DolphinDB流数据教程
实时流处理一般是将业务系统产生的数据进行实时收集,交由流处理框架进行数据清洗,统计,入库,并可以通过可视化的方式对统计结果进行实时的展示。传统的面向静态数据表的计算引擎无法胜任流数据领域的分析和计算任务。在金融交易、物联网、互联网/移动互联网等应用场景中,复杂的业务需求对大数据处理的实时性提出了更高的要求。对于这一类高实时性需求的场景,需要一个快速、高效、灵活可控的流式大数据处理平台来支撑。
DolphinDB内置的流数据框架支持流数据发布、订阅、流数据预处理、实时内存计算、复杂指标的滚动窗口计算等,是一个运行高效,使用便捷的流数据处理框架。
与其它流数据系统相比,DolphinDB database 流数据处理系统的优点在于:
- 吞吐量大,低延迟
- 与时序数据库及数据仓库集成,一站式解决方案
- 天然具备流表对偶性,支持SQL语句数据注入和查询分析
本教程包含以下内容:
- DolphinDB流数据框架及概念
- 使用DolphinDB流数据
- 使用Java API来订阅DolphinDB流数据
- 监控流数据运行状态
- 流数据性能调优
- 与开源系统Grafana结合使用
1. DolphinDB流数据框架及概念
流数据框架对流数据的管理和应用是基于发布-订阅-消费的模式,通过流数据表来发布数据,数据节点或者第三方的应用可以通过DolphinDB脚本或者 API来订阅消费流数据。
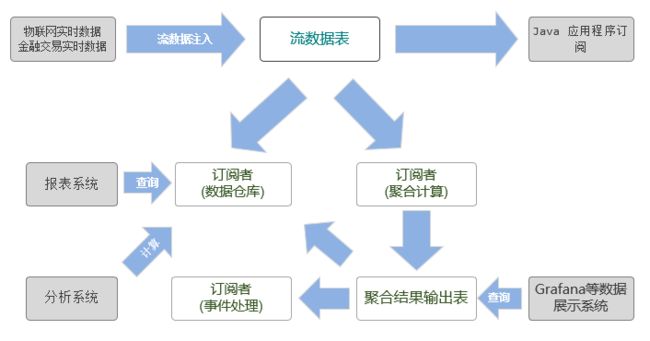
上图展示了DolphinDB的流数据处理框架。把实时数据注入到发布节点流数据表后,发布的数据可以同时供多方订阅消费:
- 可由数据仓库订阅并保存,作为分析系统与报表系统的数据源。
- 可以由聚合引擎订阅,进行聚合计算,并将聚合结果输出到流数据表。聚合结果既可以由Grafana等流数据展示平台展示,也可以作为数据源再次发布出去,供二次订阅做事件处理。
- 也可由API订阅,例如第三方的Java应用程序可以通过Java API订阅流数据,应用到业务系统中。
1.1 实时流数据表
DolphinDB实时流数据表可以作为发布和订阅流数据的载体,发布一条消息等价于往流数据表插入一条记录,同时它也可以通过SQL来进行查询和分析。
1.2 发布和订阅
DolphinDB的流数据框架使用了经典的订阅发布模式。每当有新的流数据写入时,发布方会通知所有的订阅方去处理新的流数据。数据节点通过subscribeTable函数来订阅发布的流数据。
1.3 实时聚合引擎
实时聚合引擎指的是专门用于处理流数据实时计算和分析的模块。DolphinDB提供createStreamAggregator函数用于持续地对流数据做实时聚合计算,并且将计算结果持续输出到指定的数据表中,具体如何使用聚合引擎可以参考流数据聚合引擎教程。
2. 使用DolphinDB流数据
要开启DolphinDB支持流数据功能的模块,需要对DolphinDB数据节点增加配置项。
对于发布节点需要的配置项:
maxPubConnections:发布信息节点能够连接的最大节点数。如果maxPubConnections>0,节点可以作为信息发布节点。默认值为0。
persisitenceDir:共享的流数据表保存的路径。如果需要保存流数据表,必须指定该参数。
persistenceWorkerNum:负责以异步模式保存流数据表的工作线程数。默认值为0。
maxPersistenceQueueDepth:异步保存流数据表时,允许的最大消息队列深度。
maxMsgNumPerBlock:当服务器发布或组合消息时,消息块中的最大记录数。
maxPubQueueDepthPerSite:发布节点可容许的最大消息队列深度。对于订阅节点需要的配置项:
subPort:订阅线程监听的端口号。当节点作为订阅节点时,该参数必须指定。默认值为0。
subExecutors:订阅节点中消息处理线程的数量。默认值为0,表示解析消息线程也处理消息。
maxSubConnections:服务器能够接收的最大的订阅连接数。默认值是64。
subExecutorPooling: 表示执行流计算的线程是否处于pooling模式的布尔值。默认值是false。
maxSubQueueDepth:订阅节点可容许的最大消息队列深度。2.1 流数据发布
定义一个streamTable,向其写入数据即意味着发布流数据,由于流数据表需要被不同的会话访问,所以要使用share,将流数据表进行共享。下面的例子中,定义并共享流数据表pubTable,向pubTable表写入数据即意味着发布数据:
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable2.2 流数据订阅
订阅数据通过subscribeTable函数来实现。
语法如下:
subscribeTable([server], tableName, [actionName], [offset=-1], handler, [msgAsTable=false], [batchSize=0], [throttle=1], [hash=-1], [reconnect=false], [filter], [persistOffset=false])
参数说明:
- 只有tableName和handler两个参数是必需的。其他所有参数都是可选参数。
- server:字符串,表示服务器的别名或流数据所在的xdb连接服务器。如果它没有指定,或者为空字符串,表示服务器是本地实例。
实际情况中,发布者与订阅者的关系有三种可能。下面的例子解释这三种情况的server参数如何构造:
- 发布者与订阅者是同一节点。
subscribeTable(, "pubTable", "actionName", 0, subTable , true)发布者与订阅者是同一集群内的不同节点。此处发布节点别名为“NODE2”。
subscribeTable("NODE2", "pubTable", "actionName", 0, subTable , true)发布者与订阅者不在同一个集群内。此处发布者节点为 (host="192.168.1.13",port=8891)。
pubNodeHandler=xdb("192.168.1.13",8891)
subscribeTable(pubNodeHandler, "pubTable", "actionName", 0, subTable , true)- tableName:被订阅的数据表名。
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable
subscribeTable(, "pubTable", "actionName", 0, subTable , true)- actionName:流数据可以针对各种场景分别订阅消费。同一份流数据,可用于实时聚合运算,同时亦可将其存储到数据仓库供第三方应用做批处理。subscribeTable函数提供了actionName参数以区分同一个流数据表被订阅用于不同场景的情况。
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable
topic1 = subscribeTable(, "pubTable", "actionName_realtimeAnalytics", 0, subTable , true)
topic2 = subscribeTable(, "pubTable", "actionName_saveToDataWarehouse", 0, subTable , true)subscribeTable函数的返回值是订阅主题,它是订阅表所在节点的别名,流数据表名称和订阅任务名称(如果指定了actionName)的组合,使用下划线分隔。如果订阅主题已经存在,函数将会抛出异常。当前节点别名为:NODE1,上述例子返回的两个topic内容如下:
topic1:
NODE1/pubTable/actionName_realtimeAnalyticstopic2:
NODE1/pubTable/actionName_saveToDataWarehouse- offset:订阅任务开始后的第一条消息所在的位置。消息是流数据表中的行。如果没有指定offset,或为-1,或超过了流数据表的记录行数,订阅将会从流数据表的当前行开始。如果offset=-2,系统会自动获取持久化到磁盘上的offset,并从该位置开始订阅。offset与流数据表创建时的第一行对应。如果某些行因为内存限制被删除,在决定订阅开始的位置时,这些行仍然考虑在内。 下面的示例说明offset的作用,向pubTable写入100行数据,建立三个订阅,分别从102,-1,50行开始订阅:
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable3
vtimestamp = 1..100
vtemp = norm(2,0.4,100)
tableInsert(pubTable,vtimestamp,vtemp)
topic1 = subscribeTable(, "pubTable", "actionName1", 102,subTable1 , true)
topic1 = subscribeTable(, "pubTable", "actionName2", -1, subTable2 , true)
topic1 = subscribeTable(, "pubTable", "actionName3", 50,subTable3 , true)//50从结果看到,subTable1,subTable2都没有数据,subTable3有50条数据,说明只有当offset在从0到数据集记录数之间才能正常起作用,否则订阅会从当前行开始,只有当新数据进入发布表时才能订阅到数据。
- handler:一元函数或表。它用于处理订阅数据。若它是函数,其唯一的参数是订阅到的数据。订阅数据可以是一个数据表或元组,订阅数据表的每个列是元组的一个元素。我们经常需要把订阅数据插入到数据表。为了方便使用,handler也可以是一个数据表,并且订阅数据可以直接插入到该表中。 下面的示例展示handler的两种用途,subTable1直接把订阅数据写入目标table,subTable2通过自定义函数myHandler将数据进行过滤后写入。
def myhandler(msg){
t = select * from msg where temperature>0.2
if(size(t)>0)
subTable2.append!(t)
}
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
topic1 = subscribeTable(, "pubTable", "actionName1", -1, subTable1 , true)
topic1 = subscribeTable(, "pubTable", "actionName2", -1, myhandler , true)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)从结果可以看到pubTable写入10条数据,subTable1是全部接收了,而subTable2经过myhandler过滤掉了0.13,收到9条数据。
- msgAsTable:表示订阅的数据是否为表的布尔值。默认值是false,表示订阅数据是由列组成的元组。 订阅数据格式的不同通过下面的示例展示:
def myhandler1(table){
subTable1.append!(table)
}
def myhandler2(tuple){
tableInsert(subTable2,tuple[0],tuple[1])
}
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable2
//msgAsTable = true
topic1 = subscribeTable(, "pubTable", "actionName1", -1, myhandler1 , true)
//msgAsTable = false
topic2 = subscribeTable(, "pubTable", "actionName2", -1, myhandler2 , false)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)- batchSize:一个整数,表示批处理的消息的行数。如果它是正数,直到消息的数量达到batchSize时,handler才会处理进来的消息。如果它没有指定或者是非正数,消息一进来,handler就会处理消息。 下面示例展示当batchSize设置为11时,先向pubTable写入10条数据,观察订阅表,然后再写入1条数据,再观察数据。
//batchSize
share streamTable(10000:0,`timestamp`temperature, [TIMESTAMP,DOUBLE]) as pubTable
share streamTable(10000:0,`ts`temp, [TIMESTAMP,DOUBLE]) as subTable1
topic1 = subscribeTable(, "pubTable", "actionName1", -1, subTable1 , true, 11)
vtimestamp = 1..10
vtemp = 2.0 2.2 2.3 2.4 2.5 2.6 2.7 0.13 0.23 2.9
tableInsert(pubTable,vtimestamp,vtemp)
print size(subTable1)//0
insert into pubTable values(11,3.1)
print size(subTable1)//11从结果可以看到,当发布数据累计到11条时,数据才进入到subTable1。
- throttle:一个整数,表示handler处理进来的消息之前等待的时间,以秒为单位。默认值为1。如果没有指定batchSize,throttle将不会起作用。
batchSize是用来做数据缓冲使用,有时候流数据的写入频率非常高,当消费能力跟不上数据进入的速度时,需要进行流量控制,否者订阅端缓冲区很快会堆积数据并耗光所有的内存。 throttle设定一个时间,根据订阅端的消费速度定时放一批数据进来,保障订阅端的缓冲区数据量稳定。
- hash:一个非负整数,指定某个订阅线程处理进来的消息。如果没有指定该参数,系统会自动分配一个线程。如果需要使用一个线程来处理多个订阅任务的消息,把订阅任务的hash设置为相同的值。当需要在两个或多个订阅的处理过程中保持消息数据的同步,可以将多个订阅的hash值设置成相同,这样就能使用同一个线程来同步处理多个数据源,不会出现数据处理有先后导致结果误差。
- reconnect是一个布尔值。默认值为false,表示如果网络异常等问题导致订阅中断,订阅端不会自动重新订阅,如果设置为true,订阅端会在网络正常时,自动从中断位置重新订阅。如果发布端崩溃导致订阅中断,那么订阅端会在发布端重启后不断尝试重新订阅。若发布端对流数据表启用了持久化,那么发布端重启后会首先读取硬盘上的数据,直到发布端读取到订阅中断位置的数据,订阅端才能成功重新订阅。若发布端没有对流数据表启用持久化,那么将重新订阅失败。如果订阅端崩溃导致订阅中断,即使设置了reconnect=true,订阅端重启后也无法自动重新订阅。
- filter是一个向量。该参数需要配合
setStreamTableFilterColumn函数一起使用。使用setStreamTableFilterColumn指定流数据表的过滤列,流数据表过滤列在filter中的数据才会发布到订阅端,不在filter中的数据不会发布。filter不支持过滤BOOL类型数据。 - persistOffset是一个布尔值,表示是否持久化保存本次订阅已经处理的数据的偏移量,默认值为false。持久化保存的偏移量用于重订阅,可通过
getTopicProcessedOffset函数获取。
例如,订阅时把persistOffset设置为true。
share streamTable(1000:0, `time`sym`qty, [TIMESTAMP, SYMBOL, INT]) as trades
trades_slave = streamTable(1000:0, `time`sym`qty, [TIMESTAMP, SYMBOL, INT])
topic=subscribeTable(, "trades", "trades_slave", 0, append!{trades_slave}, true,0,1,-1,false,,true)
def writeData(n){
timev = 2018.10.08T01:01:01.001 + timestamp(1..n)
symv =take(`A`B, n)
qtyv = take(1, n)
insert into trades values(timev, symv, qtyv)
}
writeData(6);
select * from trades_slave
time sym qty
----------------------- --- ---
2018.10.08T01:01:01.002 A 1
2018.10.08T01:01:01.003 B 1
2018.10.08T01:01:01.004 A 1
2018.10.08T01:01:01.005 B 1
2018.10.08T01:01:01.006 A 1
2018.10.08T01:01:01.007 B 1
getTopicProcessedOffset(topic);
52.3 断线重连
DolphinDB的流数据订阅提供了自动重连的功能,当reconnect设为true时,订阅端会记录流数据的offset,连接中断时订阅端会从offset开始重新订阅。但是,自动重连机制具有一定的局限性。如果订阅端崩溃或者发布端没有对流数据持久化,订阅端无法自动重连。因此,如果要启用自动重连,发布端必须对流数据持久化。启用持久化请参考2.6节。
2.4 发布端数据过滤
发布端可以过滤数据,只发布符合条件的数据。使用setStreamTableFilterColumn指定流数据表的过滤列,流数据表过滤列在filter中的数据才会发布到订阅端,不在filter中的数据不会发布。目前仅支持对一个列进行过滤。例如,发布端上的流数据表trades只发布symbol为IBM或GOOG的数据:
share streamTable(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT]) as trades
setStreamTableFilterColumn(trades, `symbol)
trades_slave=table(10000:0,`time`symbol`price, [TIMESTAMP,SYMBOL,INT])
filter=symbol(`IBM`GOOG)
subscribeTable(, `trades,`trades_slave,,append!{trades_slave},true,,,,,filter)2.5 取消订阅
每一次订阅都由一个订阅主题topic作为唯一标识。如果订阅时topic已存在,那么会订阅失败。这时需要通过unsubscribeTable函数取消订阅才能再次订阅。取消订阅示例如下:
//unsubscribe a local table
unsubscribeTable(,"pubTable","actionName1")
//unsubscribe a remote table
unsubscribeTable("NODE_1","pubTable","actionName1")若要删除共享的流数据表,可以使用undef函数。
undef("pubStreamTable",SHARED)2.6 数据持久化
默认情况下,流计算的表把所有数据保存在内存中。随着流数据持续写入,系统可能会出现内存不足的情况。为了避免这个问题,我们可以设置流数据持久化到磁盘。如果流数据表的行数达到设定的界限值,前面一半的记录行会从内存转移到磁盘。持久化的数据支持重订阅,当订阅指定数据下标时,下标的计算包含持久化的数据。流数据持久化另一个重要的功能是流数据的备份和回复,当节点出现异常重启时,持久化的数据会在重启时自动载入到流数据表。
要启动数据持久化,首先要在节点的配置文件中添加持久化路径:
persisitenceDir = /data/streamCache在脚本中使用enableTablePersistence函数设置针对某一个流数据表启用持久化。 下面的示例针对pubTable表启用持久化,其中asyn=true,compress=true, cacheSize=1000000,即当流数据表达到100万行数据时启用持久化,采用异步方式压缩保存。
对于持久化是否启用异步,需要对持久化数据一致性和性能之间作权衡,当流数据的一致性要求极高时,可以使用同步方式,这样只有保证持久化做完,数据才会进入发布队列;若对实时性要求极高,不希望磁盘IO影响到流数据的实时性,那么可以启用异步方式,只有启用异步方式时,持久化工作线程数persistenceWorkerNum配置项才会起作用,当有多个publisher表需要持久化,增加persistenceWorkerNum可以提升异步保存的效率。
enableTablePersistence(pubTable,true, true, 1000000)当不需要保存在磁盘上的流数据时,通过clearTablePersistence函数可以删除持久化数据。
clearTablePersistence(pubTable)当整个流数据写入结束时,可以使用disableTablePersistence命令关闭持久化。
disableTablePersistence(pubTable)使用getPersistenceMeta函数获取流数据表的持久化细节情况:
getPersistenceMeta(pubTable)输出的结果是一个字典。
//内存中保留数据记录数
sizeInMemory->0
//启用异步持久化
asynWrite->true
//流数据表总记录数
totalSize->0
//启用压缩存储
compress->true
//当前内存中数据相对总记录数的偏移量,在持久化运行过程中遵循公式 memoryOffset = totalSize - sizeInMemory
memoryOffset->0
//已经持久化到磁盘的数据记录数
sizeOnDisk->0
//持久化路径
persistenceDir->/hdd/persistencePath/pubTable
//hashValue是对本表做持久化的工作线程标识,当配置项persistenceWorkerNum>1时,hashValue可能不为0
hashValue->0
3. 使用Java API来订阅DolphinDB流数据
当流数据进入DolphinDB并发布之后,数据的消费者可能是DolphinDB本身的聚合引擎,也可能是第三方的消息队列或者第三方程序。所以DolphinDB提供了Streaming API供第三方程序来订阅流数据。当有新数据进入时,这些通过API的订阅者能够及时的接收到通知,这使得DolphinDB的流数据框架可与第三方的应用做深入的整合。目前DolphinDB提供Java流数据API,后续会逐步支持C++、C#等流数据API。
Java API处理数据的方式有两种:轮询方式(Polling)和事件方式(EventHandler)。
轮询方式示例代码(Java):
PollingClient client = new PollingClient(subscribePort);
TopicPoller poller1 = client.subscribe(serverIP, serverPort, tableName, offset);
while (true) {
ArrayList msgs = poller1.poll(1000);
if (msgs.size() > 0) {
BasicInt value = msgs.get(0).getEntity(2); //取数据中第一行第二个字段
}
} 当每次流数据表有新数据发布时,poller1会拉取到新数据,否则会阻塞在poller1.poll方法这里等待。
事件方式示例代码:
Java API使用预先设定的MessageHandler获取和处理新数据。 首先需要调用者先定义数据处理器Handler,Handler需要实现com.xxdb.streaming.client.MessageHandler接口。
Handler实现示例如下:
public class MyHandler implements MessageHandler {
public void doEvent(IMessage msg) {
BasicInt qty = msg.getValue(2);
//..处理数据
}
}在启动订阅时,把handler实例作为参数传入订阅函数。
ThreadedClient client = new ThreadedClient(subscribePort);
client.subscribe(serverIP, serverPort, tableName, new MyHandler(), offsetInt);当每次流数据表有新数据发布时,API会调用MyHandler方法,并将新数据通过msg参数传入。
4. 监控流数据运行状态
当流数据通过订阅方式进行数据的实时处理,所有的计算都在后台进行,用户无法直观的看到运行的情况。DolphinDB提供getStreamingStat函数,可以全方位监控流数据状态。
getStreamingStat函数返回的是一个tuple结构,其中包含了pubConns, subConns, persistWorker, subWorkers四个表。
4.1 pubConns
pubConns表是流数据发布者状态监控。每个发布者线程的最大队列深度默认是1000万。
列名称 说明
client 发布端信息,记录发布端IP和端口
queueDepthLimit 发布端数据缓冲区队列最大限制
queueDepth 发布端数据缓冲区队列深度
tables 发布的流数据表,多表通过,号分隔查看表内容:
getStreamingStat().pubConns
client queueDepthLimit queueDepth tables
192.168.1.61:8086 10,000,000 0 st1,st
pubConns表会列出当前所有的publisher节点,发布队列情况,以及发布的流数据表名称。
4.2 subConns
subConns表是流数据订阅者链接状态监控。
列名称 说明
publisher 发布端信息,记录发布端IP和端口
cumMsgCount 累计订阅消息数
cumMsgLatency 累计消息延迟时间(毫秒)
lastMsgLatency 最后一次订阅数据延迟时间(毫秒)
lastUpdate 最后一次数据更新时间查看表内容:
getStreamingStat().subConns
publisher cumMsgCount cumMsgLatency lastMsgLatency lastUpdate
local8081 199,980 19,799 10,990 2018.11.21T07:19:59.767945044这张表列出所有非本地订阅方的链接状态和消息统计信息。
4.3 persistWorkers
persistWorkers 表是持久化工作线程监控。每个持久化工作线程的最大队列深度默认是1000万。
列名称 说明
workerId worker编号
queueDepthLimit 队列深度限制
queueDepth 队列深度
tables 持久化表只有当持久化启用时,才能通过getStreamingStat获取这张表,这里记录了所有持久化的表信息,这张表的记录数等于persistenceWorkerNum配置数。比如持久化两张数据表,可以通过getStreamingStat().persistWorkers查看。
当persistenceWorkerNum=1时,结果为:
getStreamingStat().persistWorkers
workerId queueDepthLimit queueDepth tables
0 10,000,000 0 st1,st当persistenceWorkerNum=3时,结果为:
getStreamingStat().persistWorkers
workerId queueDepthLimit queueDepth tables
0 10,000,000 0 st
1 10,000,000 0 st1
2 10,000,000 0从结果可以看出,persistenceWorkerNum为持久化数据表提供并行化能力。
4.4 subWorkers
subWorkers表是流数据订阅者工作线程监控,这张表每条记录代表一个订阅工作线程。每个订阅者线程的最大队列深度默认是1000万。
列名称 说明
workerId worker编号
queueDepthLimit 订阅端数据缓冲区队列最大限制
queueDepth 订阅端数据缓冲区队列深度
processedMsgCount 已处理消息数量
failedMsgCount 处理失败消息数量
lastErrMsg 上次失败的消息
topics 已订阅主题配置项subExecutors, subExecutorPooling这两个配置项的对流数据处理的影响,在这张表上可以得到充分的展现。在订阅两张流数据表st、st1时,可以通过getStreamingStat().subWorkers查看。
当subExecutorPooling=false, subExecutors=1时,结果如下:
getStreamingStat().subWorkers
workerId queueDepthLimit queueDepth processedMsgCount failedMsgCount lastErrMsg topics
0 10,000,000 0 0 0 local8081/st/st_act,local8081/st1/st1_act此时,所有表的订阅消息共用一个线程队列。
当subExecutorPooling=false, subExecutors=2时,结果如下:
getStreamingStat().subWorkers
workerId queueDepthLimit queueDepth processedMsgCount failedMsgCount lastErrMsg topics
0 10,000,000 0 0 0 local8081/st/st_act
0 10,000,000 0 0 0 local8081/st/st_act此时,各个表订阅消息分配到两个线程队列独立处理。
当subExecutorPooling=true, subExecutors=2时,结果如下:
getStreamingStat().subWorkers
workerId queueDepthLimit queueDepth processedMsgCount failedMsgCount lastErrMsg topics
0 10,000,000 0 0 0 local8081/st/st_act,local8081/st1/st1_act
0 10,000,000 0 0 0 local8081/st/st_act,local8081/st1/st1_act此时,各个表的订阅消息共享由两个线程组成的线程池。
当有流数据进入时,可以通过这个表观察到已处理数据量等信息:
getStreamingStat().subWorkers
workerId queueDepthLimit queueDepth processedMsgCount failedMsgCount lastErrMsg topics
0 10,000,000 0 100,621 0 local8081/st/st_act,local8081/st1/st1_act
0 10,000,000 0 99,359 0 local8081/st/st_act,local8081/st1/st1_act5. 流数据性能调优
当数据流量极大而系统来不及处理时,系统监控中会看到订阅端subWorkers表的queueDepth数值极高,此时系统会按照从订阅端队列-发布端队列-数据注入端逐级反馈数据压力。当订阅端队列深度达到上限时开始阻止发布端数据进入,此时发布端的队列开始累积,当发布端的队列深度达到上限时,系统会阻止流数据注入端写入数据。这时可以通过以下几种方式来调整,使得系统对流数据的处理性能达到最优化。
- 调整订阅参数中的batchSize和throttle参数,来组织数据的批处理和控制接收数据的流量,平衡发布端和订阅端的缓存,让数据处理速度和流数据输入速度达到一个动态的平衡。batchSize可以设定等待流数据积累到一定量时才进行消费,可以充分发挥数据批量处理的性能优势,但是这样会带来一定程度的内存占用;而当batchSize比较大的时候,特殊情况下会发生数据量一直没有达到batchSize而长期滞留在缓冲区的情况,throttle参数值是一个时间间隔,它的作用是即使batchSize未满足,也能将缓冲区的数据消费掉。
- 可以通过调整subExecutors配置参数,增加订阅端计算的并行度,来加快订阅端队列的消费速度。系统默认采用哈希算法为每一个订阅分配一个executor。 在订阅处理过程中,如果需要确保两个订阅用同一个executor来处理,可以在订阅函数subscribeTable中指定参数hash的值。两个订阅使用相同的hash值,来指定用同一个线程来处理这两个订阅数据流,这样可以保证这两个流数据表的时序同步。当有多个executor存在时,如果不同订阅的数据流频率不均或者处理复杂度差异很大,容易导致低负载的executor资源闲置。通过设置subExecutorPooling=true,可以让所有executor作为一个共享线程池,共同处理所有订阅的消息。在这种共享池模式下,所有订阅的消息进入同一个队列,多个executor从队列中读取消息并行处理。共享线程池处理流数据的一个副作用是不能保证消息按到达的时间顺序处理。当实际场景对消息处理的时间顺序有严格要求时,不能开启此设置。
- 若流数据表(stream table)启用同步持久化,那么磁盘的IO可能会成为瓶颈。一种处理方法是参考2.4采用异步方式持久化数据,同时设置一个合理的持久化队列(maxPersistenceQueueDepth,默认值10000000条消息)。当然也可以通过更换硬件,提供更高写入性能的存储设备比如SSD硬盘来提高写入性能。持久化路径通过参数persistence来设置。
- 如果数据发布端(publisher)成为系统的瓶颈,譬如订阅的客户端太多可能导致发布瓶颈,可以采用几种处理办法。首先可以通过多级级联降低每一个发布节点的订阅数量,对延迟不敏感的应用可以订阅二级甚至三级的发布节点。其次可以调整部分参数来平衡延迟和吞吐量两个指标。参数maxMsgNumBlock设置批量发送消息时批的大小,默认值是1024。一般情况下,批的值较大,吞吐量能提升,但网络延迟会增加。
- 若输入流数据的流量波动较大,高峰期导致消费队列积压至队列峰值(默认1000万),那么可以修改配置项maxPubQueueDepthPerSite和maxSubQueueDepth来增加发布端和订阅端的最大队列深度,提高系统抵抗数据流大幅波动的能力。队列深度增加时,内存消耗会增加,要正确估算内存的使用量,合理配置内存。
6. 流数据的展示
流数据可视化按功能可以分为两种可视化类型:
- 一种是实时值监控,用滑动窗口固定一个时间区间,把流数据聚合为一个值,并定时刷新,通常用于指标的监控和预警;
- 另一种是趋势监控,把新产生的数据附加到原有的数据上并以可视化图表的方式渐进更新,通常用于做数据全局分析。
现有很多数据可视化的平台都能支持流数据的实时监控,比如当前流行的开源数据可视化框架Grafana, 它可以设定固定时间间隔去请求流数据表,并把数据以动态更新的数字或图表方式展示出来。DolphinDB已经实现了Grafana的服务端和客户端的接口,具体将配置可以参考教程Grafana如何连接 DolphinDB database。