【摘要】
面对高并发账户记录查询问题,按照本文的介绍一步一步操作,就能有效提升性能。点击了解高并发账户记录查询
问题描述
高并发账户记录查询在银行、互联网企业、通信企业中广泛存在。例如:网上银行、手机银行、电商个人账户查询、互联网游戏账户等等。这类查询有三个共同点:
1、 数据总量非常大。用户数量本身就非常多,再加上多年的账户数据,数据量可以达到几千万甚至上亿条。
2、 访问人数众多。几百万甚至上千万人访问,属于高并发查询。
3、 不能让用户等待。手机、网页要达到秒级响应,否则严重影响用户体验。
下面以某银行账户活期明细查询为例,给出这类问题的解决办法。
某银行共一亿个活期账户,每个账户平均每月有 7 条数据,每年数据总量 84 亿条。每条数据中的机构字段,还要关联分支机构表(几千条)记录。在性能上,要求单台服务器支持一千个以上的查询,响应时间不能超过 1 秒。
有序行存
活期明细数据随着时间增长非常快,一年就有 84 亿条。如果放到内存中,需要大量内存空间,硬件投入成本太高,所以要放到硬盘上存储。分支机构表只有几千条数据,可以放在内存中存储。
在硬盘上存储,要考虑是行存还是列存。列存数据分块压缩,能减少遍历数据量。但由于账户查询是随机的,整块读取会有额外解压计算。而且每次取数都针对整个分块,复杂度较高,性能不如行存。因此,这个场景要选择行存存储,如下图:
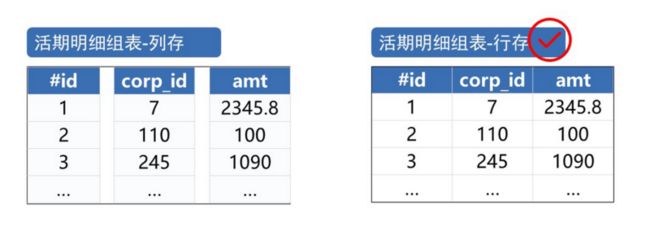
图 1:行存和列存
具体的实现可以采用 Java、C++、SPL 等高级语言。这里我们以代码量最少的 SPL 语言为例讲解。

代码示例 1
A1:连接生产数据库,用游标读取活期存款数据,按照账户 id 排序。
A2:建立本地组表文件。
A3:建立组表,并从数据库游标读取活期存款明细数据,写入文件。
其中,A3 中的 @r 选项,就是建立行存文件。一年 84 亿条数据都导出,时间会比较长。但是这是一次性的工作,后续就只需要追加增量数据即可。增量数据的追加方法,后面会有介绍。如果按照账户排序会对生产数据库造成较大压力,可以导出之后基于文件排序。排序使用 SPL 的 sortx 函数,具体用法参见函数参考。
利用索引
要利用索引提速,先要对明细文件建立索引。由于明细数据量大,建立的索引文件也会很大。很难全部加载到内存中。可以建立多级索引,如下图:

图 2:多级缓存
还是以 SPL 为例,建立多级索引,只需要在“代码示例 1”的基础上,增加一个网格即可:
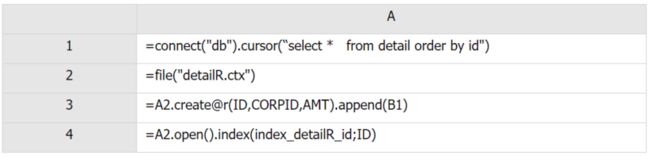
代码示例 2
A4:对行存文件建立索引文件。
加载的索引级别越多,占用存储空间越大。同时,账户 id 的跨度变小,加载到内存中后,索引效果也会变好。查询时可以根据内存大小,尽可能加载更多级别的索引,可以有效提高查询速度。
在查询之前,系统初始化或者数据变动时,要预先加载多级索引,以 SPL 代码为例:

代码示例 3
A1:判断全局变量中是否存在 detailR,如果存在,表示已经加载了索引。
B1:如果全局变量中没有 detailR,那么打开组表加载三级索引。@2 或者 @3 表示加载 2 或者 3 级索引。
B2:detailR 存入全局变量。
这段预先加载的初始化代码(代码示例 3),可以保存成 init.dfx,放入集算器主目录(main path),在节点机(unitServer)启动的时候会自动被调用,如下图:
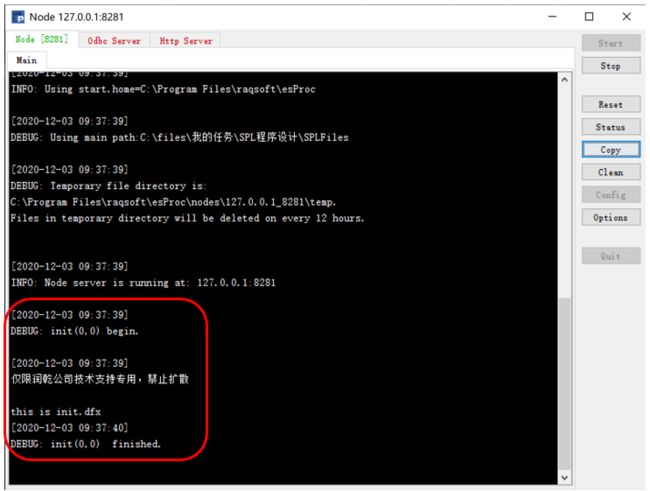
图 3:节点机自动调用初始化代码
由于我们提前准备好的活期数据是对账户 id 物理有序的,查询时根据索引找到账户 id 后,可以在硬盘连续读取,显著减少磁盘 IO,有效提速,如下图:

图 4:索引和有序行存
查询账户 10100,先利用内存中预先加载的多级索引和索引文件,快速定位到活期明细数据文件中的位置,再连续读取到账户 id 有变化为止。因为数据是按照账户 id 物理有序的,所以文件的其他位置不可能再有 10100 账户的数据了。
利用索引查询的示例代码如下:
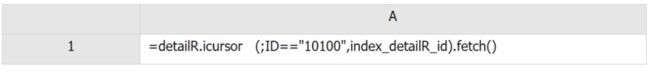
代码示例 4
A1:全程变量 detailR 已经缓存了三级索引,现在可以基于它利用索引,按照条件取出账户为 10100 的记录。
每个账户的数据量并不大,所以可以全部读入内存。
活期明细前端应用(网页或者 APP),要通过集算器的 JDBC 驱动调用 SPL 代码查询。调用的时候,需要将账户 id 作为参数传给 SPL 程序。例如:定义一个网格参数 countid,传入账户 id 为 10100。A1 中的代码就要改为:=detailR.icursor (;ID==countid,index_detailR_id).fetch()。
关联查询
查到指定账户数据装入内存后,可以将机构数据也读入内存。在内存中关联计算,性能可以得到保障。示例代码如下:
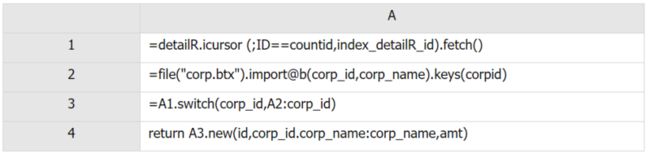
代码示例 5
A2:读入机构数据。
A3:账号 10100 的活期明细数据关联机构数据。
A4:将账户 id、分支机构名称和金额返回给前端调用者(网页或者 APP)。
机构数据可以在应用系统初始化的时候加载入内存,不必每次读取,查询速度更快。在上面提到的 init.dfx 中增加代码如下:
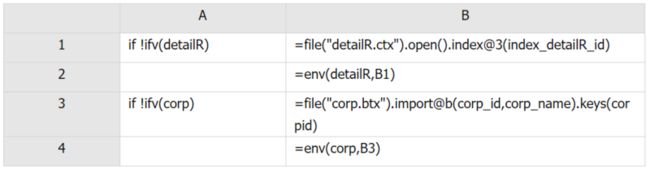
代码示例 6
预先加载机构数据之后,查询代码要在“代码示例 5”的基础上去掉加载机构数据的部分,修改之后的查询代码如下:
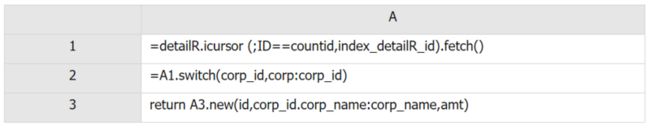
代码示例 7
A2:直接用预先加载的全程变量 corp 和活期明细数据关联计算,省去了每次查询加载机构数据的时间。
数据更新
活期明细存款是按账号有序的,并不是按日期有序。所以,不能在末尾追加当日新增数据。活期明细几十亿条,如果每天有序归并新数据的话,耗时太长。每月归并一次的方案比较理想。如果将活期明细数据看成是主文件,那么更新原理如下图:
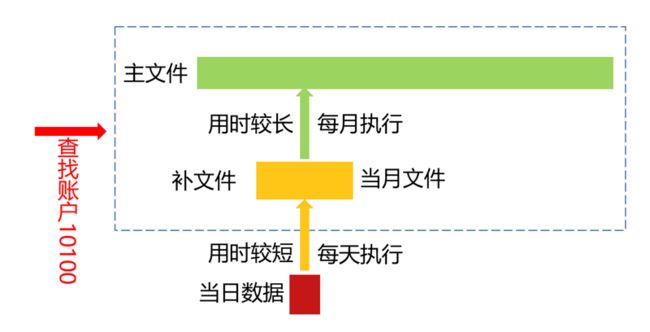
图 5:数据更新
数据更新的示例代码如下:

代码示例 8
A1、B1:如果是每月 1 日,重整文件。
A2:从生产数据库中读入当日数据。
A3:将当日数据有序归并到集算器自动生成的补文件中。