redis缓存穿透穿透解决方案-布隆过滤器
我们先来看一段代码
cache_key = "id:1"
cache_value = GetValueFromRedis(cache_key); //判断缓存是否有数据
if cache_value != nil{ //如果有 直接返回数据
return cache_value
}
db_value = GetValueFromDb(cache_key) // 从数据库中查询数据
if db_value == nil{
return db_value
}
expire_time = 300
SetRedisValue(cache_key, db_value, expire_time) //将数据库的结果更新到缓存中,并直接返回结果
return db_value相信绝大多数同学都是这么处理请求的,这样用redis能够给mysql抵挡住大部分的请求。其实这样是存在一定的问题的
问题1
我在请求的时候,用id=-1来请求
id=-1这条记录在数据库中是不存在的,当然对应的redis中也是没有的。那么就需要去请求数据库然后把数据写入到redis中,这样就会造成没有必要的数据库请求,一两个请求无所谓,但是如果从-∞到-1 无限的高频率的请求,就会给线上造成很大的压力。
针对问题1的解决方案
我们可以通过程序来限制id的合法性,判断id<1的情况都直接在接口层面拦截,这个方式的确可以解决上面说的那种情况,但是咱们接下来往下看
问题2
比如现在数据库id的最大值为1000,我们用比1000大的数字去请求
这种情况原理和问题1是一样的,这次我们就没法通过参数判断来拦截住请求了,所以我们就得用接下来一种经典的方式,布隆过滤器
布隆过滤器其实就是一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在。从而达到对脏数据过滤的效果。他存在的位置如图
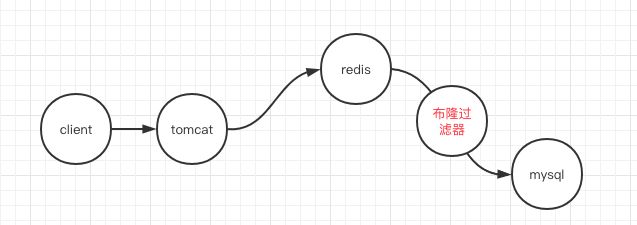
其实对布隆过滤器比较陌生的同学可以先想想,作为一个过滤器需要满足什么条件?
- 速度得快,得从内存查,如果从硬盘查的话还不如直接查数据库
- 因为过滤器里面得存入数据库所有的数据,所以内存势必是比较紧张的,所以内存要做到绝对的节省,说到节省内存,大家应该很容易能想到 redis里面的setbit操作
布隆过滤器的实现
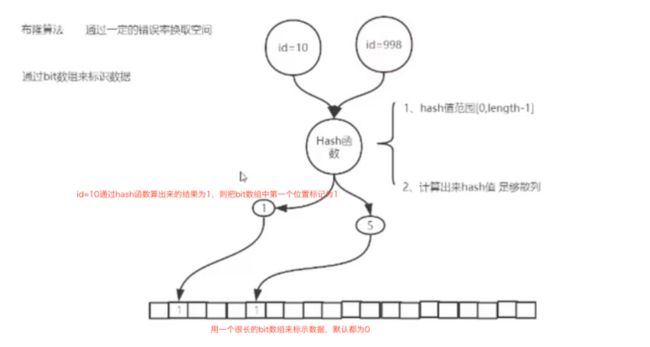
写入过程
- 通过bit数组来标识数据
- 比如id=10的数据,通过hash算法算出来结果为1
- 把bit数组下表为1的位置的值标记为1
查询过程
- 将id=10做hash运算,得到结果1
- 看bit数组下表为1的数据标识为1,则说明数据存在
其实我们看上面的算法是存在一定的问题的
1:只要是hash运算,就会存在hash碰撞问题,比如id=10 和id=100可能经过hash运算之后结果都为1,那么id=10写入之后查询id=100是否存在会误判为id=100也存在
2:当bit数组满了之后,查询的错误率肯定是百分之百,因为每个数据都存在
这些其实都是导致错误率的原因,错误率是不可能避免的,但是咱们可以减少错误率,减少错误率的方法有两个
1:加大bit数组的长度,对于bit数组的长度的增加是不用担心的,因为是bit操作,所以可以加到很大的值
2:增加hash函数的个数,hash函数的个数增加了,说明标识一个数组需要的位置就会变多。这样会降低发生hash碰撞的概率。但是hash的函数也不是越多越好,需要参照数组的长度来定
hash错误率:
布隆算法说数据存在,那么实际有可能不存在
如果数据不存在。那么一定不存在
布隆过滤器redis中的使用方法
1.下载redisbloom插件(redis官网下载即可)
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz2:解压并安装,生成.so文件
[root@redis]# tar -zxvf v1.1.1.tar.gz
[root@redis]# cd Redisbloom-1.1.1/
[[email protected]]# make
[[email protected]]# ls
contrib Dockerfile docs LICENSE Makefile mkdocs.yml ramp.yml README.md rebloom.so src tests3:在redis配置文件(redis.conf)中加入该模块即可
[root@redis]# vim redis.conf
#####################MODULES################# # Load modules at startup. If the server is not able to load modules
# it will abort. It is possible to use multiple loadmodule directives.
loadmodule /usr/local/redis/redisbloom-1.1.1/rebloom.so4:重新启动redis
redis-server ./redis.conf5:测试安装是否成功
127.0.0.1:6379> bf.add users user2 //写入数据user2
(integer) 1
127.0.0.1:6379> bf.add users user1 //写入数据user1
(integer) 1
127.0.0.1:6379> bf.exists users user1 //查询user1存在
(integer) 1
127.0.0.1:6379> bf.exists users user3 //查询user3不存在
(integer) 0上面说过布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate :允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size :布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve users 0.01 100
三个参数的含义:
第一个值是过滤器的名字。
第二个值为 error_rate 的值。
第三个值为 initial_size 的值。
关注我的技术公众号,每周都有优质技术文章推送。
微信扫一扫下方二维码即可关注:
