作者 | CV君
报道 | 我爱计算机视觉(微信id:aicvml)
随着深度学习技术的成熟,设计新的算法在主流的目标检测数据集比如COCO上提升精度已经很难了,但总有一些涨点技巧,比如谷歌前几天公布的 简单粗暴“复制-粘贴”数据增广,简单又有效,让人措不及防。
今天要跟大家介绍一篇新文章 SWA Object Detection ,可能是最简单、计算成本最低、动手成本最低的。
同样的,这篇文章全文无公式、无算法流程图,不改模型结构,不增加模型复杂度、推断时间,也不对数据进行增广。但将其简单应用于主流的目标检测算法,可普遍在COCO数据集上获得 ~1 个AP的精度提升!而且神奇的是原始模型精度越高提升幅度越大。
该文昨天刚公布,作者信息:

作者来自澳大利亚昆士兰科技大学、昆士兰大学。
简单一句话介绍方法:将模型在数据集上多训练几个epochs,将多个epochs得到的checkpoints 进行简单平均,获得最终模型。该方法启发于 Stochastic Weights Averaging(随机权重平均,SWA,来自论文 Averaging weights leads to wider optima and better generalization. UAI, 2018),其本来是为了改进深度学习模型的泛化能力。
SWA理论认为平均多个SGD优化轨迹上的多个模型,最终模型泛化性能更好。如下图:

W1、W2、W3为模型优化过程中不同的checkpoint,SWA认为在其张成的空间中,中心点具有更好的泛化能力。故取checkpoint平均。
问题来了,训练多少个epoch再平均?如何调整学习率?
在SWA原理论中模型再训练时使用固定学习率或者循环余弦退火学习率。
循环余弦退火学习率调整示意图:
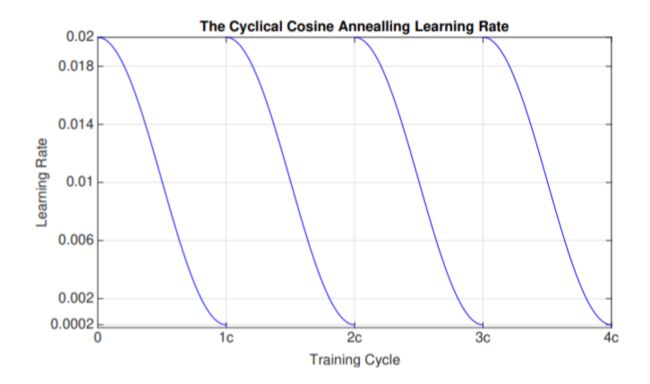
其实很难用理论回答,所以作者的做法很直接,多次实验,看结果总结规律。
作者使用Mask RCNN 在COCO上做了实验,固定学习率和循环余弦退火学习率调整都试了。
请看下表:

获得了很神奇的结果!checkpoints平均后获得了比之前训练路径上所有模型都更好的结果,循环余弦退火学习率调整获得的结果更好,bbox AP 和 mask AP都可以获得超过 1 个AP的提升!而且相比于6个、24个、48个checkpoints的平均,12是一个足够好的数字。
为验证此方法具有通用性,作者在不同的算法上进行验证。
将SWA用于Mask RCNN 与 Faster RCNN上的结果:
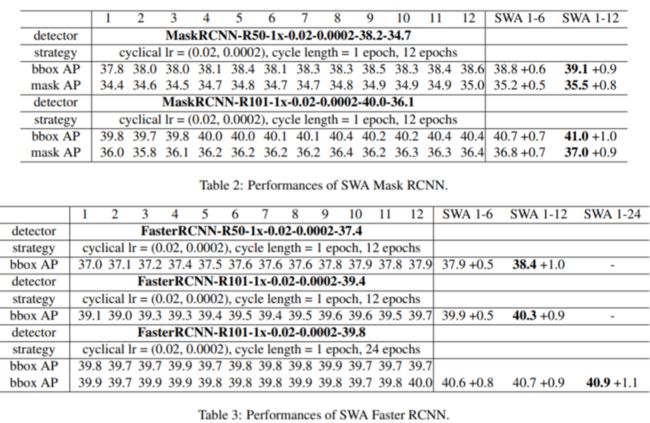
精度都有提升,而对于本身精度更高的Mask RCNN 提升更明显。
将SWA用于RetinaNet 与 FCOS 上的结果:
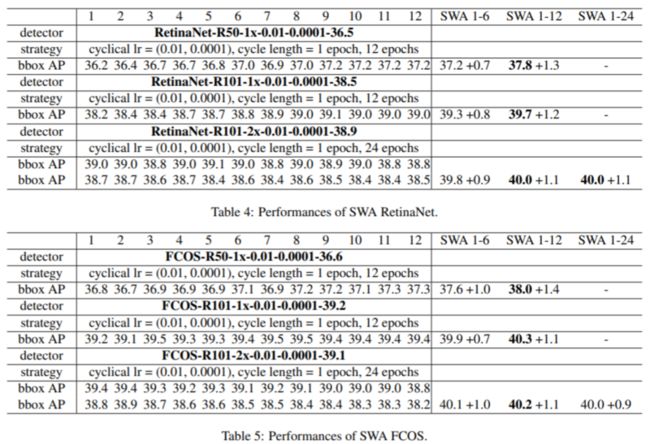
都获得了精度提升,原始模型精度越高,获得的提升越大!
将SWA用于YOLOv3 与 VFNet 上的结果:

提升依然很明显!
下图为Mask RCNN 使用SWA前后推断结果示例:

总结一下简单又神奇的SWA方法:
在传统的使用_lr__ini_和_lr__end_作为起始和结束学习率训练结束后,额外多训练12个epochs,每个epochs学习率由_lr__ini_变化到_lr__end_,最后将这12个checkpoints平均,得到最终的模型。
论文地址:
https://arxiv.org/pdf/2012.12...
代码地址:
https://github.com/hyz-xmaste...\_object\_detection
期待这种简单的抗过拟合方法,能够在其他视觉任务上有效!