理解HCLG
理解HCLG
- HCLG
-
- 1 整体图
- 2 理解状态关系
-
- 2.1 基础概念
- 2.2 transition-state
- 2.3 transition-id可视化理解
- 2.4 理解GMM输出transition-id
- 3 理解DNN代替GMM给HMM
- 4 训练过程
- Reference
HCLG
1 整体图
2 理解状态关系
2.1 基础概念
- 【帧的音频特征】:
HMM观察值 - 【hmm-state】 :
HMM的状态,如音素a的 a-B a-M a-E 这三个状态(这里只举例单音素), - 【phone-id】 :
音素的ID,如音素SIL的编号为1,下标从1开始 - 【pdf-id】 :
GMM 的 ID,hmm-state到帧特征(观察值)的发射概率通过一个GMM生成模型 pdf-id生成得到 - 【transition-index】:
一个phone-id的某个hmm-state(正常音素只能转3个)所有可以转移的hmm-state的index索引,见表可理解 - 【transition-id】 :所有的HMM状态间的转移路径弧,下标从1开始
【特别注意】
【pdf-id是绑定到hmm-state上的发射概率函数】
【transition-id是各hmm-state之间跳转的转移概率的唯一id】=>【HMM中的转移矩阵】
【transition-id】的作用确保,状态只能前进如[0-1],[1->2],[2-1]的转移不存在或概率直接设定为0
2.2 transition-state
transition-state = 元组(phone-id, hmm-state-id, forward-pdf-id, self-loop-pdf-id) \text{transition-state}=\text{元组(phone-id, hmm-state-id, forward-pdf-id, self-loop-pdf-id)} transition-state=元组(phone-id, hmm-state-id, forward-pdf-id, self-loop-pdf-id)
【特别注意】self-loop-pdf-id为[自环pdf-id]=[self-loop],forward-pdf-id为[跳转pdf-id]
可参考 trainsition-id结构化
show-transitions phones.txt final.mdl > show-transitions.txt
Transition-state 1: phone = SIL hmm-state = 0 pdf = 0
Transition-id = 1 p = 0.73957 [self-loop]
Transition-id = 2 p = 0.01 [0 -> 1]
Transition-id = 3 p = 0.12042 [0 -> 2]
Transition-id = 4 p = 0.130011 [0 -> 3]
Transition-state 2: phone = SIL hmm-state = 1 pdf = 1
Transition-id = 5 p = 0.950311 [self-loop]
Transition-id = 6 p = 0.01 [1 -> 2]
Transition-id = 7 p = 0.0296972 [1 -> 3]
Transition-id = 8 p = 0.01 [1 -> 4]
Transition-state 3: phone = SIL hmm-state = 2 pdf = 2
Transition-id = 9 p = 0.01 [2 -> 1]
Transition-id = 10 p = 0.910621 [self-loop]
Transition-id = 11 p = 0.0693865 [2 -> 3]
Transition-id = 12 p = 0.01 [2 -> 4]
Transition-state 4: phone = SIL hmm-state = 3 pdf = 3
Transition-id = 13 p = 0.01 [3 -> 1]
Transition-id = 14 p = 0.01 [3 -> 2]
Transition-id = 15 p = 0.893729 [self-loop]
Transition-id = 16 p = 0.0862785 [3 -> 4]
Transition-state 5: phone = SIL hmm-state = 4 pdf = 4
Transition-id = 17 p = 0.955964 [self-loop]
Transition-id = 18 p = 0.0440357 [4 -> 5]
Transition-state 6: phone = Y hmm-state = 0 pdf = 5
Transition-id = 19 p = 0.709512 [self-loop]
Transition-id = 20 p = 0.290488 [0 -> 1]
Transition-state 7: phone = Y hmm-state = 1 pdf = 6
Transition-id = 21 p = 0.876772 [self-loop]
Transition-id = 22 p = 0.123228 [1 -> 2]
Transition-state 8: phone = Y hmm-state = 2 pdf = 7
Transition-id = 23 p = 0.930632 [self-loop]
Transition-id = 24 p = 0.0693677 [2 -> 3]
Transition-state 9: phone = N hmm-state = 0 pdf = 8
Transition-id = 25 p = 0.872881 [self-loop]
Transition-id = 26 p = 0.127119 [0 -> 1]
Transition-state 10: phone = N hmm-state = 1 pdf = 9
Transition-id = 27 p = 0.906704 [self-loop]
Transition-id = 28 p = 0.0932965 [1 -> 2]
Transition-state 11: phone = N hmm-state = 2 pdf = 10
Transition-id = 29 p = 0.953206 [self-loop]
Transition-id = 30 p = 0.0467938 [2 -> 3]
利用python对其格式化为transitions.txt,作为HCLG.fst的isymbol:
【这里要注意哦,加了一个#0 0,会发现HCLG图边里会有一个这样为0的transition-id的arch边】
【可见,pdf-id是绑定到hmm-state上的发射概率函数】
phone[hmm-state->hmm-state] transition-id \pmb{\text{phone[hmm-state->hmm-state] \quad \text{transition-id}}} phone[hmm-state->hmm-state] transition-idphone[hmm-state->hmm-state] transition-idphone[hmm-state->hmm-state] transition-id
``
#0 0
SIL[0->0] 1
SIL[0->1] 2
SIL[0->2] 3
SIL[0->3] 4
SIL[1->1] 5
SIL[1->2] 6
SIL[1->3] 7
SIL[1->4] 8
SIL[2->1] 9
SIL[2->2] 10
SIL[2->3] 11
SIL[2->4] 12
SIL[3->1] 13
SIL[3->2] 14
SIL[3->3] 15
SIL[3->4] 16
SIL[4->4] 17
SIL[4->5] 18
Y[0->0] 19
Y[0->1] 20
Y[1->1] 21
Y[1->2] 22
Y[2->2] 23
Y[2->3] 24
N[0->0] 25
N[0->1] 26
N[1->1] 27
N[1->2] 28
N[2->2] 29
N[2->3] 30
2.3 transition-id可视化理解

【1】一开始,用【所有音素状态对应的GMM(pdf-id)】对所有的音频每一帧,计算出【每一音频帧】在【所有音素状态】上的【发射概率(是一个向量,维度是音素状态数量)】
【2】考虑到时所有音频帧,所以整段音频帧的发射概率矩阵=(音频帧数, 音素状态数)
【3】图中的网格中的点(如下是2个点),可以理解为是(GMM(pdf-id)水平方向音素状态, 音频帧)的发射概率
![]()
要特别感谢七月算法语音识别课程,和HMM学习笔记_3(从一个实例中学习Viterbi算法)

在每次HMM的由【多条边】转向【同一个节点】时【聚合】时会求max

2.4 理解GMM输出transition-id
下面构建一个表格来理解,让充分理解,感谢以kaldi中的yesno为例谈谈transition
所以整个模型,有transition-id,可以对应到pdf-id,也可以对应到HMM-state ID,也可以对应到phone ID
| phone ID | HMM state ID | pdf-id | transition-index | transition-id |
|---|---|---|---|---|
1(SIL) |
0 |
0 |
0 |
1 |
| 1 | 2 | |||
| 2 | 3 | |||
| 3 | 4 | |||
| 4 | 5 | |||
| 1 | 1 | 0 |
6 | |
| 1 | 7 | |||
| 2 | 8 | |||
| 3 | 9 | |||
| 4 | 10 | |||
| 2 | 2 | 0 |
11 | |
| 1 | 12 | |||
| 2 | 13 | |||
| 3 | 14 | |||
| 4 | 15 | |||
| 3 | 3 | 0 |
16 | |
| 1 | 17 | |||
| 2 | 18 | |||
| 3 | 19 | |||
| 4 | 20 | |||
| 4 | 4 | 0 |
21 | |
| 1 | 22 | |||
| 2 | 23 | |||
| 3 | 24 | |||
| 4 | 25 | |||
2(ai1) |
0 |
5 | 0 |
26 |
| 1 | 27 | |||
| 2 | 28 | |||
| 1 | 6 | 0 |
29 | |
| 1 | 30 | |||
| 2 | 31 | |||
| 2 | 7 | 0 |
32 | |
| 1 | 33 | |||
| 2 | 34 |
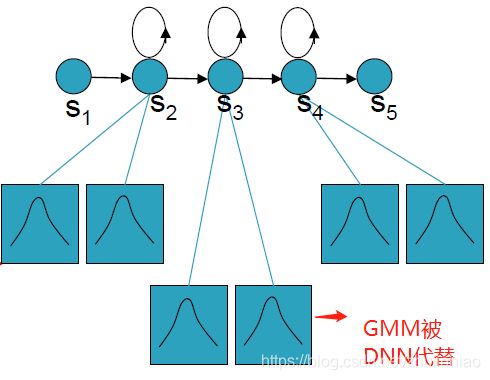
3 理解DNN代替GMM给HMM
HMM所有音素的状态之前都对应一个GMM(暂时不考虑共享),则现在让所有的GMM由一个DNN来控制。
DNN的输出节点是HMM的每一个音素的状态
输出值为每个音素的状态针对观察值(音频帧)的概率
HMM的转移概率(由语言模型的语料决定)和初始概率保持不变
【原来的语音识别公式】
W max = arg max W ∈ L e x i c o n P ( W ∣ O ) = arg max W ∈ L e x i c o n P ( O ∣ W ) P ( W ) P ( O ) = arg max W ∈ L e x i c o n W max P ( O ) { {W}^{\max }}=\underset{W\in Lexicon}{\mathop{\arg \max }}\,P(W|O)=\underset{W\in Lexicon}{\mathop{\arg \max }}\,\frac{P(O|W)P(W)}{P(O)}=\underset{W\in Lexicon}{\mathop{\arg \max }}\,\frac{ {W}^{\max }}{P(O)} Wmax=W∈LexiconargmaxP(W∣O)=W∈LexiconargmaxP(O)P(O∣W)P(W)=W∈LexiconargmaxP(O)Wmax
W W W是要预测出来的文字, O O O是 输入音频 x x x,经过朴素贝叶斯转换后,由于 P ( O ) P(O) P(O)是固定的,因此:
W max = P ( O ∣ W ) P ( W ) { {W}^{\max }}=P(O|W)P(W) Wmax=P(O∣W)P(W)
P ( O ∣ W ) P(O|W) P(O∣W)就是声学模型(O已经知道,但是W不知道,由O生成W的概率,可以由GMM直接得到),P(W)就是是语言模型的概率输出值,而由state(状态)去计算W(文字)很简单,只需要HMM模型即可
【DNN代替GMM后的公式】
DNN无法像GMM那样直接得到 P ( O ∣ W ) P(O|W) P(O∣W),因为DNN只能给出在音频帧O下输出层每个节点(HMM状态)上的后验概率 P ( s t a t e t ∣ O t ) P(stat{ {e}_{t}}|{ {O}_{t}}) P(statet∣Ot),则通过朴素贝叶斯可求得:
P ( O t ∣ s t a t e t ) = P ( s t a t e t ∣ O t ) P ( O t ) P ( s t a t e t ) = P ( s t a t e t ∣ x t ) P ( x t ) P ( s t a t e t ) P({ {O}_{t}}|stat{ {e}_{t}})\text{=}\frac{P(stat{ {e}_{t}}|{ {O}_{t}})P({ {O}_{t}})}{P(stat{ {e}_{t}})}=\frac{P(stat{ {e}_{t}}|{ {x}_{t}})P({ {x}_{t}})}{P(stat{ {e}_{t}})} P(Ot∣statet)=P(statet)P(statet∣Ot)P(Ot)=P(statet)P(statet∣xt)P(xt)
其中 P ( O t ) P(O_t) P(Ot)不变, P ( s t a t e t ) P(stat{ {e}_{t}}) P(statet)是关于状态的先验概率【即观察值(音频特征)和HMM状态对齐之后,某个状态对齐到的总观察值个数/所有观察值个数,所以要强制对齐】
这篇nnet3-compute计算chain前向传播概率(声学模型输出)有做较为详细的介绍计算和为什么。

4 训练过程
H C L G = a s l ( m i n ( r d s ( d e t ( H ′ o m i n ( d e t ( C o m i n ( d e t ( L o G ) ) ) ) ) ) ) ) HCLG = asl(min(rds(det(H' o min(det(C o min(det(L o G)))))))) HCLG=asl(min(rds(det(H′omin(det(Comin(det(LoG))))))))
简写:
中 间 值 = H ′ o m i n ( d e t ( C o m i n ( d e t ( L o G ) ) ) ) 中间值 = H' o min(det(C o min(det(L o G)) )) 中间值=H′omin(det(Comin(det(LoG))))
其他过程涉及到对kaldi中的WFST解码的训练和预测过程,下回再说
Reference
kaldi 源码分析(七) - HCLG 分析
深度神经网络(DNN)
以kaldi中的yesno为例谈谈transition
kaldi中TransitionModel介绍
GMM-HMM理解
kaldi部分训练方法DNN-HMM模型