论文阅读:node2vec: Scalable Feature Learning for Networks
node2vec: Scalable Feature Learning for Networks
摘要
基于网络中节点和边的预测任务中的特征工程总是很麻烦的。虽然表示学习的自动学习特征已经有很大的帮助,但现有的特征学习方式无法对网络中连接模式的多样性进行足够的捕捉。
node2vec是本论文提出的一种对网络中的节点学习连续特征表达的框架。通过将节点映射到maximizes the likelihood of preserving network neighborhoods of nodes的低维特征空间。
1.Intro
许多问题都需要对网络节点和边的预测。比如
* 社交网络中,预测用户的兴趣;或者在蛋白质网络中预测蛋白质的功能
* 预测两节点间是否有边相连,在基因工程中预测基因间的连接或社交网络中识别二人是否是朋友。
一般处理这种问题需要手工提特征,但是需要domain knowledge和人工,而且没有泛化性。
另一种方式是通过解一个优化问题学习一个特征表示(如word2vec)。挑战是怎么设目标函数,需要权衡计算复杂度和预测准确率。
现阶段方式缺少一种能学习可控长度特征的合理的目标函数。传统的PCA,多维缩放等降维方法通过maximize转特征空间后数据的方差,缺点是需要特征值分解,而且得到的样本表示在多种预测任务上的效果还不好。
所以定义一个目标函数来保存节点的局部邻居结构是一种方法。本论文的目标是提出一个灵活的学习节点表示的算法,既能将属于相同的社区的节点学习得到相近的嵌入;又能对有相似功能的节点(如在社区中的连接结构相似)学得相似的嵌入。
本文借鉴word2vec提出了node2vec,通过maximize the likelihood of preserving network neighborhoods of nodes in a d-dimensional feature space得到特征表示。利用二阶随机游走产生节点社区。
很明显,如何定义社区是关键。本文通过定义一系列的(biased)随机游走,探索一个节点的不同社区。这样算法是灵活的,同时参数不是固定的,而且比较好理解并能直到随机游走得到不同的探索网络方式。同时参数可以通过半监督学习得到。(Q:怎么样的随机游走,怎么半监督学习得到参数)
介绍一下论文实验场景:
1. multi-label classif i cation task, where every node is assigned one or more class labels
2. link prediction task, where we predict the existence of an edge given a pair of nodes.
实验结果:outperform SOTA by 10-20%,易并行。
2. 介绍相关工作
其实从这个框架命名上就可以看出,node2vec是借鉴了word2vec的。基本的idea相似,提取连续的特征表示,一个是从网络提取,一个是从document中提取。
正好之前读过word2vec的论文,附上笔记链接,其中的skip-gram是主要思路来源。相似的词总是出现在相近的位置,网络中相似的节点也有这种特点。
类比:网络就像一个document。document是有序的词序列,通过对一系列节点进行采样将网络序列化。不同的采样方法得到不同的特征表示。实验表明,没有一个特定的采样策略能对所有网络或者任务都适用。这一缺点论文通过设计目标函数可以借鉴。
3.node2vec
设定目标函数
其中
V V 是网络中节点的集合, f f 将节点映射到特征空间,可以理解为一个 Embedding E m b e d d i n g , S S 指得到节点邻居 N N 的策略.
这个优化问题要做的就是maximizes the log-probability of observing a network neighborhood NS(u) N S ( u ) for a node u u conditioned on its feature representation, given by f f .
这个目标函数和skip-gram如出一辙,用softmax算概率,negative sampling加速。
和skip-gram只用选择window size不同,node2vec需要考虑不同方式对节点采样得到其邻居。
Search strategies
为方便讨论,限制邻居集大小k=3,考虑两种极致:
* BFS 宽搜,如图中红色箭头,u的邻居包括 s1,s2,s3 s 1 , s 2 , s 3
* DFS 深搜,蓝色箭头,邻居 s4,s5,s6 s 4 , s 5 , s 6
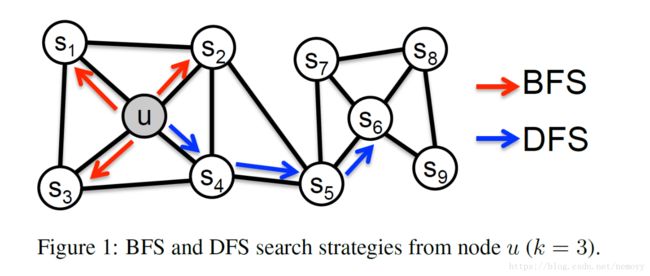
对网络节点的预测也要考虑两种相似性,homophily 和 structural equivalence。homophily,同质性,属于同一社区,相连比较紧密的节点应该有相似的嵌入,比如图中的u和 s1 s 1 ; structural equivalence同构,结构相似的节点应该有相似的嵌入,如u和 s6 s 6 。
特别的,同构的节点不强调连接线。有的节点距离很远但是在网络中结构相同。网络通常显示两种特点因为其中有表现同质性的节点也有表现同构的节点。
观察到,宽搜能捕捉同构性节点,深搜能捕捉同质性节点。
node2vec
a flexible biased random walk procedure that can explore neighborhoods in a BFS as well as DFS fashion
Random Walks
给源节点 u u ,模拟一个长为 l l 的随机游走。设 ci c i 为游走的第 i i 个节点,起始节点 c0=u c 0 = u 。节点 ci c i 服从一下分布:
其中 πvx π v x 是没有标准化的节点v到x的转移概率,Z用于标准化。
Search Bias α α
直接设转移概率为边的权重 πvx=wvx π v x = w v x 不能有效考虑网络结构和搜索不同的邻居空间,所以本论文是这样设置bias的.
该随机游走有两个参数p和q。考虑刚刚遍历了边 (t,v) ( t , v ) ,现在在节点v要根据转移概率 πvx π v x 觉得下一个节点x。设 πvx=αpq(t,x)⋅wvx π v x = α p q ( t , x ) ⋅ w v x ,其中
dtx d t x 表示节点t和x间最短距离( 注意是t到x的距离,不是v到x的距离),只能属于 { 0,1,2} { 0 , 1 , 2 } 。参数 p p 和 q q 相当于调节BFS和DFS的程度。
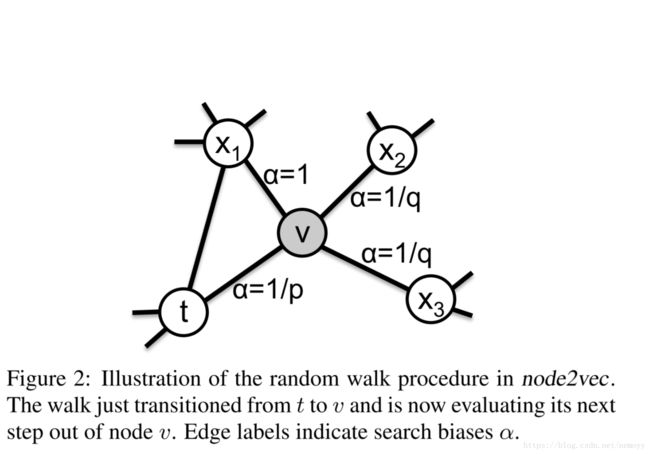
p p 称为Return parameter,决定再访问节点的可能性。若 p p 值调高 ()>max(q,1)) ( ) > m a x ( q , 1 ) ) ,可以保证在两步内采样已访问过的节点的可能性比较低;若 p p 调低 (<min(q,1)) ( < m i n ( q , 1 ) ) ,会使得游走变得比较拘于局部。
q q 称为In-out parameter, q>1 q > 1 游走会选择里t近的节点,以此达到接近BFS的效果; q<1 q < 1 游走会选择离t更远的节点,达到类似DFS的效果。
随机游走的优点:时间复杂度和空间复杂度优于DFS/BFS.
The node2vec algorithm

伪代码比较好懂,转移概率矩阵可以提前算好,对图中的每个节点,进行r次随机游走得到r个长为l的walk。可以理解成每个给每个节点造句,r个l长的句子,全部节点的游走合起来就得到了这个网络的语料库,经过类似skip-gram的训练可得节点的Embedding.
4.实验
本论文实验部分做的非常详尽。有节点分类和边预测两个任务,各在3各数据集上做实验,同时和谱聚类,DeepWalk,LINE3种算法做严格的对比实验。还对node2vec做了敏感度分析,抗干扰分析,以及scalability.
实验部分值得学习的地方在于他们实验真的做的很全面,在和其他算法对比的时候,控制变量做的很严谨,尽量使各算法在同一起跑线,做到比较公正。其次是对参数p和q的调试也做到了比较完整的探讨。所以能得到node2vec全面优于被比较的算法也是比较可信的。
5.总结与收获
算法对比实验中,除了谱聚类,其他的算法都使用了Embedding这种连续的特征表示,而且实验结果一致的好于谱聚类。这说明Embedding这种方式如在nlp中一样,对网络相关的任务也带来了好处。
和nlp的语料库不同的是,网络中每个节点的邻居集如何选择会很大程度的影响Embedding的效果。本论文的创新之处就在于提出了一种灵活的选择节点邻居的方法,并通过实验证明比其他的方法更有效。
另外有一个地方值得注意,link prediction中,在判断两节点是否有边相连的时候,论文讨论了如何结合两节点的特征人(如下表)。实验中Hadamard操作符(i.e., element-wise multiply)在node2vec上表现最好。为什么会出现这种情况是值得深入研究的.

连续特征表示是一个非常底层的技术,就如word embedding相当于nlp的基石,在上面可以有各种应用,如机器翻译,阅读理解等等。node2vec也是相当于在各种网络问题上面加一层特征转化,以方便之后的各种任务。