强化学习代码实操和讲解(三)
强化学习代码实操和讲解(三)
- 引言
- 杰克租车问题
-
- 重点代码解析
-
- 环境设置
- poisson_probability:泊松概率的计算
- expected_return:根据给定策略进行策略评估
- figure_4_2:策略迭代主循环和画图
- 结果与讨论
- 赌徒问题
-
- 重点代码解析
-
- 环境设置
- figure_4_3:价值迭代和绘图
- 结果和讨论
- 总结
- 完整代码
-
- 杰克租车问题
- 赌徒问题
引言
本章首先介绍了动态规划这一非常重要的工具,用书上总结性的话来说,通过将贝尔曼方程转化成为近似逼近理想价值函数的递归更新公式,我们就得到了DP算法,实际上,动态规划把原问题分解为不相互独立的子问题,先求解子问题再得到原问题的解,由于一个子问题的解有时候可以被应用多次,所以先求解子问题可以避免重复计算,节省资源;对应到强化学习的策略评估上,就是用所有可能下一状态的价值(子问题)来估计这一状态的价值(原问题),当子问题的解能够被多次应用时(格子世界),动态规划的优势就显现了出来。其实在上一讲的内容中我们就预先用到了这种思想,所以这里不再重复实验格子世界的内容。了解了价值估计后就时策略改进了,书本内容在这里提出了策略迭代和价值迭代两种方法。在策略迭代中,大循环(无限循环直到策略来到最优)内包含了两个部分,一个是策略评估过程,就是利用一个不变的策略通过动态规划来对状态价值进行迭代直至收敛,在此之后就是策略改进,根据上面收敛的状态价值通过最大化收益的方法更新策略,如果新策略和旧策略完全相同,则结束策略迭代,否则利用新策略在此进行策略评估。我们会在实操部分用策略迭代解决杰克租车问题。在价值迭代中,迭代过程不改变策略,价值函数更新过程中利用最大化的价值函数估计来更新,当价值函数收敛后顺着价值函数最大的状态来选择动作,其实这种操作我们在上一章也见过了。我们会用价值迭代的方法来解决赌徒问题。附上原代码来源:来源
杰克租车问题
由于本文要用两种策略改进的方法解决两个问题,所以我们把实操部分分开来讲。首先是杰克租车问题用策略迭代来解决。杰克的一家租车公司有两个停车场,每天都会有用户到两个地点租车,一旦租出杰克就会收获10美元收益,如果那个停车场没车,就会损失订单;租出去的车在还车的第二天变得可用。杰克在夜间可以在两个停车场之间转运车辆,转运一辆2美元。每个地点租车与还车都是一个泊松分布,数量为n的概率为 λ n n ! e − λ \frac{λ^n}{n!}e^{-λ} n!λne−λ。假设租车的λ在两个地点分别为3和4,还车的λ分别为3和2。每一个地点都不能超过20辆车,否则直接消失,每晚最多移动五辆车。折扣率γ=0.9。这个问题条件看似复杂,但是理清状态的表达和动作的表达其实还是挺容易理解的。
重点代码解析
环境设置
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy.stats import poisson
matplotlib.use('Agg')
MAX_CARS=20
MAX_MOVE_OF_CARS=5
RENTAL_REQUEST_FIRST_LOC=3 #在第一个地点租车的λ为3
RENTAL_REQUEST_SECOND_LOC=4 #在第二个地点租车的λ为4
RETURNS_FIRST_LOC=3 #在第一个地点还车的σ为3
RETURNS_SECOND_LOC=2 #在第二个地点换车的σ为2
DISCOUNT=0.9 #折扣系数为0.9
RENTAL_CREDIT=10 #租出车获得收益为10
MOVE_CAR_COST=2 #移动车花费为2
actions=np.arange(-MAX_MOVE_OF_CARS,MAX_MOVE_OF_CARS+1) #借车和还车是概率问题,能够控制的动作只有移动车辆,从第一个地点移除车辆为正,移入车辆为负
POISSON_UPPER_BOUND=11 #设置泊松分布的上界,一旦超过这个界限,租车与还车数量n对应的可能性就归0
poisson_cache=dict() #泊松分布的字典{状态(数量*10+λ):概率}
首先肯定是包的引入和环境参数的设置,除了按照书上的内容设置的固定参数外,有三点值得注意:
1.动作可以有负值,表现运送车辆的方向,从第一个地点移到第二个地点为正,反之为负
2.为泊松分布中的n设定了一个上界,当n超过11时则自动设置为0,因为n过大时概率就变得非常小,直接设置成0可以节约运算资源
3.设置了一个泊松分布的查询字典,根据当前的状态填充或查找概率
poisson_probability:泊松概率的计算
def poisson_probability(n,lam):
global poisson_cache
key=n*10+lam #为了给租车和还车的所有状态一个单独的标签,数量n×10防止标签出现重叠状态
if key not in poisson_cache:
poisson_cache[key]=poisson.pmf(n,lam)
return poisson_cache[key] #返回当前状态下的泊松概率
这个函数根据输入的车辆数n和λ来计算泊松概率并储存在字典中,值得注意的是,字典中的key的设置是为了区分行为,比如说在第二个地点还2辆车这个行为如果直接用n+λ表示,就会和第二个地点借0辆车这一行为重合。当然也可以用别的表示方法,只要保证不同的计算结果对应的标签不重合就好了。
expected_return:根据给定策略进行策略评估
def expected_return(state,action,state_value,constant_return_cars): #根据一个策略估计新的状态价值
returns=0.0 #初始化总收益
returns-=MOVE_CAR_COST*abs(action) #扣除动作(运送汽车)收益
NUM_OF_CARS_FIRST_LOC=min(state[0]-action,MAX_CARS)
NUM_OF_CARS_SECOND_LOC=min(state[1]+action,MAX_CARS) #计算运送车辆之后两个地点的车辆数,不能超过20辆
for rental_request_first_loc in range(POISSON_UPPER_BOUND):
for rental_request_second_loc in range(POISSON_UPPER_BOUND): #对两个地点所有租车可能性进行遍历
prob=poisson_probability(rental_request_first_loc, RENTAL_REQUEST_FIRST_LOC)*poisson_probability(rental_request_second_loc, RENTAL_REQUEST_SECOND_LOC) #计算一种租车情况发生的可能性
num_of_cars_first_loc=NUM_OF_CARS_FIRST_LOC
num_of_car_second_loc=NUM_OF_CARS_SECOND_LOC
valid_rental_first_loc=min(num_of_cars_first_loc,rental_request_first_loc)
valid_rental_second_loc=min(num_of_car_second_loc,rental_request_second_loc) #考虑到租车请求在车辆不足的情况下无法被满足,因而使用有效租车数来记录实际租出去的数量
reward=(valid_rental_first_loc+valid_rental_second_loc)*RENTAL_CREDIT #计算当前租车可能性下的收益
num_of_cars_first_loc-=valid_rental_first_loc
num_of_car_second_loc-=valid_rental_second_loc #更新租车后车场内的车辆数
if constant_return_cars: #如果采用定值还车的方法
returned_car_first_loc=RETURNS_FIRST_LOC
returned_car_second_loc=RETURNS_SECOND_LOC #两个车场每天收到的还车数量为定值
num_of_cars_first_loc=min(num_of_cars_first_loc+returned_car_first_loc,MAX_CARS)
num_of_car_second_loc=min(num_of_car_second_loc+returned_car_second_loc,MAX_CARS) #计算接收到还车后两个车场的车辆数
returns+=prob*(reward+DISCOUNT*state_value[num_of_cars_first_loc,num_of_car_second_loc]) #根据书本P79迭代策略评估中策略评估部分V(s)更新部分公式,这只是求和式内的一条,所有循环结束后的returns为求和式的总值
else:
for returned_car_first_loc in range(POISSON_UPPER_BOUND):
for returned_car_second_loc in range(POISSON_UPPER_BOUND):
prob_return=poisson_probability(returned_car_first_loc, RETURNS_FIRST_LOC)*poisson_probability(returned_car_second_loc,RETURNS_SECOND_LOC) #遍历所有还车可能性
num_of_cars_first_loc_=min(num_of_cars_first_loc+returned_car_first_loc,MAX_CARS)
num_of_car_second_loc_=min(num_of_car_second_loc+returned_car_second_loc,MAX_CARS)
prob_=prob_return*prob #注意这里是四次遍历的最深层,因而要到达这个状态必须把前两个可能性相乘
returns+=prob_*(reward+DISCOUNT*state_value[num_of_cars_first_loc_,num_of_car_second_loc_]) #同样运用书本P79中V(s)的更新公式,这也只是求和式内的一条,所有循环结束后的returns为求和式的总值
return returns
主要解释都写在注释里了,这里有一个可选的固定还车数量的方案,通过constant_return_cars这个参数控制,如果为True就固定还车数量,可以节约计算时间,但是真实度下降。值得注意的是里面所有min函数应用的区域,这些地方都是在根据题意限制一些操作,比如说不能借超过存量的车等等,因为借和还的数量都是概率问题,所以这种人为约束是十分必要的。
figure_4_2:策略迭代主循环和画图
def figure_4_2(constant_return_cars=False):
value=np.zeros((MAX_CARS+1,MAX_CARS+1)) #初始化状态价值
policy=np.zeros(value.shape,dtype=int) #初始化策略
iterations=0
_,axes=plt.subplots(2,3,figsize=(40,20))
axes=axes.flatten()
while True: #大循环,让策略评估与策略改进不断更替迭代
fig=sns.heatmap(np.flipud(policy),cmap='YlGnBu',ax=axes[iterations])
fig.set_ylabel('#cars at first location',fontsize=30)
fig.set_yticks(list(reversed(range(MAX_CARS+1))))
fig.set_xlabel('#cars at second location',fontsize=30)
fig.set_title('policy {}'.format(iterations),fontsize=30)
while True: #策略评估循环
old_value=value.copy()
for i in range(MAX_CARS+1):
for j in range(MAX_CARS+1):
new_state_value=expected_return([i,j], policy[i,j], value, constant_return_cars) #通过上面的函数计算每个状态更新的状态价值
value[i,j]=new_state_value
max_value_change=abs(old_value-value).max() #计算更新后的value和老的value改变的最大值
print('max value change {}'.format(max_value_change))
if max_value_change<1e-4:
break #当状态价值趋于收敛时结束策略评估循环
policy_stable=True
for i in range(MAX_CARS+1): #策略改进循环
for j in range(MAX_CARS+1):
old_action=policy[i,j]
action_returns=[]
for action in actions: #对所有动作选择进行循环,以获得价值最大的动作的索引
if (0<=action<=i) or (-j<=action<=0): #当动作可以被执行时(停车场内的车辆足够被调动)
action_returns.append(expected_return([i,j], action, value, constant_return_cars)) #记录不同动作后获得的收益
else:
action_returns.append(-np.inf) #当动作不可以被执行时,给出无限的惩罚
new_action=actions[np.argmax(action_returns)] #选取回报最大的动作为新动作
policy[i,j]=new_action #用新动作更新当前状态下的策略
if policy_stable and old_action!=new_action:
policy_stable=False
print('policy stable {}'.format(policy_stable))
if policy_stable: #当策略收敛时退出大循环
fig=sns.heatmap(np.flipud(value),cmap='YlGnBu',ax=axes[-1])
fig.set_ylabel('#cars at first location',fontsize=30)
fig.set_yticks(list(reversed(range(MAX_CARS+1))))
fig.set_xlabel('#cars at second location',fontsize=30)
fig.set_title('optimal value',fontsize=30)
break
iterations+=1 #大循环数量+1
这一串代码十分规矩地遵循了书上的算法伪代码,基本步骤我也写在了注释中,值得注意的是第一个while True无限循环部分,这里书上没有显式的表达,但是从书本算法的最后一行可以看出,如果策略没有收敛那就重复策略评估与策略改进的步骤,与这里无限循环直到策略收敛的表达是等价的。
结果与讨论
下面就是杰克租车问题策略迭代的图像。

相比于书上的黑白图片,这里用热图绘制的策略显然更加容易理解。前五张图片是策略迭代的过程,颜色越深表示应该从第一个停车场运往第二个停车场的车辆越多,越浅说明应该从第二个停车场运往第一个停车场的数量越多。比如说,在策略4(收敛)中,当第一个停车场有20辆车,第二个停车场只有1辆车时,颜色最深,表示应该从第一个停车场送5辆车去第二个停车场,这是显然合理的。最后一张图是最佳状态价值的图像,两个停车场的车辆数越多,状态价值越大,这也是容易理解的,因为可以租出去的车辆越多,收益就越大。
完整代码贴在全文末尾。
赌徒问题
赌徒问题的编程相对比较简单,但是最终策略图像却值得我们深思。一个赌徒下注抛硬币,如果硬币正面朝上就获得这次下注的钱(额外增加),如果背面朝上就失去这次下注的钱。每一次抛硬币赌徒必须下整数注。作为MDP问题,状态为赌徒手上的赌资,动作为下注的金额,注意金额不能超过持有的赌资。只有当赌徒获得目标100美元时奖励才为+1,其他时候动作奖励都为0。令硬币正面朝上的概率为0.4。
重点代码解析
环境设置
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.use('Agg')
GOAL=100 #赌徒的目标是赢取100美元,到达这个目标就能获得+1收益(return)
STATE=np.arange(GOAL+1) #含0在内一共101个状态
HEAD_PROB=0.4 #硬币朝上的概率为0.4
引入包并且设置题设参数,值得注意的是我们有含0在内的101个状态。
figure_4_3:价值迭代和绘图
def figure_4_3():
state_value=np.zeros(GOAL+1) #初始化状态价值
state_value[GOAL]=1.0 #把100处的状态价值设置为1
sweeps_history=[] #存储遍历数据,方便画图对比迭代效果
while True:
old_state_value=state_value.copy()
sweeps_history.append(old_state_value) #存储历史遍历的状态价值数据
for state in STATE[1:GOAL]:
actions=np.arange(min(state,GOAL-state)+1) #动作为赌徒可以下注的金额,和他剩余的赌资有关
action_returns=[] #存储每个动作对应的回报,以确定回报最大的动作
for action in actions:
action_returns.append(HEAD_PROB*state_value[state+action]+(1-HEAD_PROB)*state_value[state-action]) #朝上的时候+,朝下的时候-,这里每一步动作没有return,动作的回报只有下一个状态价值那一部分
new_value=np.max(action_returns)
state_value[state]=new_value #把最大的回报作为此时状态的价值函数
delta=abs(state_value-old_state_value).max()
if delta<1e-9:
sweeps_history.append(state_value) #存储历史遍历的状态价值数据
break
policy=np.zeros(GOAL+1) #开始最佳策略的确定
for state in STATE[1:GOAL]:
actions=np.arange(min(state,GOAL-state)+1) #所有可能动作
action_returns=[]
for action in actions:
action_returns.append(HEAD_PROB*state_value[state+action]+(1-HEAD_PROB)*state_value[state-action]) #利用收敛的价值函数计算每个动作后的收益
policy[state]=actions[np.argmax(np.round(action_returns[1:],5))+1] #对动作回报取五位小数进行比较大小,取回报最大的动作为当前状态下的策略
plt.figure(figsize=(10,20))
plt.subplot(2, 1,1)
for sweep,state_value in enumerate(sweeps_history): #绘制历史遍历数据的图像
plt.plot(state_value,label='sweep {}'.format(sweep))
plt.xlabel('Capital')
plt.ylabel('Value estimates')
plt.legend(loc='best')
plt.subplot(2, 1,2)
plt.scatter(STATE, policy) #绘制不同状态下应该投注的散点图(最佳策略)
plt.xlabel('Capital')
plt.ylabel('Final policy (stake)')
plt.savefig('figure_4_3.png')
plt.close()
我把所有注释都写在代码中了。从代码中最佳策略的确定没有在循环迭代圈里可以非常明显地看出策略迭代和价值迭代的区别(策略迭代策略改进也在迭代圈里,价值迭代的策略改进不用迭代)。还有就是本代码中使用sweeps_history来存储每一次迭代后的价值函数,用来绘图和表现改进效果。
结果和讨论
下面就是赌徒问题的价值估计和最后策略。
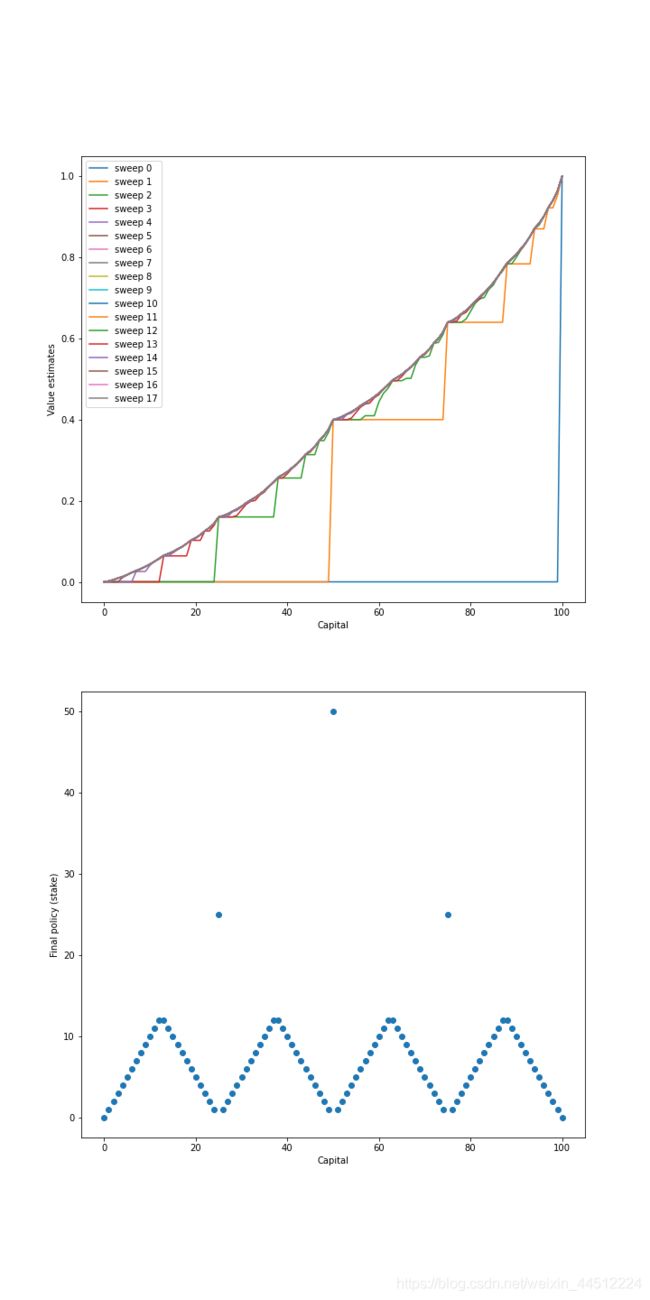
从上图的价值估计历史进程中我们很明显可以看出状态价值的收敛过程,基本上符合我们赌资越多价值越高的主观预期。而最后的策略图像却呈现出一个非常奇怪的形状,这是由于硬币的正面朝上的概率其实是对我们不利的,我们要尽量减少投硬币的次数,所以在赌资为50时选择all in在获得0.4的状态价值,而在51时,如果下小的注(1注),赢了可以来到52,输了回到50,依然有0.4的状态价值。其他情况也可以细品一下,实际上有一整篇论文都在论述这种下注问题( how to gamble if you must),有兴趣可以去搜一下。
我们的强化学习算法在没有任何先验知识的情况下自主学习到了相当正确的下注方法,这是十分令人鼓舞的。
总结
本章的每个小问题都非常简短,代码也比较容易理解,分别中规中矩地运用了策略迭代和价值迭代,对书上概念是一个非常形象的补充。其实在本章最后书上还提到了广义策略迭代(GPI),就是根据优化的策略来更新价值函数,再根据更新的价值函数来优化策略,如此反复直至收敛,几乎任何强化学习算法都可以归入GPI的范畴,本章中的策略迭代对于这种思想的应用最为明显。
完整代码
杰克租车问题
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy.stats import poisson
matplotlib.use('Agg')
MAX_CARS=20
MAX_MOVE_OF_CARS=5
RENTAL_REQUEST_FIRST_LOC=3 #在第一个地点租车的λ为3
RENTAL_REQUEST_SECOND_LOC=4 #在第二个地点租车的λ为4
RETURNS_FIRST_LOC=3 #在第一个地点还车的σ为3
RETURNS_SECOND_LOC=2 #在第二个地点换车的σ为2
DISCOUNT=0.9 #折扣系数为0.9
RENTAL_CREDIT=10 #租出车获得收益为10
MOVE_CAR_COST=2 #移动车花费为2
actions=np.arange(-MAX_MOVE_OF_CARS,MAX_MOVE_OF_CARS+1) #借车和还车是概率问题,能够控制的动作只有移动车辆,从第一个地点移除车辆为正,移入车辆为负
POISSON_UPPER_BOUND=11 #设置泊松分布的上界,一旦超过这个界限,租车与还车数量n对应的可能性就归0
poisson_cache=dict() #泊松分布的字典{状态(数量*10+λ):概率}
def poisson_probability(n,lam):
global poisson_cache
key=n*10+lam #为了给租车和还车的所有状态一个单独的标签,数量n×10防止标签出现重叠状态
if key not in poisson_cache:
poisson_cache[key]=poisson.pmf(n,lam)
return poisson_cache[key] #返回当前状态下的泊松概率
def expected_return(state,action,state_value,constant_return_cars): #根据一个策略估计新的状态价值
returns=0.0 #初始化总收益
returns-=MOVE_CAR_COST*abs(action) #扣除动作(运送汽车)收益
NUM_OF_CARS_FIRST_LOC=min(state[0]-action,MAX_CARS)
NUM_OF_CARS_SECOND_LOC=min(state[1]+action,MAX_CARS) #计算运送车辆之后两个地点的车辆数,不能超过20辆
for rental_request_first_loc in range(POISSON_UPPER_BOUND):
for rental_request_second_loc in range(POISSON_UPPER_BOUND): #对两个地点所有租车可能性进行遍历
prob=poisson_probability(rental_request_first_loc, RENTAL_REQUEST_FIRST_LOC)*poisson_probability(rental_request_second_loc, RENTAL_REQUEST_SECOND_LOC) #计算一种租车情况发生的可能性
num_of_cars_first_loc=NUM_OF_CARS_FIRST_LOC
num_of_car_second_loc=NUM_OF_CARS_SECOND_LOC
valid_rental_first_loc=min(num_of_cars_first_loc,rental_request_first_loc)
valid_rental_second_loc=min(num_of_car_second_loc,rental_request_second_loc) #考虑到租车请求在车辆不足的情况下无法被满足,因而使用有效租车数来记录实际租出去的数量
reward=(valid_rental_first_loc+valid_rental_second_loc)*RENTAL_CREDIT #计算当前租车可能性下的收益
num_of_cars_first_loc-=valid_rental_first_loc
num_of_car_second_loc-=valid_rental_second_loc #更新租车后车场内的车辆数
if constant_return_cars: #如果采用定值还车的方法
returned_car_first_loc=RETURNS_FIRST_LOC
returned_car_second_loc=RETURNS_SECOND_LOC #两个车场每天收到的还车数量为定值
num_of_cars_first_loc=min(num_of_cars_first_loc+returned_car_first_loc,MAX_CARS)
num_of_car_second_loc=min(num_of_car_second_loc+returned_car_second_loc,MAX_CARS) #计算接收到还车后两个车场的车辆数
returns+=prob*(reward+DISCOUNT*state_value[num_of_cars_first_loc,num_of_car_second_loc]) #根据书本P79迭代策略评估中策略评估部分V(s)更新部分公式,这只是求和式内的一条,所有循环结束后的returns为求和式的总值
else:
for returned_car_first_loc in range(POISSON_UPPER_BOUND):
for returned_car_second_loc in range(POISSON_UPPER_BOUND):
prob_return=poisson_probability(returned_car_first_loc, RETURNS_FIRST_LOC)*poisson_probability(returned_car_second_loc,RETURNS_SECOND_LOC) #遍历所有还车可能性
num_of_cars_first_loc_=min(num_of_cars_first_loc+returned_car_first_loc,MAX_CARS)
num_of_car_second_loc_=min(num_of_car_second_loc+returned_car_second_loc,MAX_CARS)
prob_=prob_return*prob #注意这里是四次遍历的最深层,因而要到达这个状态必须把前两个可能性相乘
returns+=prob_*(reward+DISCOUNT*state_value[num_of_cars_first_loc_,num_of_car_second_loc_]) #同样运用书本P79中V(s)的更新公式,这也只是求和式内的一条,所有循环结束后的returns为求和式的总值
return returns
def figure_4_2(constant_return_cars=False):
value=np.zeros((MAX_CARS+1,MAX_CARS+1)) #初始化状态价值
policy=np.zeros(value.shape,dtype=int) #初始化策略
iterations=0
_,axes=plt.subplots(2,3,figsize=(40,20))
axes=axes.flatten()
while True: #大循环,让策略评估与策略改进不断更替迭代
fig=sns.heatmap(np.flipud(policy),cmap='YlGnBu',ax=axes[iterations])
fig.set_ylabel('#cars at first location',fontsize=30)
fig.set_yticks(list(reversed(range(MAX_CARS+1))))
fig.set_xlabel('#cars at second location',fontsize=30)
fig.set_title('policy {}'.format(iterations),fontsize=30)
while True: #策略评估循环
old_value=value.copy()
for i in range(MAX_CARS+1):
for j in range(MAX_CARS+1):
new_state_value=expected_return([i,j], policy[i,j], value, constant_return_cars) #通过上面的函数计算每个状态更新的状态价值
value[i,j]=new_state_value
max_value_change=abs(old_value-value).max() #计算更新后的value和老的value改变的最大值
print('max value change {}'.format(max_value_change))
if max_value_change<1e-4:
break #当状态价值趋于收敛时结束策略评估循环
policy_stable=True
for i in range(MAX_CARS+1): #策略改进循环
for j in range(MAX_CARS+1):
old_action=policy[i,j]
action_returns=[]
for action in actions: #对所有动作选择进行循环,以获得价值最大的动作的索引
if (0<=action<=i) or (-j<=action<=0): #当动作可以被执行时(停车场内的车辆足够被调动)
action_returns.append(expected_return([i,j], action, value, constant_return_cars)) #记录不同动作后获得的收益
else:
action_returns.append(-np.inf) #当动作不可以被执行时,给出无限的惩罚
new_action=actions[np.argmax(action_returns)] #选取回报最大的动作为新动作
policy[i,j]=new_action #用新动作更新当前状态下的策略
if policy_stable and old_action!=new_action:
policy_stable=False
print('policy stable {}'.format(policy_stable))
if policy_stable: #当策略收敛时退出大循环
fig=sns.heatmap(np.flipud(value),cmap='YlGnBu',ax=axes[-1])
fig.set_ylabel('#cars at first location',fontsize=30)
fig.set_yticks(list(reversed(range(MAX_CARS+1))))
fig.set_xlabel('#cars at second location',fontsize=30)
fig.set_title('optimal value',fontsize=30)
break
iterations+=1 #大循环数量+1
plt.savefig('figure_4_2')
plt.close()
if __name__=='__main__':
figure_4_2()
赌徒问题
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.use('Agg')
GOAL=100 #赌徒的目标是赢取100美元,到达这个目标就能获得+1收益(return)
STATE=np.arange(GOAL+1) #含0在内一共101个状态
HEAD_PROB=0.4 #硬币朝上的概率为0.4
def figure_4_3():
state_value=np.zeros(GOAL+1) #初始化状态价值
state_value[GOAL]=1.0 #把100处的状态价值设置为1
sweeps_history=[] #存储遍历数据,方便画图对比迭代效果
while True:
old_state_value=state_value.copy()
sweeps_history.append(old_state_value) #存储历史遍历的状态价值数据
for state in STATE[1:GOAL]:
actions=np.arange(min(state,GOAL-state)+1) #动作为赌徒可以下注的金额,和他剩余的赌资有关
action_returns=[] #存储每个动作对应的回报,以确定回报最大的动作
for action in actions:
action_returns.append(HEAD_PROB*state_value[state+action]+(1-HEAD_PROB)*state_value[state-action]) #朝上的时候+,朝下的时候-,这里每一步动作没有return,动作的回报只有下一个状态价值那一部分
new_value=np.max(action_returns)
state_value[state]=new_value #把最大的回报作为此时状态的价值函数
delta=abs(state_value-old_state_value).max()
if delta<1e-11:
sweeps_history.append(state_value) #存储历史遍历的状态价值数据
break
policy=np.zeros(GOAL+1) #开始最佳策略的确定
for state in STATE[1:GOAL]:
actions=np.arange(min(state,GOAL-state)+1) #所有可能动作
action_returns=[]
for action in actions:
action_returns.append(HEAD_PROB*state_value[state+action]+(1-HEAD_PROB)*state_value[state-action]) #利用收敛的价值函数计算每个动作后的收益
policy[state]=actions[np.argmax(np.round(action_returns[1:],5))+1] #对动作回报取五位小数进行比较大小,取回报最大的动作为当前状态下的策略
plt.figure(figsize=(10,20))
plt.subplot(2, 1,1)
for sweep,state_value in enumerate(sweeps_history): #绘制历史遍历数据的图像
plt.plot(state_value,label='sweep {}'.format(sweep))
plt.xlabel('Capital')
plt.ylabel('Value estimates')
plt.legend(loc='best')
plt.subplot(2, 1,2)
plt.scatter(STATE, policy) #绘制不同状态下应该投注的散点图(最佳策略)
plt.xlabel('Capital')
plt.ylabel('Final policy (stake)')
plt.savefig('figure_4_3.png')
plt.close()
if __name__=='__main__':
figure_4_3()