文本匹配之bert flow:On the Sentence Embeddings from Pre-trained Language Models
目录
- 论文信息
- 内容解析
-
- 语义相似度和bert预训练
-
- 语言模型LM(Language modeling):
-
- 掩码语言模型MLM(masked language modeling)
- 统计共现来表示语义相似
- 各向异性向量与语义相似性
- BERT-flow
-
-
- 动机Motivation
- 基于标准化流的生成模型Flow-based Generative Model
-
- 实验
-
- 语义相似Semantic Textual Similarity
- 无监督实验Unsupervised Training
- 有监督实验Supervised Training
- 无监督QA实验Unsupervised Question-Answer Entailment
- 对比其他词嵌入基准Comparison with Other Embedding Calibration Baselines
- 语义相似度与编辑距离关系Semantic Similarity Versus Lexical Similarity
- 总结
- 参考文献
论文信息
论文名:On the Sentence Embeddings from Pre-trained Language Models:
机构:字节跳动AI Lab、CMU
下载:https://arxiv.org/abs/2011.05864
代码:https://github.com/bohanli/BERT-flow
内容解析
将一个句子编码成固定维度的向量,惯例做法为:要么取bert的上下文context的每个token编码的平均(效果好于后者,本文使用这种),要么直接使用CLS token的编码。需要注意的是真正生成一个句向量时,这个句子是没有masked,这和预训练对句子masked不一样。Reimers and Gurevych的论文证明bert在语义相似度上对句子的编码效果还不如Glove。但我们不知道为什么?下面将具体分析其原因。
语义相似度和bert预训练
语言模型LM(Language modeling):
![]()
其中:
- x1:T = (x1, . . . , xT )表示tokens序列
- t为token的序号,最大值为token长度T
- ct= x1:t−1
解释:传统语言模型采用自回归方式来因式分解token 1到T出现的联合概率p(x1:T ) 。例如句子x1x2x3出现的概率为p(x1) * p(x2|x1) * p(x3|x1x2),这就是最原始的语言模型建模,可以利用马尔科夫链的无后效性假设,简化为n-gram模型。
掩码语言模型MLM(masked language modeling)
![]()
其中:
- maske意思是将句子序列中的某些token,直接用[mask]这个token替换,如,x1x2x3 maked后为x1[mask]x3
- x^为带有被masked token的序列
- x- 为被masked的token
- mt 为该token是否被masked,如果是其值为1,否则为0
- ct为上下文序列,这里为x^
解释: 输入带掩码的序列,预测掩码出现的概率,即找出被masked的token是什么,这个叫自编码语言模型。和LM不同的是,LM为输入完整序列,预测该单词的下一个单词是什么,这个叫自回归语言模型。
这两个模型都是基于给定上下文序列c,预测token x的概率,即条件概率。可以表示为:
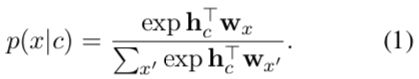
其中:
- c为上下文token序列
- x为待预测的token
- hc为将c编码成向量的函数,多为深度神经网络
- wx为编码x的函数,如词嵌入词表embedding lookup table
两个句子经过bert编码成向量hc和hc’后,他们之间的相似度可以直接计算两个向量的乘积hTchc’。因为这两个向量归一化到同一个超球体空间后,他们的乘积类似cos距离。
但如(1)式,bert预训练时并没有加入hTchc’这个计算。所以我们很难知道hTchc’计算到底代表了什么。
统计共现来表示语义相似
我们不再直接计算hTchc’,而是考虑计算hTc wx
即上下文编码和单词词嵌入的点积。该计算可以近似为:
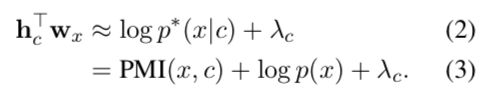
其中:
 为x和c的点式互信息,PMI是共现(Co-Occurrence)关系的一种近似度量,实际上,"语义"这个概念的数学表达对应的就是某种能够反映共现关系的统计量,因此计算词嵌入和上下文嵌入的点积是能够反映词和上下文的语义相关性的。
为x和c的点式互信息,PMI是共现(Co-Occurrence)关系的一种近似度量,实际上,"语义"这个概念的数学表达对应的就是某种能够反映共现关系的统计量,因此计算词嵌入和上下文嵌入的点积是能够反映词和上下文的语义相关性的。- p(x)为单词概率,是固定值。 λ c \lambda _{c} λc为c的固定参数。
再进一步,我们可以猜想如果两个上下文c和c’与同一个词w有共现关系,那么c和c’也应该有相似的语义,具体来说,在训练语言模型时,c和c’的共现会使得c和w相互靠近,对c’来说也同样如此,因此hc和hc’就会变得接近,同时由于softmax标准化的原因,hc和xw’的距离会拉大,w’!=w。通过这样的过程,模型可以建立上下文与上下文潜在的共现关系,这表明BERT的训练过程和语义相似度计算的目标是很接近的,训练得到的句向量应该包含了文本之间的语义相似度信息。
因此我们继续考虑下面的问题:「我们使用BERT句向量的方法是否不够有效?」
各向异性向量与语义相似性
由于我们用的相似度度量都是很简单的度量,比如cosine相似度,minkowski距离等,这些度量对语义分布的性质可能会有一定的要求,而BERT句向量的分布不一定满足这些性质,或者说「BERT句向量隐含的语义相似度信息没那么容易被抽取出来」,因此我们尝试分析一下句向量在高维空间中的分布情况。
目前已经出现了不少针对语义向量空间性质的研究,比如Representation Degeneration Problem in Training Natural Language Generation Models (ICLR 2019)[6]发现语言模型学习到的词向量分布通常是各向异性的(anisotropic),且词嵌入常呈现锥形分布,Towards Understanding Linear Word Analogies (ACL 2019)[7]在BERT和GPT2的词向量分布上也得到了同样的结论。因此作者猜想BERT句向量同样存在这样的问题,作者在上述结论的基础上,进一步发现了词向量的非均匀分布和词频的非均匀分布有关。
为了方便,我们只探讨词向量空间,因为词向量空间和句向量空间共享的是同一个高维空间,如果词向量空间有什么问题,那句向量空间也会有同样的问题。
为了验证BERT词向量分布是否和词频有关,作者计算了词向量的L2范数和词向量间的L2距离,如下表所示。
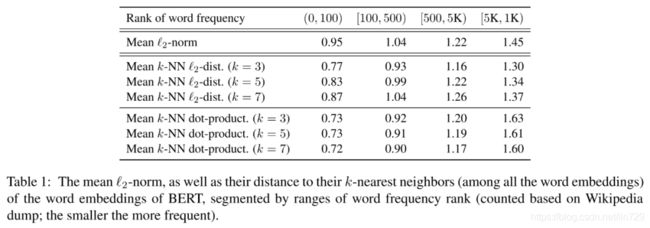
我们可以发现高频词的L2范数更小,说明高频词离原点更近,低频词离原点较远,这会导致即使一个高频词和一个低频词的语义是等价的,但词频的差异也会带来很大的距离偏差,从而词向量的距离就不能很好地代表语义相关性。
我们还可以发现高频词与高频词之间的 L2 距离也更小,说明高频词分布得更紧凑,低频词分布得更稀疏,而稀疏性会导致一些词向量之间的空间是"空"的,这些地方没有明显的语义对应,因为句向量是词向量的平均池化,是一种保凸性运算,然而这些没有语义定义的空间使得分布不是凸性的,所以可以认为BERT句向量空间在一定程度上是「语义不平滑的(semantically non-smoothing)」,这导致句向量相似度不一定能够准确表示句子的语义相似度。
BERT-flow
为了解决BERT句向量分布不平整的问题,作者认为可以利用标准化流(Normalizing Flows)将BERT句向量分布变换成一个光滑的,各向同性的标准高斯分布。
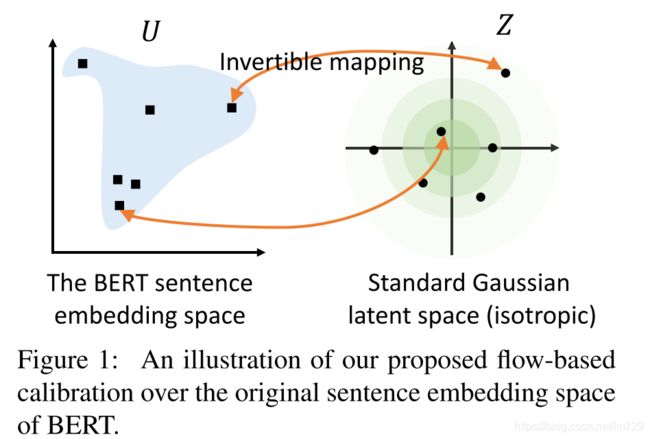
动机Motivation
标准高斯分布有一些很好的性质,首先,标准高斯分布是各向同性的(isotropy),在传统的词嵌入方法中,研究表明词向量矩阵的前面几个奇异值通常和高频词高度相关,通过将嵌入分布变换到各向同性的分布上,奇异值就可以被压缩。另外,标准高斯分布是凸的,或者说是没有"空洞",因此语义分布更为光滑。
基于标准化流的生成模型Flow-based Generative Model
基于标准化流的生成模型定义了一个从潜在空间 z观测空间 u 的可逆变换 ,标准化流的生成过程为:
![]()
pz(z)为先验分布,z->u是可逆变换。
通过变量代换定理,可观测变量 x 的probabilistic density function PDF可以表示为:

在BERT-flow中:
- pz是标准高斯分布
- u是BERT句向量分布
- f ϕ f_{\phi } fϕ 是一个可逆神经网络
- det为矩阵的行列式
注意flow的训练是无监督的,且BERT的参数不参与训练,只有标准化流的参数被优化,训练目标为最大化预先计算好的BERT句向量的似然函数:
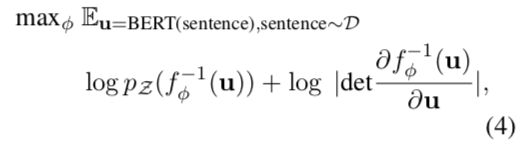
其中:
- D为数据集,即句子集合
作者借鉴并简化了Glow模型的设计,将Glow的仿射耦合变换替换为了加性耦合变换,将 1x1卷积替换为了随机置换。最后我们学习到了一个双射 f ϕ − 1 f_{\phi }^{-1} fϕ−1,它可以无损地将BERT句向量 u变换为潜在的高斯表示z ,而且不丢失语义信息,这是由 f ϕ f_{\phi } fϕ的可逆性保证的。
实验
为了验证BERT-flow的有效性,作者以SBERT的实验结果为基础,在一系列文本语义相似度计算任务上进行了模型对比和评估。
语义相似Semantic Textual Similarity
作者利用SentEval Toolkit在STS-B,SICK-R,STS tasks 2012-2016的测试集上进行模型评估。与SBERT的评估过程一致,作者首先使用句子编码器得到句向量,然后计算句向量对的cosine相似度作为语义相似度的预测值,最后计算预测相似度和人工标注相似度的Spearman秩相关系数。
无监督实验Unsupervised Training
由于标准化流的训练过程是完全无监督的,所以作者在整个目标数据集上(train+val+test)训练了标准化流(flow(target)),为了与SBERT对比,作者也用SNLI和MNLI数据集(统称为NLI)无监督地训练标准化流(flow(NLI*)),注意在整个训练过程中预训练BERT部分的参数是不变的,实验结果如下表所示。

可以发现,在目标数据集上训练flow(BERT-flow(target))比在NLI数据集上训练flow(BERT-flow(NLI*))要好不少,除了SICK-R数据集,这是因为SICK-R数据集包含了文本蕴含和文本相关两类任务,而NLI数据集正好包含了文本蕴含任务,因此SICK-R和NLI数据集的差异可能很小,又因为NLI数据集比SICK-R大得多,所以这样的结果是可以理解的。但在实际应用场景下,在目标数据集上训练模型通常是更好的选择。
有监督实验Supervised Training
当前文本语义相似度计算的SOTA基线模型依旧是SBERT,SBERT同样是在NLI数据集上以有监督的方式训练的,为了和SBERT对比,作者首先以SBERT的训练方式在相同的数据集上微调了BERT部分(BERT-NLI),然后再无监督地微调flow部分。「这实际上等价于在SBERT后面加了个flow,区别在于BERT-flow利用了目标数据集来无监督训练flow,而SBERT并没有以任何方式利用目标数据集」,所以BERT-flow好也是好得理所当然的。实验结果如下表所示,可以认为BERT-flow是一个新的SOTA模型。

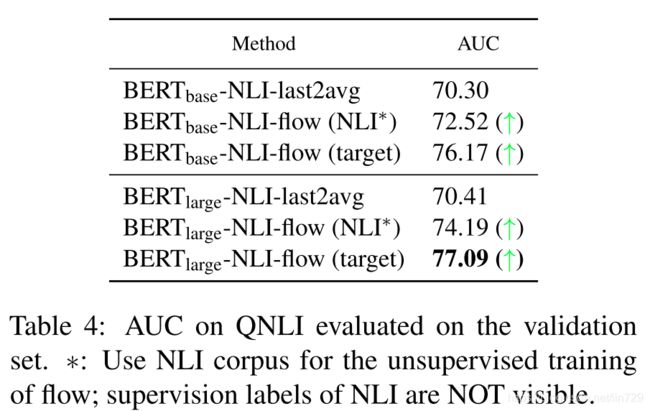
无监督QA实验Unsupervised Question-Answer Entailment
上面的文本语义相似度计算任务是回归式的,而文本语义匹配任务是二分类式的,比如判断某个答案是否能够回答某个问题。因此作者在问答蕴含(QA entailment)任务上进一步测试了BERT-flow。作者在QNLI数据集上进行实验,并计算出了不同模型在验证集上的AUC,实验结果表明flow的引入能够较大幅度地提高模型表现。
对比其他词嵌入基准Comparison with Other Embedding Calibration Baselines
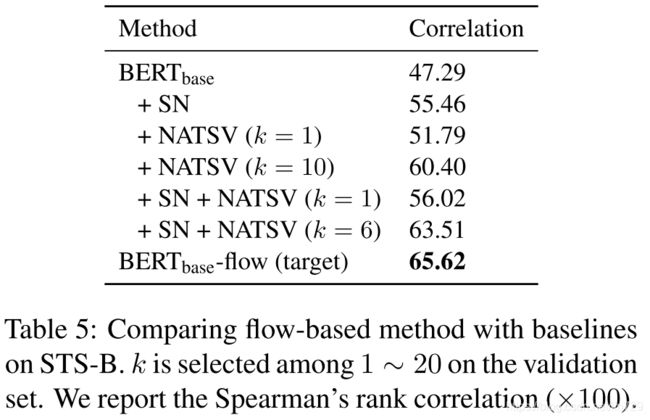
针对句向量空间分布不规整的问题,前人也提出了一些修正方法,比如对句向量做标准化(SN): u − μ δ \frac{u-\mu }{\delta } δu−μ,以及归零前 k 个奇异向量来规避各向异性的问题(NATSV)。下面的实验结果表明作者的flow是最先进的方法,虽然NATSV可以缓解各向异性的问题,但粗暴地丢弃前 k 个奇异向量会导致语义信息的部分丢失,而flow的操作是无损的。
语义相似度与编辑距离关系Semantic Similarity Versus Lexical Similarity
作者进一步讨论了文本的语义相似度和词汇相似度(Lexical Similarity)的关系,作者将编辑距离(edit distance)作为文本词汇相似度的度量,然后分别计算了人类标注的语义相似度、BERT语义相似度、BERT-flow语义相似度和词汇相似度的Spearman相关系数 ρ \rho ρ。
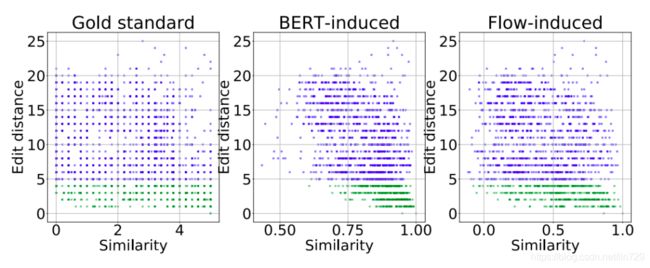
我们可以发现真实的语义相似度和词汇相似度的相关性很弱(),因为我们知道一个词的变动就可能使得文本的语义完全相反(比如加入一个否定词),而BERT计算的语义相似度和词汇相似度表现出了较强的相关性(),尤其是当编辑距离小于4的时候(green)相关性非常强,这会导致BERT可能难以区分like和dislike的语义差别。而引入flow之后,可以发现上述情况有明显的改善,尤其是当编辑距离小于4的时候改善更明显,「这表明BERT-flow计算的相似度更接近于真实的语义相似度,而不是词汇相似度。」
总结
标准化流用于规整分布的思想挺有价值的,VAE和标准化流的结合就非常多,比如在CV里面,Variational Autoencoders with Normalizing Flow Decoders (2020)[8]就把Glow和VAE结合起来同时解决Glow难以训练和VAE生成图像偏模糊的问题。因此如何在其他模型里面有效地利用标准化流的优秀性质也是值得一灌的方向。
tips:flow model建议看李宏毅老师视频
参考文献
[1] On the Sentence Embeddings from Pre-trained Language Models
[2] https://mp.weixin.qq.com/s/_bVG_9zJhFgD1GB_rcB8IA