【社区分享】从零开始学习 TinyML,建立 TensorFlow 深度学习模型(基础原理篇)
TinyML 是什么?如何入门学习?本教程将从介绍 TinyML 基础原理入手,通过代码实例展示,从零开始逐步带你体验使用 Keras 训练小模型,了解如何构建一个完整的基于 TensorFlow 的工程系统和深度学习网络。一起来学习吧!

本文来自社区投稿与征集,作者王玉成,ML&IoT Google Developers Expert,温州大学智能锁具研究院总工程师。了解更多:https://blog.csdn.net/wfing
TinyML 简介
1. 概要
Pete Warden 与 Daniel Situnayake 合著了一本介绍在 Arduino 和超低功耗微控制器上如何运行 ML 的书, TinyML:Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers,这本书由 O’Reilly 于 2019 年 12 月 13 号出版。
我作为国内 IoT 和 ML 两个方向的 GDE,对 AI 在嵌入式系统和物联网上的应用也一直在持续关注。得到书本出版的消息之后,就迫不及待的入手了一本英文原板纸质书,看后爱不释手,同时也想以书本的概念为原型,把如何去搭建 TinyML 完整的工程流程分享给大家。
2. ML 以及 TinyML 简介
在阅读本文之前,我先简单介绍一下 TinyML 。
Machine Learning (ML) 这一个学科,在学术界有 40 年左右的历史,但是前面的 30 多年研究,只是在学术上有一些突破。
真正让 ML 从学界走入产业界的划时代改革的里程碑,源于 2010 年 ImageNet 挑战赛 (ILSVRC)。2012 年,Hiton (ML 业界元老级人物) 课题组首次参加 ImageNet 图像识别比赛,AlexNet 夺得冠军,并碾压了第二名 (SVM) 的分类性能。ML 在工业应用的热情在这一年被彻底点燃。
ML 最近几年已经在工业、消费领域获得了大量的应用,随着云资源的不断完善,研发了更多的激动人心的 AI 模型。云端 AI 的应用,已经获得长足的进步。
在 ML 的工业应用发展的这几年,物联网也处于快速处在发展期。从最早的智能家居,到现在遍地的物联网智能设备。AI 应用逐步从云端走向了设备端,现在设备端的 AI 应用已经占了很大的比例,手机上 AI 的应用已经非常普遍。
但是,在物联网世界里,有数以亿计的体积小、功耗低、资源受限的设备支撑着物联网应用。如何在超低功耗 (mV 功率范围) 的设备上运行人工智能应用,同时又要满足设备长时间低功耗的运行 AI 应用的需求,已经形成了一个新的课题。
TinyML 指的是在 mW 功率的微处理器上,实现机器学习的方法、工具和技术。它连接了物联网设备,边缘计算和机器学习。
TinyML 基金会在 2019 年组织了第一届峰会,这届峰会的成果如下:
-
TinyML 的技术硬件已经进入了实用性的阶段;
-
算法,网络以及低于 100KB 的 ML 模型,已经取得重大突破;
-
视觉,音频的低功耗需求快速增长。
TinyML 将在以后几年,随着智能化的发展,获得更快的发展。这一领域也有着巨大的机会。
3. 书籍作者介绍
Pete Warden 原是 Jetpac 的 CTO 和创始人。于 2014 年正式加入 Google,现在为移动和嵌入式端 TensorFlow 的技术负责人(Technical Leader)。需要解释一下的是 Jetpac 公司拥有强大的分析社交媒体照片能力,为旅行者提供城市指南服务,这家公司在 2014 年被 Google 收购。
Daniel Situnayake 曾是 Google 的TensrorFlow Lite 的技术推广工程师 (Developer Advocate),同时一直积极参与 Meetup 上 TinyML 社区的工作。他也是美国第一家以工业自动化的方式生产昆虫蛋白质的公司 Tiny Farm 的联合创始人。
两位作者中的一位侧重于物联网上的 AI 技术研发,另一位则侧重于运用 AI 技术去实现工业化,他们强强联合出版了这本书,带我们进一步探索物联网端 AI 的所有技术环节工业化实现,原汁原味的体现了利用 Google 的技术去促进发展的思考脉络。
4. 开发环境
作为开发环境,我们只需要在电脑上用 USB 接口实现外设接入就行了。当然根据每一个读者的习惯,可以用自己所熟悉的编译工具来编译这个环境,所有的这些代码都可以在 Windows,Linux 或者 macOS 上运行。当然,已经训练出来许多模型在 Google Cloud 中可以下载。也可以用 Google Colab 来运行所有的代码。就不必要去担心需要拥有独特的硬件开发环境。
推荐使用大概 $15 可以买到的 Spark Fun Edge 开发板。由于在这本书发布的时候。Spark Fun 的第 2 版已经开发出来了,并可支持运行所有的示例项目。读者对硬件开发板的硬件版本兼容性亦无需太多担心。
当然,也有另外两款开发板的支持:Arduino Nano 33 BLE 和 STM32F746G 开发板,开发者可以根据自己的需求灵活选用。
我们这一系列主要分享如何用 Arduino Nano 33 BLE 开发板运行最简单的示例代码。
5. 软件准备
这本书所有的项目是依赖于 TensorFlow Lite 在微控制器上的开发框架,所依赖的硬件环境,只有几十 kb 左右的存储空间。
我们也知道,对于开源软件来说,由于软件不断的更新,包括优化,bug 修改以及其他设备的支持,造成代码一直在不断的变动。或许书中举出例子的代码跟 Github 的代码不太一致,但是最基本的原则是相通的。
在软件开发中间,我们也可以选择适合自己的 IDE 开发工具。但是由于我(非原书作者,是本人)已经用于 Linux 很多年,是 Vim 的死忠粉,所以我后面给大家介绍的内容全部是基于 Vim+ 终端的模式进行讲解。如果涉及到开发工具相关的问题,欢迎在本文末留言,我们一起讨论。关于命令的运行,在 Linux 和 macOS 中,我们很轻易的用终端。在 Windows 系中,可以用命令行工具去解决开发问题。
嵌入式开发另外一个问题就是需要和开发板进行通讯。如果用 Spark Fun 开发板,需要用 Python 命令来做项目的编译,如果用 Arduino 开发板,只需要在 Arduino 的开发环境中,加载开发包就可以了。
6. 机器学习工程化流程
整个机器学习工程部署的大体流程如下:
-
确定目标
-
收集数据集
-
设计模型架构
-
训练模型:注意一下过拟合和欠拟合所产生的各种问题
-
转换模型
-
运行推断
-
评估并排除故障
工程流程一般都是基于以上的步骤进行部署的。在下一章中,我们将用学习任何语言的经典入门 “Hello World”,来阐述基于项目的 TinyML 工程开发流程。
Hello World — 梦开始的地方(上)
Hello World 是每一个程序员进入程序世界,学说的第一句话。它的意义并不在于可以以一种特殊的方式去输入一串字符,而在于用一句简单的话,去了解最基本的流程,为自己的新世界打开一扇大门。
我们将 “Hello World — 梦开始的地方”分为上、中、下,三个部分来讲述如何去构建一个完整的、可以运行的、基于 TensorFlow Micro 的工程系统。其中上篇是手把手教开发者如何去建立并且训练模型,中篇主要讲解如何创建工程应用,下篇主要是讲解如何把工程部署到微控制器上。
事不宜迟,我们赶紧进入上篇吧。
1. 环境准备
项目在三个不同的开发板上都可以正常运行,我们以 Arduino Nano 33 BLE Sense 为硬件,来实现基于 TensorFlow 的 ML 项目。
2. 项目流程
实现基于微控制器的 ML 项目开发流程如下所示:
1. 获得简单数据集
2. 训练深度学习模型
3. 评估模型性能
4. 转换成设备上运行的模型
5. 将代码转换成二进制文件
6. 部署二进制文件到微控制器
文章中所有的代码都基于 TensorFlow Micro 上的代码。当然,代码中也包括许多注释,我们会一一的分析代码中的最关键的部分以及为何要这么实现。
3. 准备前的工作
我们分享的 Hello World 示例,是用数学中的最基本的sine函数为原型,用 ML 的方式去预测数据。关于 sine 函数,我们在初中学三角函数时就接触过。这个函数在工业应用中非常广泛。一般的函数图形如图所示:
我们的目标是,如果有一个 x 值,我们能够预测出 x 的 sin 值 y。在真实的环境中,用数学计算的方法可以更快速的得到结果。这个例子是用 ML 的方法去实现预测,从而了解 ML 的整个流程。
整从数学角度来看,sine 函数能够在 -1 到 1 之间,周期性的平滑波动。我们可以用这种平滑的值,来控制 LED 灯光的亮度。
利用 Arduino 开发板运行这个项目的效果如图所示:

工具准备:
配置开发环境,所用的编程语言当然是当之无愧的 Python,这是现在使用最广泛的,运用于科学、数学、以及 AI 领域的编程语言。版本为 3.x Python 可以在命令行下运行,但是还是推荐用 Jupyter Notebook 来开发,它的好处是可以把代码、文档、还有图片放在一起,既能当教程,又能分步运行。
如果有条件上 Google Colab,这个编译环境也是一个很好的选择。Colab 一直是由 Google 开发并维护的平台,并且在云平台上,已经安装了各种依赖软件。并且还可以免费去用 Google TPU 的服务。通过 Web 浏览器,可以运行自己编写的任何代码。甚至可以用 Colab 的配置文件,来选择加速硬件,从而加速模型训练。
ML 平台的选择,毫无疑问,选择 TensorFlow。因为 TensorFlow 是现在使用最广泛的AI加速平台,并且有成熟的 pip 安装包可以用。当然,在接下来的应用中,我们需要用 TensorFlow Lite,能得模型在嵌入式硬件上运行,我们也会用 TensorFlow 的高阶 API,Keras 来完成一些编程工作。
4. 创建模型
- 项目相关代码
当然,如果在 Google Colab 上运行项目,可以直接运行。
我们就在本地以 Jupter notebook 的方式,运行我们的代码。我是以 git clone 的方式下载了 TensorFlow 的所有源码,从本地的 Linux 命令行进行操作。由于我运行环境的 Linux 系统,已经安装了所有的依赖软件,所以在 Jupter 的环境中,涉及到 Linux 中相关的 pip 安装和 apt 安装的代码都注释掉了。
首先运行 Jupyter:
![]()

启动之后弹出 chrome 浏览器,内容如图所示:
![]()
其中需要注意的是,在右上角的区域,如果提示不受信任,点击“不受信任”的文字,按提示操作,最终文字变成“信任”。如果说右上角区域 Python 版本为 2,那么需要在 Jupyter 的菜单栏中,Kernel Change Kernel 中选择 Python 3。
当然,代码的第一步是导入 TensorFlow、Numpy、Matplotlib 以及Math 库。其中 Numpy 用于数据处理。Matplotlib 用于数据的可视化。

其实在代码中,我注释掉了 #!pip install tensorflow==2.0.0-beta0 这一行,原因是因为我的 PC 机已经安装完了 TensorFlow 的最新版。
5. 产生数据
首先基于 sin 函数产生一系列的标准化数据。

可以看出,运行之后,数据相当规范。作者为了让大家细致入微的去理解代码,对这一段代码做了一些解释说明。当然,如果是要处理数据的话,Numpy 是一个最优的数学处理函数库。x_values = np.random.uniform(low=0, high=2*math.pi, size=SAMPLES), 用来产生特定范围内的一系列随机数。
当原始数据产生之后,我们要接着做的事情,便是数据清洗。我们要确保数据以真正的随机的方式反馈。很幸运,Numpy 的radom.shuffle()提供了这样的方法。
最后再把数据以二维坐标的方式画在图片上。
这么漂亮的数据,直接去训练可好?当然没有问题,但是,ML 做的是什么样的事情?从各种噪音中筛选数据,经过训练,最后预测的准确率越来越高。第一部操作,我们需要加入一些噪音进来。这也是机器学习中常用的方法。当样本的容易不够时,我们如何增加样本的数量,以便训练时准确率更高。
![]()

我们就完全创建的所有的数据。
接下来便是分成训练集和测试集:
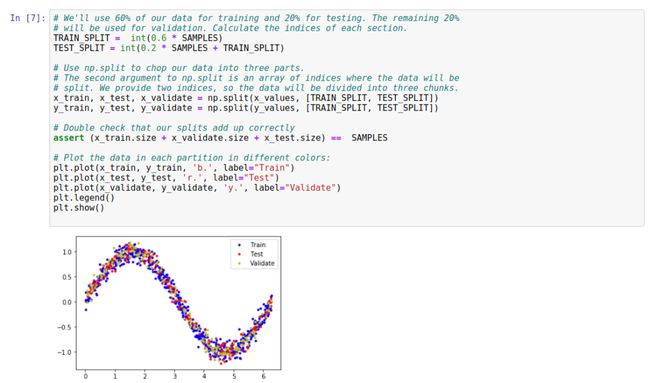
就这一部分的关键代码详细解释一下:
TRAIN_SPLIT = int(0.6 * SAMPLES)
TEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT)
整个数据集包括三个部分,训练集,测试集,验证集。示例中用了 60% 的数据当训练集,20% 的数据当测试集,20% 的数据当验证集。这个比例不是恒定的,可以按需求调整。
x_train, x_test, x_validate = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT]),虽然输入参数中只包括了训练的测试的部分,但是由于整个数据集分割了三部分,所以 np.split 的返回结果是三个,代码我们的三种场景。
6. 定义基本模型

我们用 Keras 来构建最开始的模型。
第一层采用标量输入,并且基于 “relu” 激活,用了 16 个神经元的密集层 (Dense Layer,也可叫做全连接层)。当我们进行预测时,它是推理过程中的神经元之一。每个神经元将然后被激活到一定程度。每个神经元的激活量是基于在训练过程中获得的 weight 和 bias 值来定义激活功能。神经元的激活将作为数字输出。激活是通过一个简单的公式来计算的,如 Python 中所示。我们将永远不需要自己编写此代码,因为它由 Keras 和 TensorFlow 处理, 在深入学习时但会有所帮助,计算公式的伪代码如下所示:
activation = activation_function((input * weight) + bias)
要计算神经元的激活程度,需要将其输入乘以权重和偏差被添加到结果中。计算出的值被传递到激活函数中。结果就是神经元的激活。激活函数是一种数学函数,用于塑造神经元的输出。在我们的网络中,我们使用的是称为整流线性单元 (Rectified Linear Unit) 的激活函数,或简称为 ReLU。这在 Keras 中由参数 activation = relu 指定。ReLU 是一个简单的函数,如 Python 所示:
def relu(input):
return max(0.0, input)
ReLU 返回较大的值:如果其输入值为负,ReLU 返回零。如果其输入值大于零,则输出保持不变。
用 ReLU 做为激活函数意义在哪儿?
没有激活函数,神经元的输出将始终是线性函数.这意味着网络只能建模线性关系,其中 x 和 y 之比在整个值范围内保持不变。但是正弦波又是非线性的,这将阻止网络对我们的正弦波进行建模。由于 ReLU 是非线性的,因此它允许多层神经元联合作用并建立模型复杂的非线性关系,每次x增量不会使y值以相同的方式增加。还有其他激活功能,但是ReLU是最常用的功能。作为ML算法,运用最优的激活函数是必要的。
我们再对输入、输出层做一些解读:
由于输出层是单个神经元,它将接收 16 个输入。由于这是我们的输出层,因此我们不指定确定激活功能-我们只需要原始结果。由于此神经元有多个输入,因此每个神经元都有一个对应的权重值。神经元的输出通过以下公式计算得出,如 Python 中所示:其中 “inputs” 和 “weights” 都是 NumPy 数组,每个数组有 16 个元素
output = sum((inputs * weights)) + bias
通过将每个输入与其对应的乘积获得输出值 weights,对结果求和,然后加上神经元的 bias。该网络的 weights 和 bias 是在培训期间学习的。
接下来,编译阶段的关键点,便是优化器的损失函数了。
model_1.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])其中优化器,损失函数以及指标,都有许多种选择,我们不展开详述。您可以去以下链接去做更多的了解。
-
https://keras.io/optimizers/
-
https://keras.io/losses/
最后我们再来看看模型概况:

其中输入层有 16 个神经元,共 2 层连接,所以全部的连接数为 16x2=32,每一个神经元都有一个 bias,网络总共有 17 个 bias。输入的 16,以及输出的 1。所以总的参数为 32+17=49。
7. 训练模型
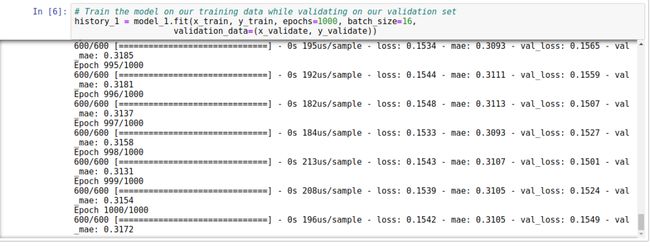
利用 keras 的 fit() 方法能够很好的训练。下面就一些参数做一下最基本的解释:
-
X_train, y_train 表示最基本的训练数据。
-
epochs 训练的周期,一般来说,周期越长,训练越精确,但是,一般来说,训练的时间到一定阶段,训练精度不会有很大差别。在这种清况下,一般要考虑去优化模型了。
-
batch_size 用于往网络中一次送入多少数据,如果值为 1,我们每一次会更新 weight 和 bias,并且会估计网络预测的损失,为下一次的运行做更精确的估计。越小的值,会带来很大的计算量,占用更多的计算资源。如果我们把值定要 600,一次性可以计算出更多的数据,但是会降低模型的精度。所以最好的方式是把值设置为 16 或者是 32。这个值的选择,实际上精度与时间花费权衡的结果。
接下来,我们最关心的,当然是训练的结果了。

该图显示了每个时期的损失(或模型的预测与实际数据之间的差异)。有几种计算损失的方法,我们使用的方法是均方误差。对于训练和验证数据有明显的损失值。
我们可以看到,损失的数量在前 25 个时期迅速减少,然后趋于平稳。这意味着该模型正在改进并产生更准确的预测!
我们的目标是在模型不再改善或训练损失小于验证损失 (Validation Loss) 时停止训练,这意味着该模型已经学会了很好地预测训练数据,也不需要新的数据来提高精度。
为了使图表的平坦部分更具可读性,我们用代码 SKIP = 50 跳过前 50 个 epochs,这仅仅是便于我们看图方便。
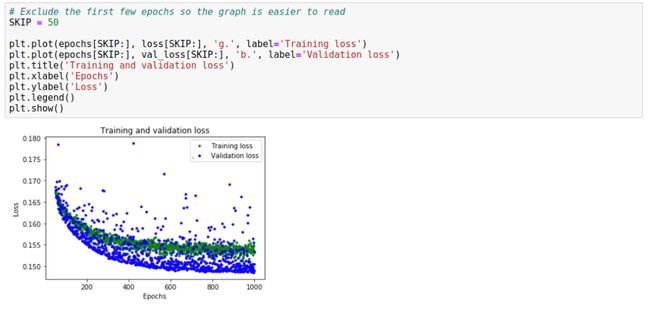
从图中可以分析出,大概 epochs 到了 600 左右,训练开始趋于稳定。意味着我们的 epochs 应该不需要超过 600。
但是,我们还可以看到最低的损失值仍在 0.155 左右。这意味着我们网络的预测平均降低了约 15%。另外,验证损失值 (Validation loss) 产生的很大的跳跃,并不稳定。我们需要改进方法。这次,我们将绘制平均绝对误差 (Mean Absolute Error)图,这是另一种衡量网络预测与实际数字的距离的方法:

从平均绝对误差图可以看到,训练数据显示出的错误始终比验证数据低,这意味着网络可能存在过拟合 (Overfit),或者过分地学习了训练数据,从而无法对新数据做出有效的预测。
此外,平均绝对误差值非常高,最多约为 0.305,这意味着该模型的某些预测至少可降低 30%。30% 的误差意味着我们离精确建模正弦波函数还很遥远。
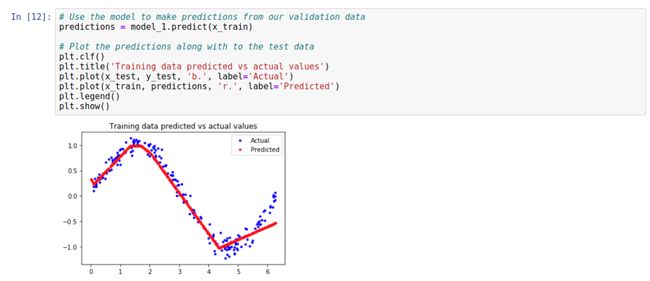
该图清楚地表明,我们的网络已经学会了以非常有限的方式近似正弦函数。从 0 <= x <= 1.1 开始,该行最适合,但是对于我们的其他 x 值,充其量只是一个大概的近似值。
结果表明,该模型没有足够的能力来学习正弦波函数的全部复杂度,因此只能以过于简单的方式对其进行近似。通过优化模型,我们应该能够改善其性能。
8. 优化模型
优化的关键是增加全连接层,这一层包含了 16 个神经元。
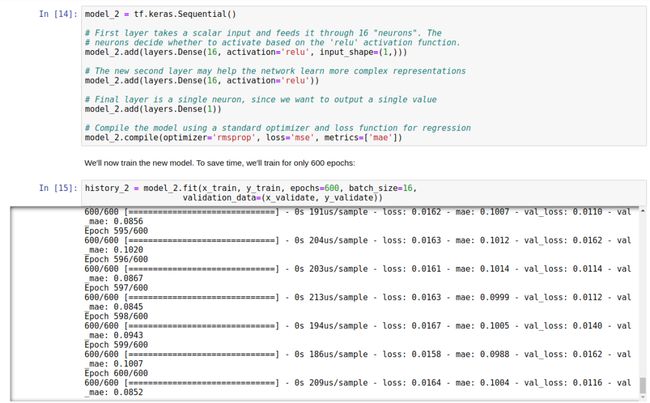
我们再对模型做评估:


通过图片分析,我们的网络达到了峰值精度的速度要快得多(在 200 个时期内,而不是 600 个时期内)。总损失和 MAE 比我们以前的网络要好得多。验证结果比训练结果更好,这意味着网络不会过度拟合。验证指标优于训练指标的原因是,验证指标是在每个时期结束时计算的,而训练指标是在整个时期计算的。
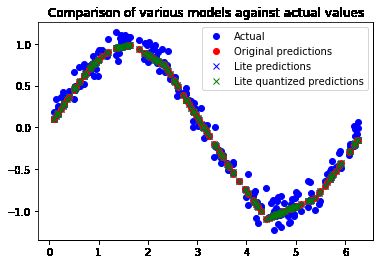
这一切都意味着我们的网络似乎运行良好!为了确认这一点,让我们对照我们先前放置的测试数据集检查其预测:

最终的测试结果如下所示:
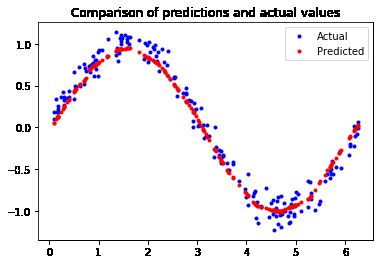
我们来看这张图片,并不能说明这预测值完全跟 sine 的曲线一模一样。但是现在预测精度不是主要问题了,我们只想通过平滑的曲线来对开关进行控制。模型精度已经足够了。
9. 模型转换
模型转换的要点,就是 TensorFlow 到 TensorFlow Lite 的转换。其中有两个主要的组成部分:
TensorFlow Lite 转换器 (TensorFlow Lite Converter)
这会将 TensorFlow 模型转换为一种节省空间的特殊格式,以用于内存受限的设备,并且可以应用进一步减少并优化模型尺寸,使其在小型设备上运行更快。
TensorFlow Lite 解释器 (Tensorflow Lite Interpreter)
这会使用最有效的方式运行经过适当转换的 TensorFlow Lite 模型到给定设备的有效操作。
同样,我们不需要操作,但是需要了解 convert 的 python API,以及创建 FlatBuffer,当然,还包括量化,即浮点精度的转换问题。这一类的话题,在我以前关于 TensorFlow Lite 的许多线下分享中都有过详细的原理上的分析及解释。
整个转换代码如下:
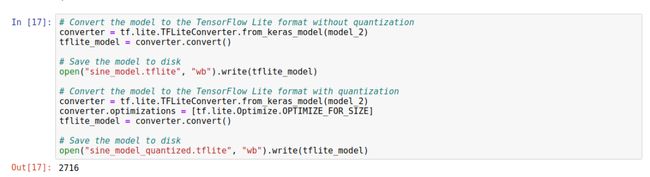
产生了两个模型,第一个模型是没有经过量化的。第二个模型是经过量化的。
对 TF Lite 模型进行预测,我们还需要完成如下的工作:
-
申明解释器对象实体
-
为模型分配内存
-
加载模型
-
从传感器中读取输出数据
由于这一段代码比较长,我们就看一下最终的分析结果:
我们再用代码来对比一下,量化和非量化模型的大小区别:

差距有20个字节。
10. 模型转换成二进制文件
准备模型以用于 TensorFlow Lite for Microcontrol 的最后一步。
到目前为止,在本章中,我们一直在使用 TensorFlow Lite 的 Python API。表示我们已经能够使用 Interpreter 构造函数加载模型磁盘中的文件。但是,大多数微控制器都没有文件系统,即使有,鉴于我们的限制,从磁盘加载模型所需的额外代码将很浪费空间。相反,作为一种优雅的解决方案,我们在 C 源文件中提供了该模型,包含在我们的二进制文件中并直接加载到内存中。
在文件中,模型定义为字节数组。幸运的是,有一个名为 xxd 的 Unix 工具,它能够将给定的文件转换为所需的格式。
以下输出为在我们的量化模型上运行 xxd,将输出写入名为sine_model_quantized.cc,并将其打印到屏幕上:
最终,生成二进制模型代码的工作搞定。
11. 结论
至此,我们完成了模型的构建。我们已经进行了训练,评估和配置建立了一个 TensorFlow 深度学习网络,该网络可以采用 0 到 2π 之间的数字并输出正弦的近似值。
这是我们使用 Keras 训练小模型的初次体验。在未来的项目中,我们将训练模型仍然很小,但是要复杂得多。
进一步学习,请密切关注后续第二集、第三集的发布。
如果你对本文中提到的一些知识点存在疑问,欢迎移步“问答”版块发帖提问!你的问题有机会得到CSDN 百大热门技术博主、资深社区作者或者 TensorFlow 资深开发者的解答哦!同时,我们也欢迎你积极地在这个版块里,回答其他小伙伴提出的问题,成为CSDN社区贡献者,迈出出道第一步!马上开始讨论吧!
想了解更多大神的经验分享?扫码关注TensorFlow官方微信公众号( TensorFlow_official ),产品更新、课程教学、技术实践、应用实例等精彩内容一网打尽!
