hadoop
Hadoop
一 hadoop
1.1 什么是hadoop
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
-
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
-
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
1.2 hadoop产生的背景
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.3 hadoop在大数据云计算中的位置
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4 hadoop生态圈
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
二 离线数据分析流程介
一个应用广泛的数据分析系统:“web日志数据挖掘”
3.1 需求分析
3.1.1 案例名称
“网站或APP点击流日志数据挖掘系统”[M1] 。
3.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
3.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
| 58.215.204.118 - - [18/Sep/2013:06:51:35 +000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1;rv:23.0) Gecko/20100101 Firefox/23.0" |
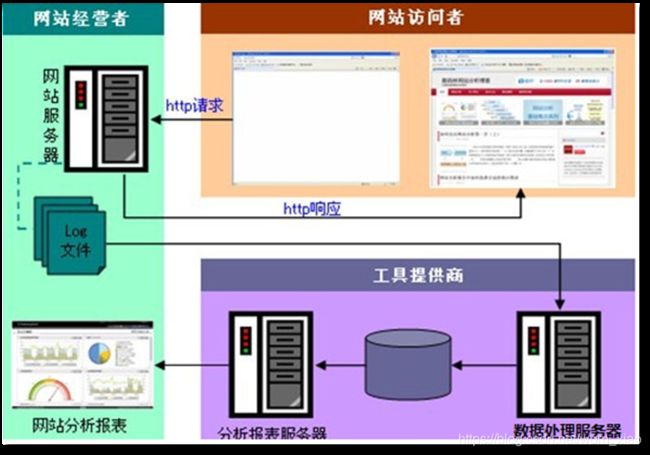
3.2 数据处理流程
3.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:

但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同。
- 数据采集:定制开发采集程序,或使用开源框架FLUME
- 数据预处理:定制开发mapreduce程序运行于hadoop集群
- 数据仓库技术:基于hadoop之上的Hive
- 数据导出:基于hadoop的sqoop数据导入导出工具
- 数据可视化:定制开发web程序或使用kettle等产品
- 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
3.2.2 项目技术架构图

3.2.3 项目相关截图
Mapreudce程序运行

- 在Hive中查询数据
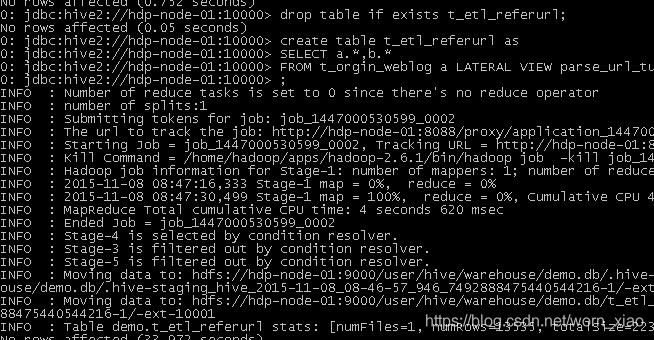
- 将统计结果导入mysql
| ./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
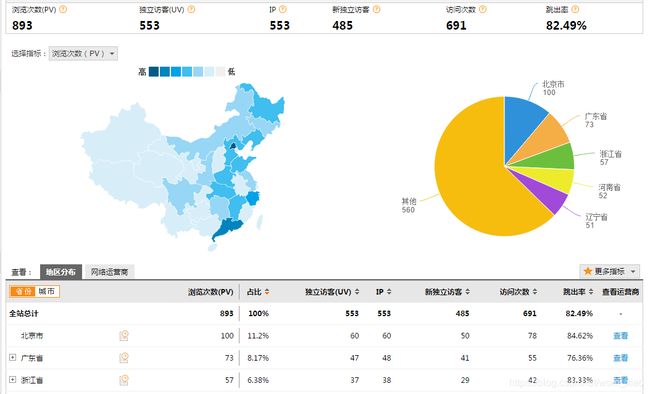
3.3 项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:
三 大数据架构
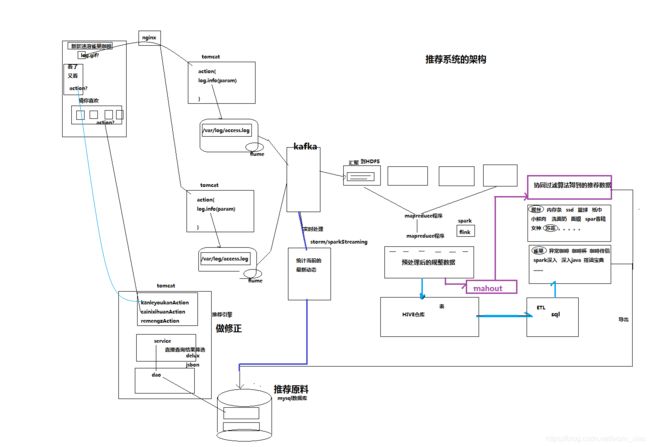
大数据架构流程
1 web或者是硬件系统,做数据采集或者流量采集
2进入kafka数据队列
3如果是事实计算则通过spark-stream/storm做实时计算
4 如果是离线计算,则把数据导入到分布式文件系统HDFS中
5 通过hadoop离线分布式计算平台(mahout机器学习),对hdfs进行数据处理
6 hadoop处理好的数据导入的hive数据库中
7 通过hive的sql 查询脚本,做ETL数据抽取
8 把实时计算或者经过数据抽取的数据通过sqoop导入到数据库
9 通过搭建web平台,对处理出来的数据做图形报表展示
四 搭建hadoop集群
4.1 安装hadoop2.4.1
先上传hadoop的安装包到服务器上去/home/hadoop/
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
4.2 配置hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_65
4.3 配置core-site.xml
4.4 配置hdfs-site.xml
4.5 配置mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
4.6 配置yarn-site.xml
4.7 将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/itcast/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
4.8 格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
4.9 配置免密登陆
(1)ssh-keygen //生成密钥
(2)ssh-copy-id host1 //登陆到主机1
(3)ssh-copy-id host2 //登陆到主机2
(4)ssh-copy-id host3 //登陆到主机3
4.10.0 启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
4.10.1 验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
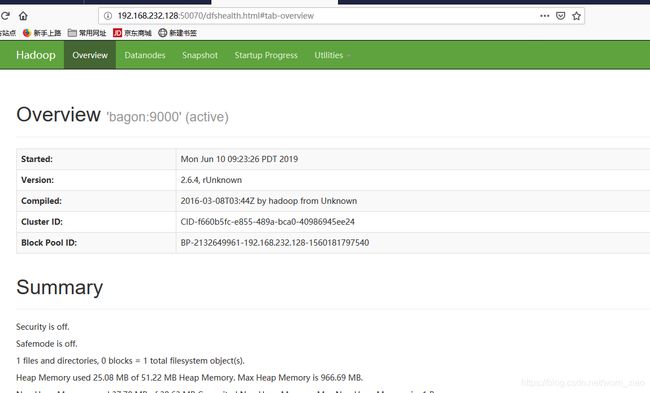
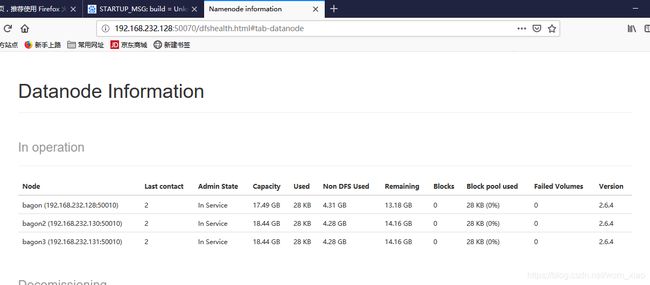
http://192.168.1.101:50070 (HDFS管理界面)
http://192.168.1.101:8088 (MR管理界面)
五 HDFS分布式文件系统
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
- HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
- HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
- 目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
- 文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
- HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
5.1 HDFS命令行客户端使用
HDFS提供shell命令行客户端,使用方法如下:
5.2 命令行客户端支持的命令参数
| [-appendToFile [-cat [-ignoreCrc] [-checksum [-chgrp [-R] GROUP PATH...] [-chmod [-R] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-copyToLocal [-p] [-ignoreCrc] [-crc] [-count [-q] [-cp [-f] [-p] [-createSnapshot [-deleteSnapshot [-df [-h] [ [-du [-s] [-h] [-expunge] [-get [-p] [-ignoreCrc] [-crc] [-getfacl [-R] [-getmerge [-nl] [-help [cmd ...]] [-ls [-d] [-h] [-R] [ [-mkdir [-p] [-moveFromLocal [-moveToLocal [-mv [-put [-f] [-p] [-renameSnapshot [-rm [-f] [-r|-R] [-skipTrash] [-rmdir [--ignore-fail-on-non-empty] [-setfacl [-R] [{-b|-k} {-m|-x [-setrep [-R] [-w] [-stat [format] [-tail [-f] [-test -[defsz] [-text [-ignoreCrc] [-touchz [-usage [cmd ...]] |
5.2 常用命令参数介绍
| -help 功能:输出这个命令参数手册 |
| -ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果 |
| -mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd |
| -moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd -moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt |
| --appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt
|
| -cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt
-tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1 -text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1 |
| -chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
| -copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ -copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz |
| -cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv 功能:在hdfs目录中移动文件 示例: hadoop fs -mv /aaa/jdk.tar.gz / |
| -get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz -getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum |
| -put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
|
| -rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/
-rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc |
| -df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h /
-du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/*
|
| -count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/
|
| -setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz <这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量>
|
六 HDFS的工作原理
6.1 namenode&datanode
- HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
- NameNode负责管理整个文件系统的元数据
- DataNode 负责管理用户的文件数据块
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行

如图所示是hdfs的工作原理,首先客户端先把文件进行切块,然后客户端向namenode询问是否可以上传,如果可以,namenode将高诉客户端可以上传的节点。客户端再向datanode发起管道连接,最后客户端以packege的方式同步数据到各个datanode节点。
6.2 namenode&secondname
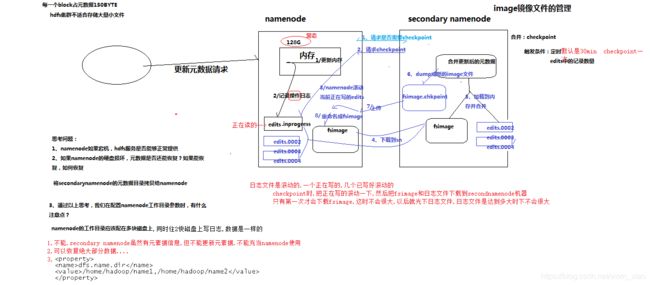
如上图是namenode与secondnamenode的元数据管理机制。如图可以看出namenode的元数据备份是通过secondnamenode进行及时回显来调用的,也就是edit文件被secondnamenode及时下载以后,与原有的文件进行合并,并且备份到namenode节点上。
七 mapReduce
- mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
- shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
- 具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
7.1 Shuffle缓存流程
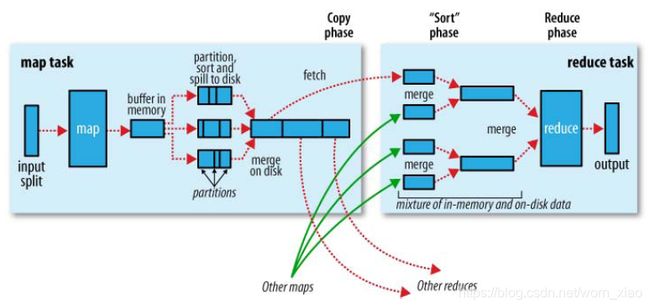
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
- 分区partition
- Sort根据key排序
- Combiner进行局部value的合并
7.2 mapReduce详解
- maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
- 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
- reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
- reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
- 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
具体来说,比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析,是最适合不过的了。