Python爬虫入门学习实践——爬取小说
前言
本学期开始接触python,python是一种面向对象的、解释型的、通用的、开源的脚本编程语言,我觉得python最大的优点就是简单易用,学习起来比较上手,对代码格式的要求没有那么严格,这种风格使得我在编写代码时比较舒适。爬虫作为python的最为吸引我兴趣的一个方面,在学习之后可以帮助我们方便地获取更多的数据源,从而进行更深层次更有效的数据分析,获得更多的价值。
爬取小说思路
首先我们肯定是对小说网站进行观察,辨别小说网站是静态还是动态的,此次爬取的目标(这里发现网址与上次爬取时的网址有所变化),任一点开一本小说的任一章节通过F12的Elements选项可以检查到文章内容存在于 div id=‘content’ 标签中,所以说爬取的目标是静态的。当然,有人会问,使用动态的Selenium可以爬取吗?答案是肯定的,当然网站是静态的我们就没有必要舍近求远的使用动态方法求得结果。

然后选取目标小说之后,点击小说目录页面,通过F12的Elements选项可以观察到小说所有章节的url都是有规则的。
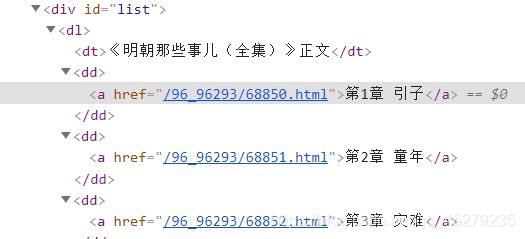
爬取到所有章节的url之后保存,对获取的章节url进行完善之后在进入每一章节对标题和正文内容进行爬取,最后保存到txt文件当中。
功能模块实现
理清我们的思路之后,按照步骤一步一步完成功能。
1.使用request请求库和数据清洗匹配的re库
import requests
import re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。注意:(1)re模块是python独有的;(2)正则表达式所有编程语言都可以使用;(3)re模块、正则表达式是对字符串进行操作。
2.对目标网站发送url请求
s = requests.Session()
url = 'https://www.xsbiquge.com/96_96293/'
html = s.get(url)
html.encoding = 'utf-8'
3.对网站目录页查找所有章节的url
# 获取章节
caption_title_1 = re.findall(r'.*?',html.text)
4.对获取所有章节的url进行完善方便再次访问
for i in caption_title_1:
caption_title_1 = 'https://www.xsbiquge.com'+i
5.对获取的每一张url进行访问寻找标题和正文内容
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8'
# 获取章节名#meta是head头文件中的内容,用这个获取章节名
name = re.findall(r'',r1.text)[0]
print(name)
#这里print出章节名,方便程序运行后检查文本保存有无遗漏
chapters = re.findall(r'(.*?)',r1.text,re.S)[0]
![]()
6.对获取的正文内容进行清洗
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 转换字符串
s = str(chapters)
#将内容中的<br>替换
s_replace = s.replace('
',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)#使匹配对大小写不敏感
fiction = pattern.sub(' ',s_replace)
7.将数据保存到预先设定的txt中
path = r'F:\title.txt' # 这是我存放的位置,你可以进行更改
#a是追加
file_name = open(path,'a',encoding='utf-8')
file_name.write(name)
file_name.write('\n')
file_name.write(fiction)
file_name.write('\n')
#保存完之后关闭
file_name.close()
运行结果

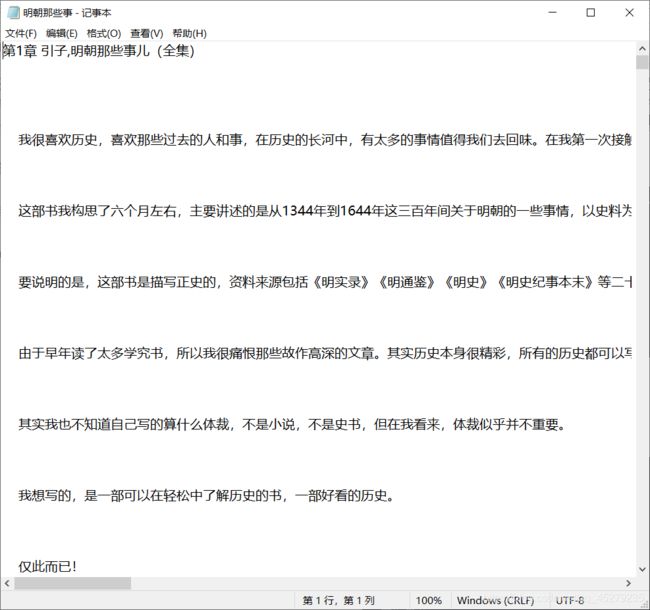
程序源码
import requests
import re
s = requests.Session()
url = 'https://www.xsbiquge.com/96_96293/'
html = s.get(url)
html.encoding = 'utf-8'
# 获取章节
caption_title_1 = re.findall(r'.*?',html.text)
# 写文件+
path = r'F:\title.txt' # 这是我存放的位置,你可以进行更改
#a是追加
file_name = open(path,'a',encoding='utf-8')
# 循环下载每一张
for i in caption_title_1:
caption_title_1 = 'https://www.xsbiquge.com'+i
# 网页源代码
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8'
# 获取章节名
#meta是head头文件中的内容,用这个获取章节名
name = re.findall(r'',r1.text)[0]
print(name)
file_name.write(name)
file_name.write('\n')
# 获取章节内容
#re.S在字符串a中,包含换行符\n,在这种情况下:
#如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
chapters = re.findall(r'(.*?)',r1.text,re.S)[0]
#换行
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 转换字符串
s = str(chapters)
#将内容中的<br>替换
s_replace = s.replace('
',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)#使匹配对大小写不敏感
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
file_name.close()
- 关于 re 使用,参考 这儿。
总结
通过对该项目的锻炼,设计并实现系统整体的功能模块,使我受益颇深,尤其是在数据挖掘和数据分析方面有了更加深入的认识,同时也提升了自我学习的能力,为日后的学习和工作奠定了基础。程序代码实现了爬取小说的功能,对数据进行了清洗。但这只是对一本小说进行爬取,如果想对全站小说进行爬取,可以在功能模块上再添加一个大的循环获取网站所有小说的url就可以实现了。这是我的想法以及实现,如果你有其他的思路,可以评论交流一下,大家互相学习进步。