第七章 缺失数据
第七章 缺失数据
学习参考:http://datawhale.club/t/topic/579
文章目录
- 第七章 缺失数据
-
- Ex1:缺失值与类别的相关性检验
- Ex2:用回归模型解决分类问题
Ex1:缺失值与类别的相关性检验
在数据处理中,含有过多缺失值的列往往会被删除,除非缺失情况与标签强相关。下面有一份关于二分类问题的数据集,其中X_1, X_2为特征变量,y为二分类标签。
import numpy as np
import pandas as pd
from scipy.stats import chi2
df = pd.read_csv('../data/missing_chi.csv')
df.head()
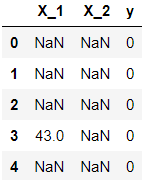
df.isna().sum()/df.shape[0]

df.y.value_counts(normalize=True)


#先取其中一个特征,计算p value
feature = 'X_1'
n01 = ((df[feature].notna())&(df["y"] == 1)).sum()
n00 = ((df[feature].notna())&(df["y"] == 0)).sum()
n10 = ((df[feature].isna())&(df["y"] == 0)).sum()
n11 = ((df[feature].isna())&(df["y"] == 1)).sum()
E = np.array([n11,n10,n01,n00]) # 实际值
print(E)
index1 = ['lack','fill']
index2 = ['positive','negative']
df_index = pd.MultiIndex.from_product([index1, index2], names=['feature','y']) # 构建组合索引
print(df_index)
df_feature = pd.DataFrame(E,index = df_index)
df_feature

df_feature = df_feature.reset_index().rename(columns = {
0:'count'})
df_feature_w = df_feature.pivot(index = 'feature',columns = 'y',values = 'count')
df_feature_w
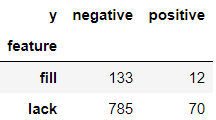
total = df.shape[0]
fill_count = df_feature_w.loc['fill'].sum()
lack_count = df_feature_w.loc['lack'].sum()
negative_count = df_feature_w['negative'].sum()
positive_count = df_feature_w['positive'].sum()
F11 = lack_count*positive_count/total
F10 = lack_count*negative_count/total
F01 = fill_count*positive_count/total
F00 = fill_count*negative_count/total
F = np.array([F11,F10,F01,F00]) # 理论值
print(F)
S = (np.power((E-F),2)/F).sum()
print(S)
![]()
chi2.sf(S,1) # p-value大于0.05,即认为特征"X_1"缺失与否与结果'y'是否为正例无关
![]()
将以上代码转换为函数:
def P_value_feature(feature = "X_1"):
n01 = ((df[feature].notna())&(df["y"] == 1)).sum()
n00 = ((df[feature].notna())&(df["y"] == 0)).sum()
n10 = ((df[feature].isna())&(df["y"] == 0)).sum()
n11 = ((df[feature].isna())&(df["y"] == 1)).sum()
E = np.array([n11,n10,n01,n00]) # 实际值
# print(E)
index1 = ['lack','fill']
index2 = ['positive','negative']
df_index = pd.MultiIndex.from_product([index1, index2], names=['feature','y'])
# print(df_index)
df_feature = pd.DataFrame(E,index = df_index)
df_feature = df_feature.reset_index().rename(columns = {
0:'count'})
df_feature_w = df_feature.pivot(index = 'feature',columns = 'y',values = 'count')
total = df.shape[0]
fill_count = df_feature_w.loc['fill'].sum()
lack_count = df_feature_w.loc['lack'].sum()
negative_count = df_feature_w['negative'].sum()
positive_count = df_feature_w['positive'].sum()
F11 = lack_count*positive_count/total
F10 = lack_count*negative_count/total
F01 = fill_count*positive_count/total
F00 = fill_count*negative_count/total
F = np.array([F11,F10,F01,F00]) # 理论值
# print(F)
S = (np.power((E-F),2)/F).sum()
# print(S)
res = chi2.sf(S,1)
return res
P_value_feature(feature = "X_2") # p-value小于0.05,即认为特征"X_2"缺失与否与结果'y'是否为正例仙相关
![]()
虽然能得到结果,但方法不够灵活,答案提供了更加简洁的求法:
cat_1 = df.X_1.fillna('NaN').mask(df.X_1.notna()).fillna("NotNaN") #缺失值填充为'NaN',非缺失值填充为"NotNaN"
cat_2 = df.X_2.fillna('NaN').mask(df.X_2.notna()).fillna("NotNaN")
cat_1

第二章里有学过,mask函数对传入符合条件(df.X_1.notna())的元素进行替换,当不指定替换值时,替换为缺失值。而where函数则相反,在传入条件为 False 的对应行进行替换。
df_1 = pd.crosstab(cat_1, df.y, margins=True) # 对cat_1和df.y元素进行组合(笛卡尔积),求每个组合的频数
df_2 = pd.crosstab(cat_2, df.y, margins=True)
df_1
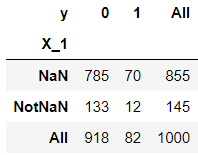
第五章里提到,crosstab函数可以统计元素组合出现的频数,即count操作。
def compute_S(my_df):
S = []
for i in range(2):
for j in range(2):
E = my_df.iat[i, j]
F = my_df.iat[i, 2]*my_df.iat[2, j]/my_df.iat[2,2] # iat索引同iloc索引
S.append((E-F)**2/F)
return sum(S)
res1 = compute_S(df_1)
res2 = compute_S(df_2)
print(chi2.sf(res1, 1))
chi2.sf(res2, 1)
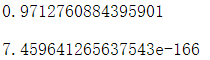
与scipy.stats.chi2_contingency 在不使用 Yates 修正的情况下完全一致:
from scipy.stats import chi2_contingency
print(chi2_contingency(pd.crosstab(cat_1,df.y), correction=False)[1])
chi2_contingency(df_feature_w, correction=False)[1]
Ex2:用回归模型解决分类问题
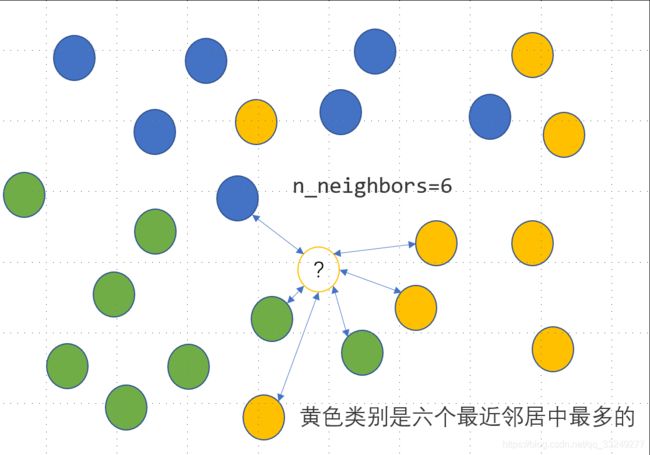
KNN是一种监督式学习模型,既可以解决回归问题,又可以解决分类问题。对于分类变量,利用KNN分类模型可以实现其缺失值的插补,思路是度量缺失样本的特征与所有其他样本特征的距离,当给定了模型参数n_neighbors=n时,计算离该样本距离最近的 n n n个样本点中最多的那个类别,并把这个类别作为该样本的缺失预测类别,具体如下图所示,未知的类别被预测为黄色:
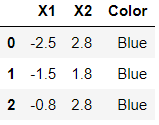
上面有色点的特征数据提供如下:
df = pd.read_excel('../data/color.xlsx')
df.head(3)
已知待预测的样本点为 X 1 = 0.8 , X 2 = − 0.2 X_1=0.8, X_2=-0.2 X1=0.8,X2=−0.2,那么预测类别可以如下写出:
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=6)
clf.fit(df.iloc[:,:2], df.Color)
clf.predict([[0.8, -0.2]])
![]()
- 对于回归问题而言,需要得到的是一个具体的数值,因此预测值由最近的 n n n个样本对应的平均值获得。请把上面的这个分类问题转化为回归问题,仅使用
KNeighborsRegressor来完成上述的KNeighborsClassifier功能。 - 请根据第1问中的方法,对
audit数据集中的Employment变量进行缺失值插补。
对sklearn包的使用不熟练,在此提供答案的思路:
from sklearn.neighbors import KNeighborsRegressor
df_dummies = pd.get_dummies(df.Color) # 利用get_dummies函数使用one-hot编码方式,构建哑变量矩阵
df_dummies
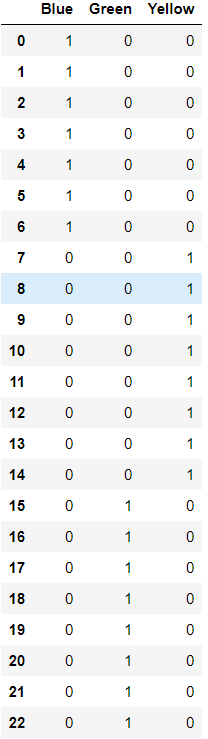
stack_list = []
for col in df_dummies.columns:
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(df.iloc[:,:2], df_dummies[col])
res = clf.predict([[0.8, -0.2]]).reshape(-1,1) # 预测点(0.8, -0.2)为各种颜色(Blue,Green,Yellow)的近似程度,取值范围:[0,1]
stack_list.append(res)
stack_list
![]()
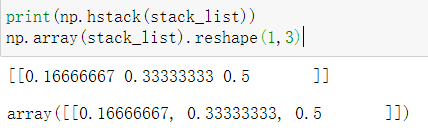
# 预测点可能性最大的颜色
code_res = pd.Series(np.hstack(stack_list).argmax(1))
print(code_res) # type:pd.DataFrame
df_dummies.columns[code_res[0]]

#2.对audit数据集中的Employment变量进行缺失值插补。
df = pd.read_csv('../data/audit.csv')
df.head(3)
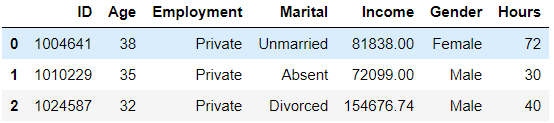
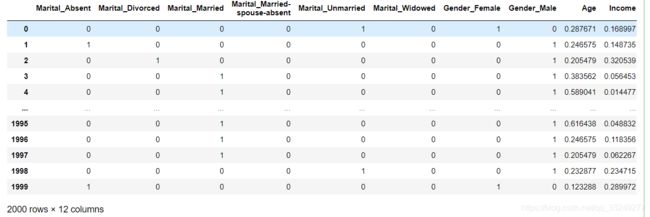
df1 = pd.concat([pd.get_dummies(df[['Marital', 'Gender']]),
df[['Age','Income','Hours']].apply(
lambda x:(x-x.min())/(x.max()-x.min())), df.Employment],1) # 对'Age','Income','Hours'三个变量进行归一化处理
df1
X_train = df1.query('Employment.notna()') # 将Employment元素完整的数据作为训练集
X_test = df1.query('Employment.isna()') # 将Employment元素缺失的数据作为测试集
print(X_test.shape,X_train.shape)
X_train
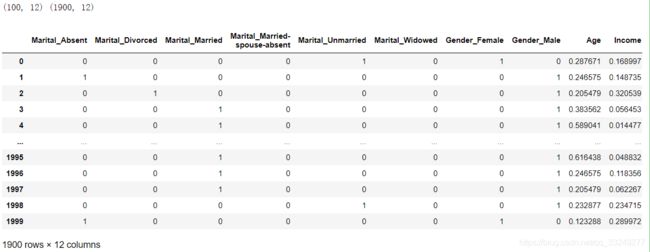
df_dummies = pd.get_dummies(X_train.Employment)
df_dummies
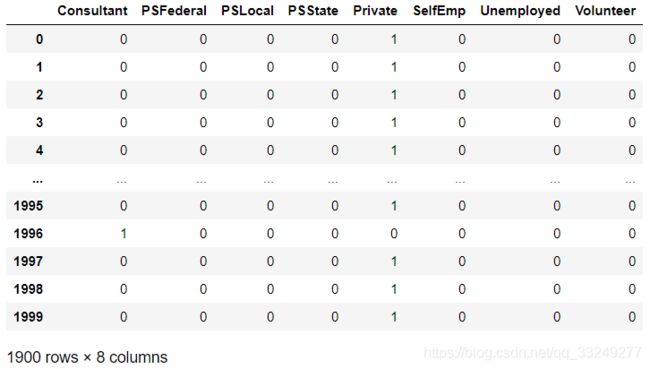
stack_list = []
for col in df_dummies.columns:
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(X_train.iloc[:,:-1], df_dummies[col])
res = clf.predict(X_test.iloc[:,:-1]).reshape(-1,1) # 结果为Employment各种类型的近似程度,取值范围:[0,1]
stack_list.append(res)
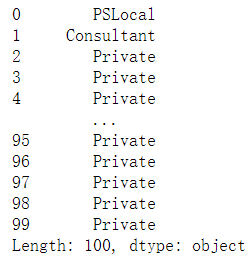
code_res = pd.Series(np.hstack(stack_list).argmax(1)) # 返回结果为Employment的各种类型(0-7为编码)
code_res

dict(zip(list(range(df_dummies.shape[0])),df_dummies.columns)) # Employment的各种类型(0-7为编码)

cat_res = code_res.replace(dict(zip(list(
range(df_dummies.shape[0])),df_dummies.columns)))
cat_res # 测试集结果
df.loc[df.Employment.isna(), 'Employment'] = cat_res.values # 用预测值补充原数据集的缺失项
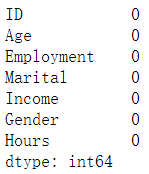
df.isna().sum()