爬取前程无忧存入数据库进行数据分析和可视化绘制词云图
爬取前程无忧网站
爬虫基本思路
获取数据在网页的位置----编写防爬-----启动数据库保存数据
本次教程使用的是mongodb数据库(MySQL)原理差不多,自己百度吧
ps:本次测试日期是2020/7/4 后面因为网站更新防爬措施无法实现功能本教程不背锅!
1、具体要求:职位名称、薪资水平、招聘单位、工作地点、工作经验、学历要求、工作内容(岗位职责)、任职要求(技能要求)。
spider文件代码
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import QianchengwuyouItem
class WuyouSpider(scrapy.Spider):
name = 'wuyou'
allowed_domains = ['jobs.51job.com']
start_urls = ['http://jobs.51job.com/']
def parse_details(selfm, response):
# 获取详情页面数据
print("=" * 100)
print(response.url)
item = QianchengwuyouItem()
# 职位名称
item["Job_title"] = response.xpath("//div[@class='cn']/h1/text()").extract_first()
# 薪资水平
item["Pay_level"] = response.xpath("//div[@class='cn']/strong/text()").extract_first()
# 招聘单位
item["Recruitment_unit"] = response.xpath("//div[@class='cn']//a[1]/text()").extract_first()
# 工作地点 + 工作经验 + 学历要求....都在//div[@class='cn']/p[2]中
item["Workplace"] = response.xpath("//div[@class='cn']/p[2]/text()[1]").get().replace('\xa0','')
# 工作经验 + 学历要求
all = response.xpath("//div[@class='cn']/p[2]/text()[2]").get().replace('\xa0','')
# 判断工作经验是否存在
if len(all) >= 4:
item["hands_background"] = all
item["Education_requirements"] = response.xpath("//div[@class='cn']/p[2]/text()[3]").get().replace('\xa0','')
if len(item["Education_requirements"]) != 2:
item["Education_requirements"] = None
elif len(all) < 4:
item["hands_background"] = None
item["Education_requirements"] = all
if len(item["Education_requirements"]) != 2:
item["Education_requirements"] = None
# .get().replace('\xa0','')
# item["Workplace"] = item["Workplace"].get(1)
# # 学历要求
# item["Education_requirements"] = response.xpath("//div[@class='cn']/p[2]/text()[3]").get().replace('\xa0','')
# 职位信息包含(工作内容+任职要求+工作经验+学历要求)
item["Career_information"] = response.xpath("//div[@class='bmsg job_msg inbox']/p/text()").extract()
item["Career_information"] = [i.strip() for i in item["Career_information"]]
item["Career_information"] = [i for i in item["Career_information"] if len(i) > 0]
item["Career_information"] = " ".join(item["Career_information"]).replace("\xa0","").replace(",",",")
if (item["Pay_level"]) is None:
item["Pay_level"] = "无"
# 关键字:keyword
item["keyword"] = response.xpath("//div[@class='mt10']//p//a/text()").extract()
yield item
def industry_perse(self, response):
# # 获取该行业下所有职业链接
# all_list = response.xpath("//div[@class='detlist gbox']")
# # 获取全部招聘职位下的所有职业(occupation)链接
# for a in all_list:
# occupation_url = a.xpath(".//span/a/@href").extract_first()
# yield scrapy.Request(
# occupation_url,
# callback=self.parse_details
# )
# 获取当前页面所有职业所在的div
all_list = response.xpath("//div[@class='detlist gbox']//div")
# 计算当前页面获取多少url
url_num = 0
# 遍历获取大数据行业下的所有职业(occupation)链接
for a in all_list:
occupation_url = a.xpath("./p/span/a/@href").extract_first()
yield scrapy.Request(
occupation_url,
callback=self.parse_details
)
url_num += 1
# 翻页
print("当前已爬取{}个职业".format(url_num))
next_url = response.xpath("//div[@class='p_in']/ul//li/a[text()='下一页']/@href").extract_first()
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.industry_perse
)
def parse(self, response):
# 获取全部招聘职位的链接
dashujukaifa_list = response.xpath("//div[@class='maincenter']/div[2]/div[2]//a")
# 获取全部招聘职位下的所有行业(industry)链接
for b in dashujukaifa_list:
industry_url = b.xpath(".//@href").extract_first()
if industry_url == 'https://jobs.51job.com/dashujukaifa/':
industries_url = industry_url
yield scrapy.Request(
industries_url,
callback=self.industry_perse
)
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QianchengwuyouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
Job_title = scrapy.Field()
# 薪资水平
Pay_level = scrapy.Field()
# 招聘单位
Recruitment_unit = scrapy.Field()
# 工作地点
Workplace = scrapy.Field()
# 工作经验
hands_background = scrapy.Field()
# 学历要求
Education_requirements = scrapy.Field()
# 职位信息(工作内容+任职要求+工作经验)
Career_information = scrapy.Field()
# 关键字:keyword
keyword = scrapy.Field()
pipelines.py:启用数据库
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from pymongo import MongoClient
class QianchengwuyouPipeline:
def open_spider(self,spider):
self.db = MongoClient("localhost", 27017).qiancheng # 创建数据库yc
self.collection = self.db.yc_collection # 创建一个集合
def process_item(self, item, spider):
#添加数据到jingjiren表中
self.collection.insert_one(dict(item))
return item
def close_spider(self,spider):
self.collection.close()
反爬在settings.py设置,看个人喜好
BOT_NAME = 'qianchengwuyou'
SPIDER_MODULES = ['qianchengwuyou.spiders']
NEWSPIDER_MODULE = 'qianchengwuyou.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 ' \
'Safari/537.36 Edg/83.0.478.54 '
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
FEED_EXPORT_ENCODING = 'utf-8'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# 启用pipeline
ITEM_PIPELINES = {
'qianchengwuyou.pipelines.QianchengwuyouPipeline':300,
}
mongodb效果如图
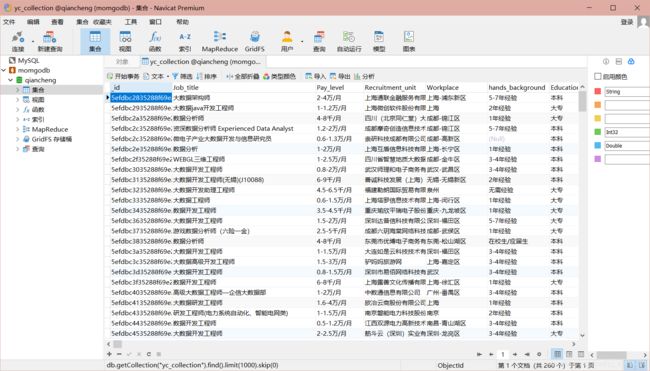
数据分析与可视化:我个人是把所有的功能都集合在一个py文件里,能注释的都注释了,大家应该能看懂
import pymongo # python连接mongodb数据库模块
import re
from wordcloud import WordCloud # 词云图绘制模块
from collections import Counter # 获取数据库链接游标
from pyecharts.charts import Bar, Pie, WordCloud # bar:条形图绘制模块,pie:饼图绘制模块,wordcloud:词云图绘制模块
from pyecharts.render import make_snapshot # 绘图模块
from snapshot_phantomjs import snapshot
from pyecharts import options as opts, options
# pyecharts模块的详细使用教程和实例网址:http://pyecharts.org/#/
myclient = pymongo.MongoClient("127.0.0.1", port=27017) # 数据库IP地址
mydb = myclient["qiancheng"] # 数据库名称
mytable = mydb["yc_collection"] # 表名称
# 分析相关岗位的平均工资、最高工资、最低工资
# def shujufenxi(query):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
# 岗位
addr_list = []
class PyMongoDemo(object):
def shujufenxi_1(self):
Job = input("请输入你想要分析的职业:")
# 遍历循环
for i in mytable.find(
{
"$and": [
{
"Job_title": {
"$regex": "{job}".format(job=Job)}},
{
"Pay_level": {
"$regex": "万/月"}}
]}
):
# 拆分列表获取关键数据
min_salary = i["Pay_level"].split("-")[0]
print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (i["Pay_level"].split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 设置横坐标的对象
company = i["Job_title"]
print(company)
# 将获取的数据分别写入
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="10000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="{}薪资".format(Job), subtitle="单位 万/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={
"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("{}_1.html".format(Job))
def shujufenxi_2(self):
Job = input("请输入你想要分析的职业:")
for i in mytable.find(
{
"$and": [{
"Job_title": {
"$regex": "{}".format(Job)}}, {
"Pay_level": {
"$regex": "千/月"}}]}):
min_salary = i["Pay_level"].split("-")[0]
print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (i["Pay_level"].split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
company = i["Job_title"]
print(company)
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="10000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="{}薪资", subtitle="单位 千/月").format(Job),
xaxis_opts=opts.AxisOpts(axislabel_opts={
"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("{}_1.html").format(Job)
def diqugangweishu(self):
init_opts: opts.InitOpts = opts.InitOpts()
chengdu_num = 0
beijing_num = 0
shanghai_num = 0
guangzhou_num = 0
shenzhen_num = 0
for i in mytable.find({
"Job_title": {
"$regex": "大数据"}}, {
'Job_title', 'Workplace'}):
Workplace = i["Workplace"].split("-")[0]
if "成都" in Workplace:
chengdu_num += 1
elif "北京" in i["Workplace"]:
beijing_num += 1
elif "上海" in i["Workplace"]:
shanghai_num += 1
elif "广州" in i["Workplace"]:
guangzhou_num += 1
elif "深圳" in i["Workplace"]:
shenzhen_num += 1
print(chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num)
# all_num = chengdu_num + beijing_num + shanghai_num + guangzhou_num + shanghai_num
data = [("成都", chengdu_num), ("北京", beijing_num), ("上海", shanghai_num), ("广州", guangzhou_num),
("深圳", shenzhen_num)]
num = [chengdu_num, beijing_num, shanghai_num, guangzhou_num, shenzhen_num]
print(data)
# 创建条形图
# data_pair = [list(z) for z in zip(addr, num)]
# bar = Bar(init_opts=opts.InitOpts(width="1800px", height="800px"))
# bar.set_global_opts(
# title_opts=opts.TitleOpts(title="数据分析师地区岗位个数", subtitle="单位 个"),
# xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
# )
# bar.add_xaxis(addr)
# bar.add_yaxis("数据分析师地区岗位个数", num)
# bar.render("数据分析师地区岗位个数.html")
# 创建图表对象
pie = Pie()
# 关联数据
pie.add(
# 设置系列名称
series_name="大数据岗位地区分析",
# 设置需要展示的数据
data_pair=data,
# 设置圆环空心部分和数据显示部分的比例
radius=["30%", "70%"],
# 设置饼是不规则的
rosetype="radius"
)
# 设置数据显示的格式
pie.set_series_opts(label_opts=options.LabelOpts(formatter="{b}: {d}%"))
# 设置图表的标题
pie.set_global_opts(title_opts=options.TitleOpts(title="手机销量"))
# 数据渲染
pie.render('数据分析地区岗位.html')
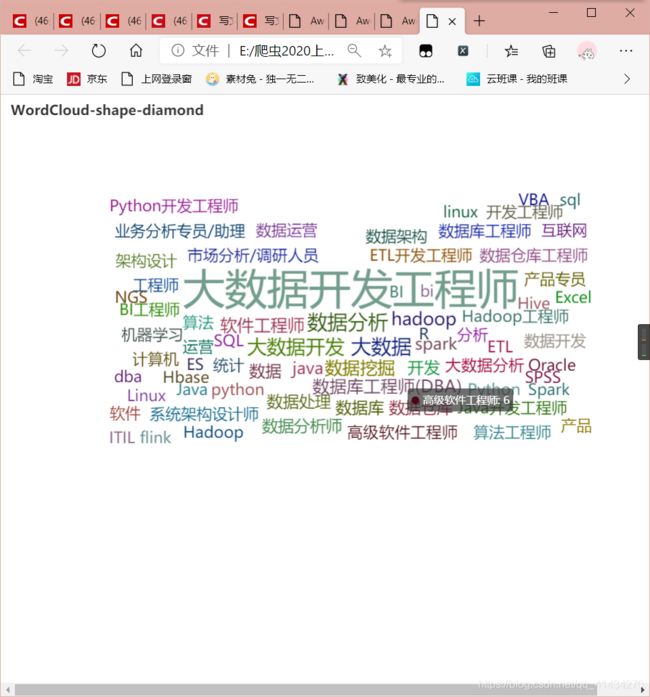
# “数据采集”岗位要求的技能词云图
def ciyuntu(self):
keyword_num = 0
a = []
for i in mytable.find({
}, {
"keyword"}):
keyword = list(i["keyword"])
# print(keyword_list)
a.append(keyword)
# print(a)
keyword_num += 1
print(a)
keyword_list = sum(a, [])
word_count = {
}
for word in keyword_list:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
print(word_count)
lst = Counter(word_count)
result = lst.most_common()
# print(lst.most_common())
print(result)
keyword_list = ' '.join(keyword_list)
# print(keyword_list)
# print(keyword_num)
def wordcloud_chart() -> WordCloud:
c = (
WordCloud()
.add("",
result,
shape="cardioid",
word_size_range=[20, 55], )
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-shape-diamond"))
.render("大数据关键字词云图.html")
# .render("大数据关键字词云图.png")
)
return c
# make_snapshot(snapshot, wordcloud_chart(), "大数据关键字词云图.png")
# 分析大数据相关岗位1-3年工作经验的薪资水平
def fenxi1_3xinzishuiping(self):
choice1 = "万/月"
choice2 = "千/月"
choice = input("请输入你要分析的薪资单位(1:万/月,2:千/月):")
if choice == '1':
choice = choice1
elif choice == '2':
choice = choice2
else:
return choice
print(choice)
for i in mytable.find({
"$or": [{
"hands_background": {
"$regex": "1"}}, {
"hands_background": {
"$regex": "2"}},
{
"hands_background": {
"$regex": "3"}}
], "$and": [{
"Job_title": {
"$regex": "大数据"}}, {
"Pay_level": {
"$regex": "{}".format(choice)}}]},
{
"Job_title", "Pay_level", "hands_background"}):
print(i)
min_salary = i["Pay_level"].split("-")[0]
# print(min_salary)
max_salary = re.findall(r'([\d+\.]+)', (i["Pay_level"].split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
company = i["Job_title"]
# print(company)
min_salary_list.append(min_salary)
max_salary_list.append(max_salary)
average_salary_list.append(average_salary)
addr_list.append(company)
bar = Bar(
init_opts=opts.InitOpts(width="10000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="大数据相关岗位1-3年工作经验的薪资", subtitle="单位 {}".format(choice)),
xaxis_opts=opts.AxisOpts(axislabel_opts={
"rotate": 45}),
)
bar.add_xaxis(addr_list)
bar.add_yaxis("最高薪资", max_salary_list)
bar.add_yaxis("最低薪资", min_salary_list)
bar.add_yaxis("平均薪资", average_salary_list)
bar.render("分析大数据相关岗位1-3年工作经验的薪资水平.html")
if __name__ == "__main__":
mongo = PyMongoDemo()
a = 0
b = 0
a = str(input("请输入你要选择的功能(1:分析输入岗位的薪资水平,2:分析大数据岗位的地区分布,3:分析大数据相关岗位1-3年工作经验的薪资水平),4:绘制大数据关键字词云图:"))
while True:
if a == '1':
b = str(input("请输入你要选择的工资单位(1:万/月,2:千/月):"))
if b == '1':
mongo.shujufenxi_1()
continue
elif b == '2':
mongo.shujufenxi_2()
continue
else:
print("请输入正确的数字")
continue
elif a == '2':
mongo.diqugangweishu()
continue
elif a == '3':
mongo.fenxi1_3xinzishuiping()
continue
elif a == '4':
mongo.ciyuntu()
continue
else:
print("输入错误,请重新输入!")
break
# mongo.shujufenxi_1()
# mongo.shujufenxi_2()
# mongo.diqugangweishu()
# mongo.ciyuntu()
# mongo.fenxi1_3xinzishuiping()
该文件所使用的python模块尽量全部都安装
附上效果图
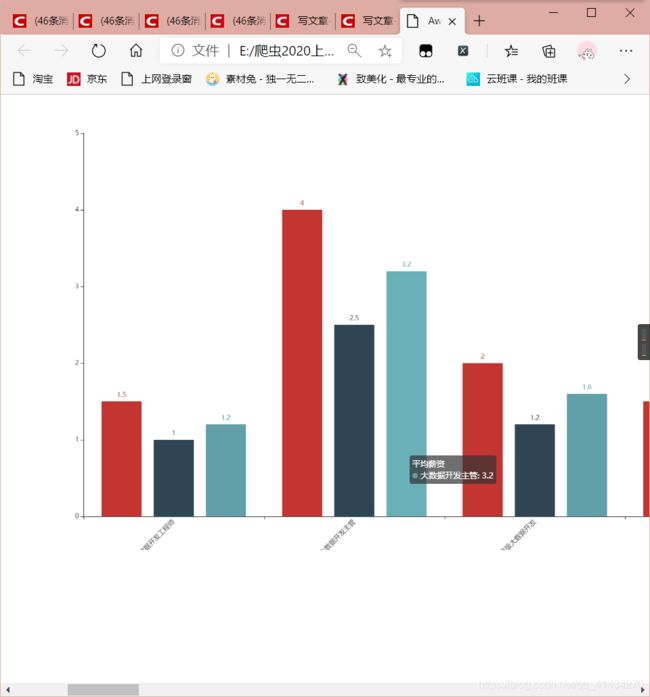
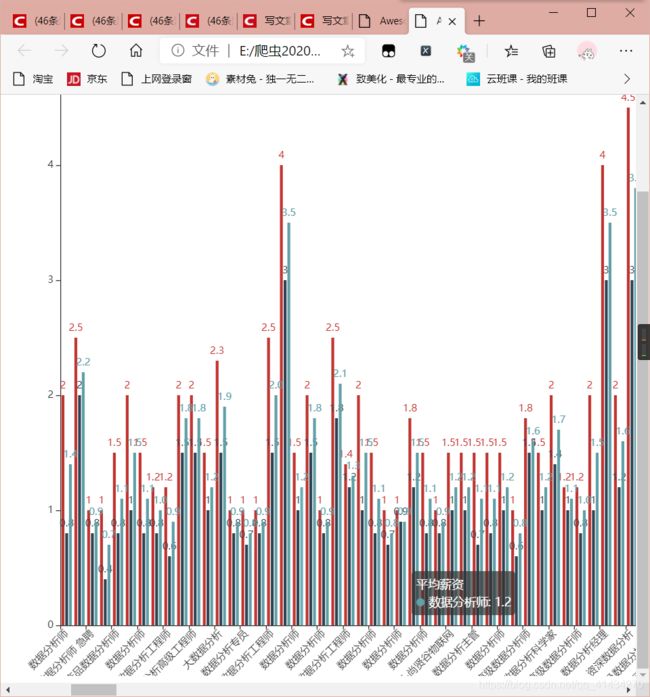
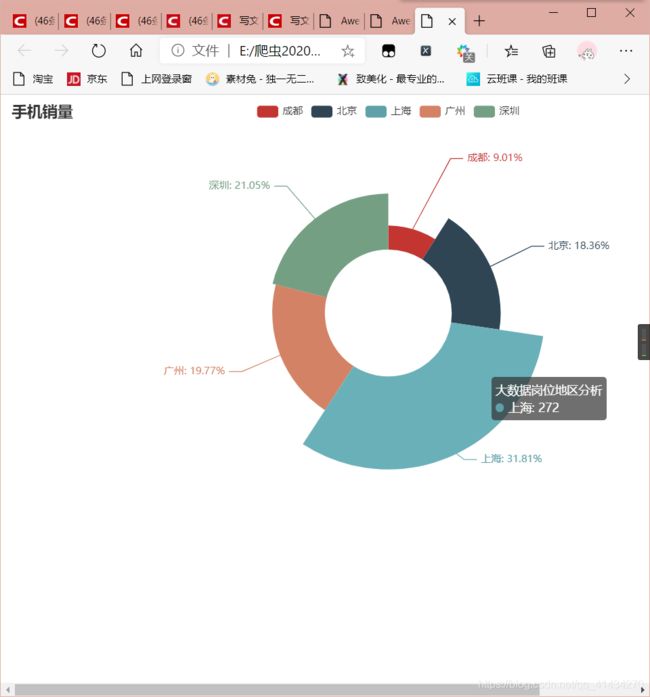
到此结束!再见各位