DolphinDB提供了两种导入MySQL数据的方法:ODBC插件和MySQL插件。我们推荐使用MySQL插件导入MySQL数据,因为它的速度比ODBC导入更快,导入6.5G数据,MySQL插件的速度是ODBC插件的4倍,并且使用MySQL插件无需任何配置,而ODBC插件需要配置数据源。
在使用MySQL插件之前,请先参考DolphinDB安装使用指南安装DolphinDB。
1.下载插件
DolphinDB安装目录/server/plugins/mysql已经包含MySQL插件,用户可以直接使用该插件。如果用户需要自行编译,可以参考https://github.com/dolphindb/DolphinDBPlugin/blob/master/mysql/README_CN.md。
2.加载插件
在GUI中,使用loadPlugin函数加载MySQL插件:
loadPlugin(server_dir+"/plugins/mysql/PluginMySQL.txt")3.接口函数
DolphinDB的MySQL插件提供了以下接口函数:
- connect
- showTables
- extractSchema
- load
- loadEx
我们可以通过以下两种方式调用插件的接口函数:
(1)moduleName::apiFunction。例如,调用MySQL插件的connect方法。
mysql::connect(host, port, user, password, db)(2)use moduleName,然后直接调用接口函数。只要执行一次use语句后,后续调用接口函数都不需要重新执行use函数。因此,我们一般推荐这种调用方法。
use mysql
connect(host, port, user, password, db)3.1 connect
语法
connect(host, port, user, password, db)
参数
host是MySQL服务器的主机名。
port是MySQL服务器的端口号,默认为3306。
user是MySQL服务器中的用户名。
password是与user对应的密码。
db是MySQL中的数据库名称。
详情
创建MySQL连接,返回MySQL的连接句柄。我们建议MySQL用户的Authentication Type为mysql_native_password。
例子
连接本地MySQL服务器中的employees数据库。
conn=connect("127.0.0.1",3306,"root","123456","employees")3.2 showTables
语法
showTables(connection)
参数
connection是connect函数返回的连接句柄。
详情
返回一个DolphinDB类型的数据表,包含MySQL数据库中所有表的名称。
例子
查看employees数据库中的表。
showTables(conn);
Tables_in_employees
current_dept_emp
departments
dept_emp
dept_emp_latest_date
dept_manager
employees
salaries
test_datatypes
titles3.2 extractSchema
语法
extractSchema(connection, tableName)
参数
connection是connect函数返回的连接句柄。
tableName是MySQL数据库中的数据表名称。
详情
返回结果是DolphinDB类型的表。第一列是MySQL数据表中的字段名,第二列是数据导入到DolphinDB后的数据类型,第三列是MySQL中的数据类型。
例子
查看employees表中各列的数据类型。
extractSchema(conn,`employees);
name type MySQL describe type
emp_no LONG int(11)
birth_date DATE date
first_name STRING varchar(14)
last_name STRING varchar(16)
gender SYMBOL enum('M','F')
hire_date DATE date 3.3 load
语法
load(connection, table|query, [schema], [startRow], [rowNum])
参数
connection是connect函数返回的连接句柄。
table是MySQL服务器中的表名。
query是MySQL中的查询语句。
schema是DolphinDB类型的表,它包含两列,第一列是字段名称,第二列是数据类型。它是可选参数。用户可以通过指定该参数来修改数据加载到DolphinDB时的数据类型。
startRow是正整数,表示读取数据的起始行数。它是可选参数,默认值为0,表示从第一条记录开始读取数据。
rowNum是正整数,表示读取的记录行数。它是可选参数,如果没有指定,表示读取所有的数据。如果第二个参数为query,那么startRow和rowNum参数无效。
详情
把MySQL数据加载到DolphinDB的内存表中。
例子
- 把employees表中的所有数据加载到DolphinDB的内存表中。
t=load(conn,"employees");
emp_no birth_date first_name last_name gender hire_date
10,001 1953.09.02 Georgi Facello M 1986.06.26
10,002 1964.06.02 Bezalel Simmel F 1985.11.21
10,003 1959.12.03 Parto Bamford M 1986.08.28
10,004 1954.05.01 Chirstian Koblick M 1986.12.01
10,005 1955.01.21 Kyoichi Maliniak M 1989.09.12
10,006 1953.04.20 Anneke Preusig F 1989.06.02
10,007 1957.05.23 Tzvetan Zielinski F 1989.02.10
10,008 1958.02.19 Saniya Kalloufi M 1994.09.15
10,009 1952.04.19 Sumant Peac F 1985.02.18
10,010 1963.06.01 Duangkaew Piveteau F 1989.08.24
...- 把employees表中的前10行数据加载到DolphinDB的内存表中。
t=load(conn,"select * from employees limit 10");
emp_no birth_date first_name last_name gender hire_date
10,001 1953.09.02 Georgi Facello M 1986.06.26
10,002 1964.06.02 Bezalel Simmel F 1985.11.21
10,003 1959.12.03 Parto Bamford M 1986.08.28
10,004 1954.05.01 Chirstian Koblick M 1986.12.01
10,005 1955.01.21 Kyoichi Maliniak M 1989.09.12
10,006 1953.04.20 Anneke Preusig F 1989.06.02
10,007 1957.05.23 Tzvetan Zielinski F 1989.02.10
10,008 1958.02.19 Saniya Kalloufi M 1994.09.15
10,009 1952.04.19 Sumant Peac F 1985.02.18
10,010 1963.06.01 Duangkaew Piveteau F 1989.08.24- 加载时把last_name的数据类型修改为SYMBOL。
schema=select name,type from extractSchema(conn,`employees)
update schema set type="SYMBOL" where name="last_name"
t=load(conn,"employees",schema)
//查看表t的结构
schema(t);
chunkPath->
partitionColumnIndex->-1
colDefs->
name typeString typeInt
---------- ---------- -------
emp_no LONG 5
birth_date DATE 6
first_name STRING 18
last_name SYMBOL 18
gender SYMBOL 17
hire_date DATE 6 3.4 loadEx
语法
loadEx(connection, dbHandle, tableName, partitionColumns, table|query, [schema], [startRow], [rowNum])
参数
connection是connect函数返回的连接句柄。
dbHandle是DolphinDB的数据库句柄,通常是database函数返回的对象。
tableName是DolphinDB数据库中的表名。
partitionColumns是字符串标量或向量,表示分区列。
table是字符串,表示MySQL服务器中表的名称。
query是MySQL中的查询语句。
schema是DolphinDB类型的表,它包含两列,第一列是字段名称,第二列是数据类型。它是可选参数。用户可以通过指定该参数来修改数据加载到DolphinDB时的数据类型。
startRow是正整数,表示读取数据的起始行数。它是可选参数,默认值为0,表示从第一条记录开始读取数据。
rowNum是正整数,表示读取的记录行数。它是可选参数,如果没有指定,表示读取所有的数据。如果第二个参数为query,那么startRow和rowNum参数无效。
详情
把MySQL中的数据加载到DolphinDB的分区表中。loadEx不支持把数据加载到DolphinDB的顺序分区表中。
例子
把employees表加载到DolphinDB的磁盘VALUE分区表中。
db=database("H:/DolphinDB/Data/mysql",VALUE,`F`M)
pt=loadEx(conn,db,"pt","gender","employees")
select count(*) from loadTable(db,"pt");
count
300,024如果需要把数据加载到内存分区表,只需要把database的路径改为空字符串;如果需要把数据加载到分布式表,只需要把database路径修改为以“dfs://”开头的路径,比如“dfs://mysql”。分布式表需要在集群中才能使用。集群部署请参考单服务器集群部署和多服务器集群部署。
4. 数据类型转换
使用MySQL插件把数据导入到DolphinDB时,会做相应的类型转换。具体转换规则如下表所示:
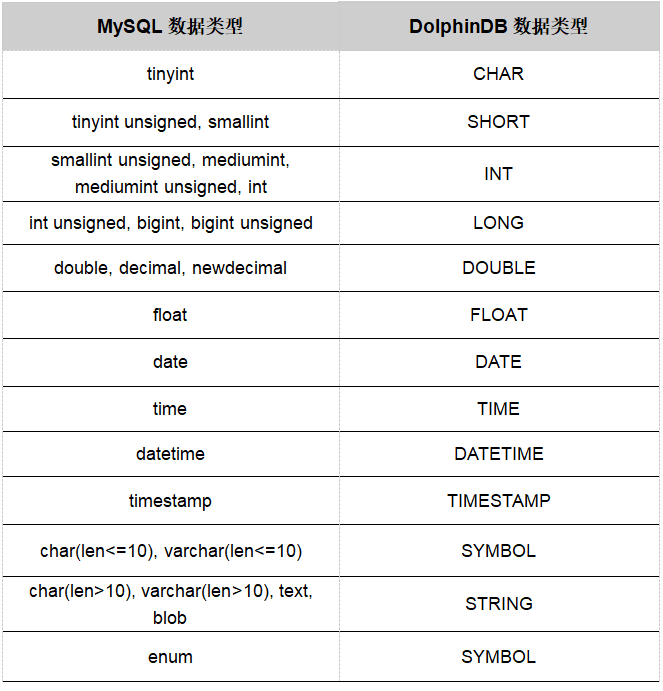
说明:
(1)DolphinDB中的整型(SHORT, INT, LONG)都是有符号的,为了防止溢出,MySQL中的无符号类型在DolphinDB中都会被转换为高一阶的有符号类型。例如,无符号的tinyint转换为short,无符号的smallint转换为short等。目前,MySQL插件不支持64位无符号类型转换。
(2)在DolphinDB中,整型的最小值表示NULL:CHAR类型的-128,SHORT类型的-32,768,INT类型的-2,147,483,648,LONG类型的-9,223,372,036,854,775,808都表示NULL。
(3)对于MySQL中的bigint unsigned类型,默认会转换成DolphinDB的LONG类型。如果出现溢出的情况,需要用户使用schema参数,指定类型为DOUBLE或FLOAT。
(4)MySQL中的char和varchar类型,如果长度小于等于10,会被转换成DolphinDB的SYMBOL类型,如果长度大于10,会被转换成DolphinDB的STRING类型。SYMBOL类型在DolphinDB内部存储为整数,因此数据排序和比较的效率会更高,同时也可以节省存储空间。但是将字符串映射到整数需要时间,映射表也会占用内存。用户可以根据下面的规则来决定某列是否采用SYMBOL类型:如果该字段的值会大量重复出现,使用SYMBOL类型。如金融数据中的股票代码、交易所、合约代码等,物联网数据中的设备编号等都是使用SYMBOL类型的典型场景。
5. 性能测试
我们在普通PC上(16G内存,4核8线程,使用SSD)进行了性能测试。使用的数据集为美国股票市场1990年到2016年的每日报价数据,数据量为6.5G,包含22个字段,50,591,907行记录,在MySQL数据库中磁盘占用为7.2G。使用loadEx函数把数据从MySQL导入到DolphinDB的分区数据库耗时仅160.5秒,读取速度达到了41.4M/s,在 DolphinDB database 中磁盘占用为1.3G。在同样的PC上,由于使用ODBC一次性导入数据会造成MySQL内存不足,因此每次导入100万条数据,总耗时660秒。将同样的数据导入clickhouse耗时171.9秒,读取速度为37.8M/s。DolphinDB在时间序列数据的处理和分区管理上比clickhouse更加方便。
如果既要保证性能,同时友好支持时序数据的各种处理和分布式数据库,那么DolphinDB database将是不二选择。