口袋妖怪数据集探索
数据集下载
!wget -O pokemon_data.csv https://pai-public-data.oss-cn-beijing.aliyuncs.com/pokemon/pokemon.csv
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("./pokemon_data.csv")
df.head()
查看数据

percent_missing = df.isnull().sum() * 100 / len(df)
missing_value_df = pd.DataFrame({
'column_name': df.columns,
'percent_missing': percent_missing
})
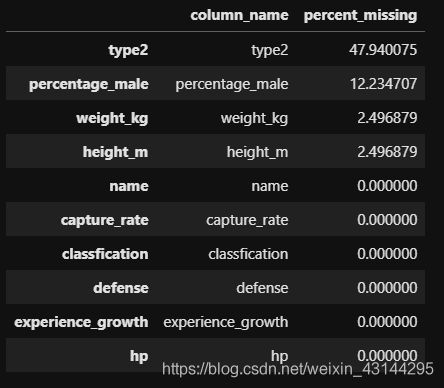
missing_value_df.sort_values(by='percent_missing', ascending=False).head(10)
percent_missing = df.isnull().sum() * 100 / len(df)
missing_value_df = pd.DataFrame({
'column_name': df.columns,
'percent_missing': percent_missing
})
missing_value_df.sort_values(by='percent_missing', ascending=False).head(10)
查看各代口袋妖怪的数量
df['generation'].value_counts().sort_values(ascending=False).plot.bar()

df['type1'].value_counts().sort_values(ascending=True).plot.barh()

plt.subplots(figsize=(20,15))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = df.corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)

interested = ['hp','attack','defense','sp_attack','sp_defense','speed']
sns.pairplot(df[interested])

plt.subplots(figsize=(10,8))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = df[interested].corr()
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values,
annot=True, fmt="f",cmap="YlGnBu")

for c in interested:
df[c] = df[c].astype(float)
df = df.assign(total_stats = df[interested].sum(axis=1))
df[df.total_stats >= 525].shape
total_stats = df.total_stats
plt.hist(total_stats,bins=35)
plt.xlabel('total_stats')
plt.ylabel('Frequency')
