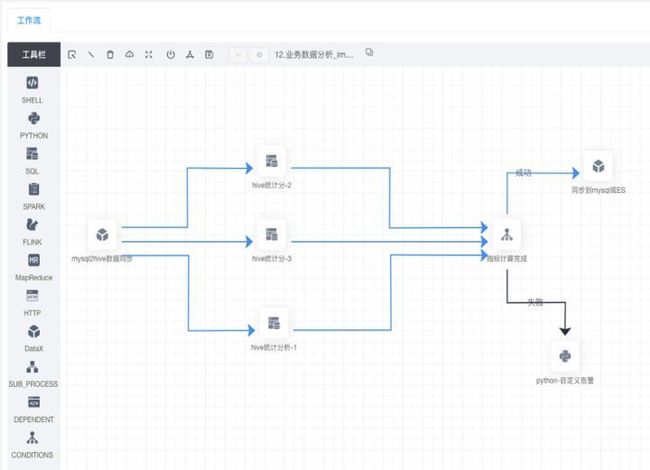
UDS提供可视化的流程定义能力,可对大量异构数据源提供高速稳定的数据集成能力,并在同步过程中实现对数据的ETL操作。
- 安全稳定
公有云USDP 的底层资源为用户所独享,集群位于独立的虚拟私有网络中,实现了有效的安全隔离。同时,USDP 集成的各个组件编译自 Apache 社区稳定版本,经过了严格的兼容性测试和压力测试,关键性组件都支持高可用特性,确保集群稳定可靠运行。
- 弹性易用
针对大数据应用场景,公有云USDP 提供了丰富多样的机型(大数据物理机、普通云主机、快杰云主机等)供用户选择,并结合公有云的弹性伸缩能力,有效控制实际使用成本。向导式的操作流程和完善的场景案例,帮助用户轻松上手。
- 支持私有化部署
USDP除了与UCloud公有云IaaS集成,还可以作为独立的大数据组件管理平台部署在私有化的数据中心,并兼容虚拟机、物理服务器环境。为私有化部署的客户提供与公有云体验一致的大数据平台服务。
UCloud还提供基于USDP的软硬一体交付方案,已提前预装完成USDP服务,实现用户插电即用的大数据平台管理服务。

典型应用场景
1、数据仓库目前国内最常用的数仓模型为维度数仓,就是按照事实表、维度表来构建数据仓库、数据集市。在该体系中,维度是描述事实的角度,如日期、客户、供应商等,事实是要度量的指标,如客户数、销售额等。通过 USDP,用户可以部署构建维度数仓所需的一切服务,帮助企业快速构建数据中台。
2、机器学习在机器学习领域,对运算往往有大量需求,通过 USDP 中的Spark、Flink 等分布式运算框架,搭配官方算法或自研算法,即可事半功倍的进行机器学习开发。同时,在深度学习领域,建模所需的大量数据,也可以存储于 HDFS,从而真正实现一站式开发。
3、实时计算可以利用USDP中的Kafka、Flink、Spark Streaming对数据进行实时处理,来满足实时风控、实时推荐、实时日志分析、实时点击等场景需求。
总结
大数据时代,数据作为企业的核心生产要素,其隐藏的商业价值离不开大数据技术的深度挖掘,而USDP的推出正是为了解决目前企业构建大数据解决方案所面临的高成本、高技术门槛等问题,助力更多企业快速构建大数据服务,充分释放数据生产力的商业价值.