推荐排序模型3——DeepFM及python(DeepCTR)实现
CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数除以广告的展现量。
CTR是衡量互联网广告效果的一项重要指标。
CTR预估数据特点:
1)输入中包含类别型和连续型数据。类别型数据需要one-hot,连续型数据可以先离散化再one-hot,也可2)以直接保留原值
3)维度非常高
4)数据非常稀疏
5)特征按照Field分组
CTR预估重点在于学习组合特征。注意,组合特征包括二阶、三阶甚至更高阶的,阶数越高越复杂,越不容易学习。
Google的论文研究得出结论:高阶和低阶的组合特征都非常重要,同时学习到这两种组合特征的性能要比只考虑其中一种的性能要好。在DeepFM提出之前,已有LR,FM,FFM,FNN,PNN(以及三种变体:IPNN,OPNN,PNN*),Wide&Deep模型,这些模型在CTR或者是推荐系统中被广泛使用。本篇重点总结DeepFM算法。
FM系列模型1——FM、FFM及python(xlearn)实现
目录
- 1,概述
- 2,DeepFM算法
-
- 2.1, FM 部分
- 2.2,DNN部分
- 3,DeepFM实现
-
- 3.1,数据准备
- 3.2, DeepCTR简介
-
- 3.2.1 导入模型,初始化数据
- 3.2.2, 数据预处理
- 3.2.3, 生成feature_columns
- 3.2.4,训练模型
1,概述
LR/SVM这样的模型无法建模非线性的特征交互(interaction),我们只能人工组特征的交叉或者组合,比如通过数据分析发现时间和食谱类的app存在比较强的关联关系,然后把这个特征加到线性模型里去。这种方法的确定是需要人工做特征工程,成本很高,而且很多复杂的特征交互很难发现,就像啤酒和纸尿布这样的关系。
FM通过给每个特征引入一个低维稠密的隐向量来减少二阶特征交互的参数个数,同时实现信息共享,使得在非常稀疏的特征向量上的学习更加容易泛化。理论上FM可以建模二阶以上的特征交互,但是由于计算量急剧增加,实际一般只用二阶的模型。
而(深度)神经网络的优势就是可以多层的网络结构更好的进行特征表示,从而学习高阶的非线性关系。DeepFM的思想就是结合FM在一阶和二阶特征的简洁高效和深度学习在高阶特征交互上的优势,同时通过共享FM和DNN的Embedding来减少参数量和共享信息,从而得到更好的模型。
2,DeepFM算法
特点:FM提取低阶组合特征,Deep提取高阶组合特征。端到端完成,不需要人工特征。而且共享feature_embedding,FM和Deep共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。
假设训练数据的个数为n,每一个训练样本为 ( x , y ) (x,y) (x,y),其中(X由m个field组成,而y∈0,1表示用户是否点击。(X的field可以是category的field,比如性别和地域等;也可以是连续的field,比如年龄。总的field个数可能只有几百个,但是如果用one-hot编码展开的话,这个特征向量会非常高维并且稀疏。我们把每一个 x i x_i xi记为 x i = [ x f i e l d 1 , x f i e l d 2 , … , x f i e l d m ] x_i=[x_{field1},x_{field2},…,x_{fieldm}] xi=[xfield1,xfield2,…,xfieldm],其中每一个 x f i e l d i x_{fieldi} xfieldi是其向量表示(连续的field就是1维的,而Category的field则用one-hot展开)。
DeepFM包括FM和DNN两个部分,最终的预测由两部分输出的相加得到:
y ^ = s i g m o i d ( y F M + y D N N ) \hat{y} = sigmoid(y_{FM}+y_{DNN}) y^=sigmoid(yFM+yDNN)
其中 y F M y_{FM} yFM是FM模型的输出,而 y D N N y_{DNN} yDNN是DNN的输出。模型的结构如下图所示,它包含FM和DNN两个组件。DeepFM如下图所示:

2.1, FM 部分
DeepFM 拆成两部分来看,首先是FM:
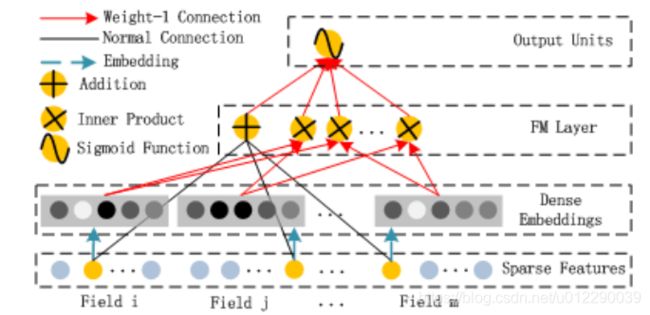
y F M = ⟨ w , x ⟩ + ∑ j 1 = 1 d ∑ j 2 = j 1 + 1 d ⟨ V i , V j ⟩ x j 1 x j 2 \begin{aligned} {y}_{FM} = & \langle w,x \rangle+ \sum_{j_1=1}^{d}\sum_{j_2=j_1+1}^{d}\langle V_i ,V_j\rangle x_{j_1}x_{j_2} \end{aligned} yFM=⟨w,x⟩+j1=1∑dj2=j1+1∑d⟨Vi,Vj⟩xj1xj2
这幅图如何与公式对应起来呢?addition Unit反映的是1阶的特征,inner product反映的是二阶特征。可能你会说,从公式上看这应该是个标量,为什么反映在图上是个向量呢?这里稍有不同,一阶特征和二阶特征该怎么提取还是怎么提取,不过最后没有加起来,而是并联在了一起。实际实现中采用的是FM化简之后的内积公式,最终的维度是:field_size + embedding_size,我们把这两个维度解释一下,就可以理解整个流程了。
1)field size
我们先看一阶特征的提取。首先我们明确x是one-hot之后的结果,是一阶特征,其权值就是w,假设one-hot之后特征数量是feature_size,那么W的维度就是 (feature_size, 1)。这里 是把X和W每一个位置对应相乘相加。由于X是one-hot之后的,所以相当于是进行了一次Embedding,X在W上进行一次嵌入,或者说是一次选择,选择的是W的行,按照X中不为0的那些特征对应的index,选择W中row=index的行。
对于每一个Field都执行这样的操作,就选出来了 X i X_i Xi Embedding之后的表示。注意到,每个Field都肯定会选出且仅选出W中的某一行,因为W的列数是固定的,每一个Field都选出W.cols作为对应的新特征。
把每个Field选出来的这些W的行,拼接起来就得到了X Embedding后的新的表示:维度是num(Field) * num(W.cols)。虽然每个Field的长度可能不同,但是都是在W中选择一行,所以选出来的长度是相同的。**为什么?因为每个field是one-hot的不管field多宽,一个样本只会选一行,这也是Embedding的一个特性:虽然输入的Field长度不同,但是Embedding之后的长度是相同的。**如果num(W.cols)为1(W.cols可以看做是编码维度),那么特征维度就是num(Field)即field size。
综上黑线部分是一个全连接,权重即W,至于addition, 其实并没有什么加法,看做一阶特征输出就行了。
2)embedding_size
我们知道二阶特征提取部分的公式是可以简化的,:
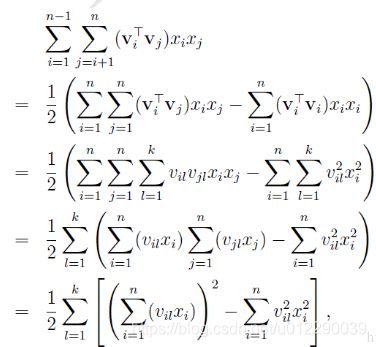
k是什么?k是v的维度,也就是embedding的大小。
这里最后的结果中是在[1,K]上的一个求和。 K就是w(w可以分解为v)的列数,就是Embedding后的维度,也就是embedding_size。也就是说,在DeepFM的FM模块中,最后没有对结果从[1,K]进行求和。而是把这K个数拼接起来形成了一个K维度的向量,如上图所示。
所以这里得到的是维度为embedding_size的特征向量,综合field size部分得到上图FM layer部分。
因此FM需要训练的有两部分:
1) input_vector和Addition Unit相连的全连接层,也就是1阶的Embedding矩阵
2)Sparse Feature到Dense Embedding的Embedding矩阵,中间也是全连接的,要训练的是中间的权重矩阵,这个权重矩阵也就是隐向量V(全连接的w分解得到v,v也可合并成w)
FM Component总结:
1)FM模块实现了对于1阶和2阶组合特征的建模。
2)没有使用预训练
3)没有人工特征工程
4)embedding矩阵的大小是:特征数量 * 嵌入维度, 然后用一个index表示选择了哪个特征。
2.2,DNN部分
DNN 部分如下,在deepctr中默认的DNN是包含两层128神经元的神经网络。

Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于CTR或推荐系统的数据one-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
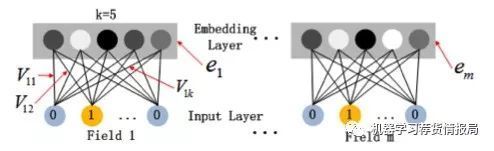
这里继续补充下Embedding层,两个特点:
1)尽管输入的长度不同,但是映射后长度都是相同的.embedding_size 或 k(FM中有讲到,一个field不管多长,都只选一行)
2)embedding层的参数其实是全连接的Weights,是通过神经网络自己学习到的,值得注意的是:FM模块和Deep模块是共享feature embedding的,也就是参数V。
下图为embedding层示意图,起到压缩稠密左右,k也是向量v的维度。
3,DeepFM实现
3.1,数据准备
这里使用了学术界常用的Criteo数据集,这是一个展示广告的数据集,有Criteo提供,曾经是Kaggle的一个比赛,下载地址。
简单看下数据:
label I1 I2 I3 ... C23 C24 C25 C26
0 0 NaN 3 260.0 ... 3a171ecb c0d61a5c NaN NaN
1 0 NaN -1 19.0 ... be7c41b4 ded4aac9 NaN NaN
2 0 0.0 0 2.0 ... bcdee96c 6d5d1302 NaN NaN
3 0 NaN 13 1.0 ... 32c7478e 3b183c5c NaN NaN
4 0 0.0 0 104.0 ... 32c7478e 0d4a6d1a 001f3601 92c878de
其中第1列是真实的标签,0表示没有点击而1表示点击。第2-14列是13个连续的特征,第15-40列是26个Category的特征。
3.2, DeepCTR简介
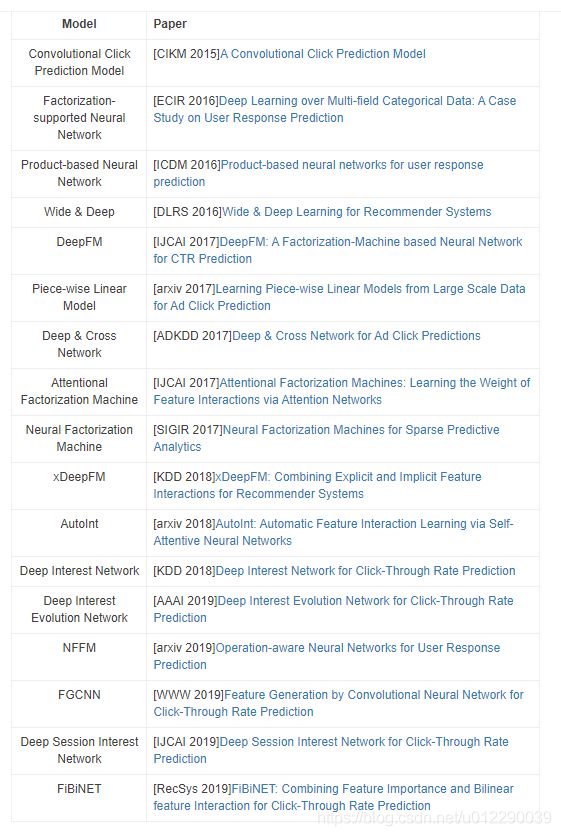
接下来使用的代码主要采用开源的DeepCTR,相应的API文档可以在这里阅读。DeepCTR是一个易于使用、模块化和可扩展的深度学习CTR模型库,它内置了很多核心的组件从而便于我们自定义模型,它兼容tensorflow 1.4+和2.0+。除了DeepFM,DeepCTR还包括更多更新的模型:
DeepCTR 的安装很简单,使用pip即可,包括 pip install deepctr[cpu] 和 pip install deepctr[gpu]两种。
3.2.1 导入模型,初始化数据
#导入模型
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import train_test_split
from deepctr.models import DeepFM
from deepctr.inputs import SparseFeat, DenseFeat,get_feature_names
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I'+str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0,)
target = ['label']
这是一个带表头的csv文件,通过pandas读取成列(features),其中C1-C26是Category的特征(sparse_features),而I1-I13是连续的特征(dense_features)。因为有缺失的值,我们把Category的缺失值设置为”-1”,而把连续的缺失值设置为0。
3.2.2, 数据预处理
接下来需要将category类型的数据转换成数值型,将连续型数据归一化:
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0,1))
data[dense_features] = mms.fit_transform(data[dense_features])
数据处理后大概是这个样子:
label I1 I2 I3 I4 ... C22 C23 C24 C25 C26
0 0 0.000000 0.001332 0.092362 0.000000 ... 0 1 96 0 0
1 0 0.000000 0.000000 0.006750 0.402299 ... 0 7 112 0 0
2 0 0.000000 0.000333 0.000710 0.137931 ... 0 6 53 0 0
3 0 0.000000 0.004664 0.000355 0.045977 ... 0 0 32 0 0
4 0 0.000000 0.000333 0.036945 0.310345 ... 0 0 5 1 47
3.2.3, 生成feature_columns
feature_columns是一些结构化的信息,包含特征名称、embedding维度等,这里将稠密特征信息(连续特征)与稀疏特征信息(类别特征)分开。
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)]
# 或者hash,vocabulary_size通常要大一些,以避免hash冲突太多
# sparse_feature_columns = [SparseFeat(feat, vocabulary_size=1e6,embedding_dim=4,use_hash=True)
# for i,feat in enumerate(sparse_features)]#The dimension can be set according to data
dense_feature_columns = [DenseFeat(feat, 1)
for feat in dense_features]
dnn_feature_columns = sparse_feature_columns + dense_feature_columns
linear_feature_columns = sparse_feature_columns + dense_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
3.2.4,训练模型
train, test = train_test_split(data, test_size=0.2)
train_model_input = {
name:train[name].values for name in feature_names}
test_model_input = {
name:test[name].values for name in feature_names}
model = DeepFM(linear_feature_columns,dnn_feature_columns,task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
首先定义好训练测试样本,然后用DeepFM类定义一个deepfm模型,需要传入的参数是linear_feature_columns和dnn_feature_columns。还有一个参数task=’binary’表明这是一个二分类的问题。接下来是Keras的标准流程:compile、fit和predict。
参考文献:
https://www.sohu.com/a/251772910_633698
http://fancyerii.github.io/2019/12/19/deepfm/