python爬取b站视频弹幕并制作词云
用过B站的小伙伴们都知道,B站的弹幕是一绝。 今天我们爬取指定bv号视频下的弹幕,添加到csv文件中并制作成词云。
文章目录
- 一、分析弹幕的接口url地址
- 二、代码编写
-
- 1.引入库
- 2.爬虫类编写
- 运行结果
一、分析弹幕的接口url地址
这里有两个地址可以实现爬取弹幕,一个是有限条的,另一个则是根据日期循环爬取,可以实现所有弹幕的爬取。
案例是冰冰的vlog.001
第一个不需要登录就可以爬取的接口为:
https://comment.bilibili.com/{oid/cid}.xml
我抓包抓了很久也没有找到这样的包,b站现在把弹幕的接口藏得很深…不是很好找,最后是看着别人的博客在移动端的网页js中找到了这样的请求地址。

可以看到返回的结果是一个xml界面,只需要请求这个界面使用xpath对其进行定位就可以很容易的获取到自己想要的数据。
那么我们现在来分析第二个接口:
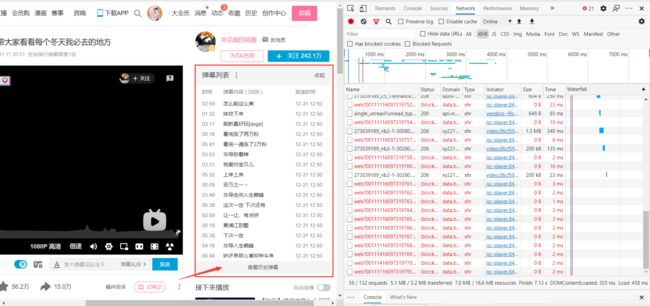
可以看到右侧有一个弹幕历史的功能,我们先把抓包记录清除一下,点击按钮看看有什么新抓到的包:

可以看到这里出现了一个新的请求,内容是这样的:
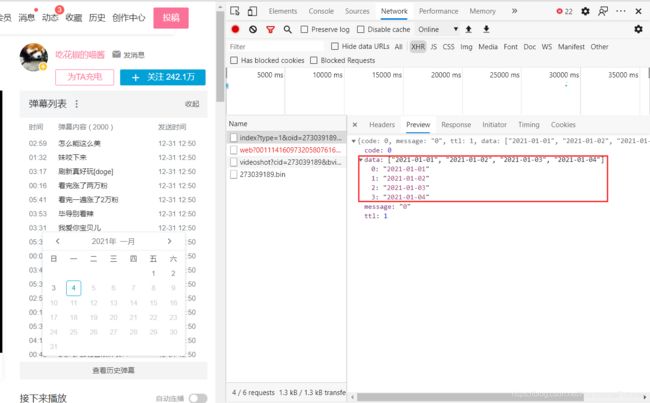
这不就是对应的日期嘛,不用想,请求头中肯定会有对应的月份数据,按月份来分组,达到这样的日历点击效果。果然:
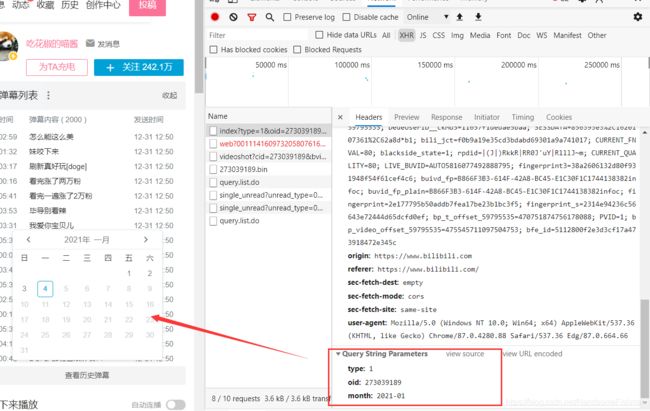
点击十二月后,有了新的请求:

因为这个视频是12-31号发布的,所以十二月只有这一个数据。
点击具体的一天后:

弹幕的数据就出现了:

所以我们只需要请求对应的日期索引(以月份分组),再循环遍历发送请求就好了,这里需要登录,所以我们使用到cookie,接下来看代码编写。
二、代码编写
1.引入库
代码如下:
import requests
from lxml import etree
import pandas as pd
from wordcloud import WordCloud
import jieba
2.爬虫类编写
初始化:
class BarrageSpider:
def __init__(self, bv):
# 需要一个bv号,在接下来的代码中进行替换操作
self.bv = bv
# 不需要登录的弹幕接口地址 只能爬取部分弹幕
self.barrage_url = 'https://comment.bilibili.com/{}.xml'
# 需要登陆的弹幕接口地址 根据日期进行分类 需要循环爬取 最后归总数据
self.date_url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid={}&date={}' # 2021-01-01
# 点击按钮弹出日历的数据接口,这里我们用来作索引
self.index_url = 'https://api.bilibili.com/x/v2/dm/history/index?type=1&oid={}&month={}' # 2021-01
# 在抓包工具中找的一个简洁的请求,里面有我们需要的oid或者是cid
self.bv_url = 'https://api.bilibili.com/x/player/pagelist?bvid=' + bv + '&jsonp=jsonp'
# 不需要登录接口的伪装头
self.comment = {
'referer': 'https://www.bilibili.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 '
}
# 需要登录的伪装头 因为需要登录 ip代理已经没有意义了 这里就不再使用IP代理
self.date_headers = {
"referer": "https://www.bilibili.com/",
"origin": "https://www.bilibili.com",
"cookie": "cookie",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66 "
}
封装函数:
# 从接口返回的json中获取到我们的cid 注: cid = oid
def get_cid(self):
# 定位到数据data中下面的cid
return requests.get(url=self.bv_url, headers=self.comment).json()['data'][0]['cid']
# 解析不需要登录的接口 返回类型是xml文件
def parse_url(self):
# 获取指定视频的cid/oid
cid = self.get_cid()
# 对页面进行伪装请求,这里注意不要转换成text,使用二进制
response = requests.get(url=self.barrage_url.format(cid), headers=self.comment).content
# etree解析
data = etree.HTML(response)
# 定位到所有的d元素
barrage_list = data.xpath('//d')
for barrage in barrage_list:
# 获取d元素的p属性值
info = barrage.xpath('./@p')[0].split(',')
# 获取弹幕内容
content = barrage.xpath('./text()')[0]
item = {
'出现时间': info[0], '弹幕模式': info[1], '字体大小': info[2], '颜色': info[3], '发送时间': info[4], '弹幕池': info[5],
'用户ID': info[6], 'rowID': info[7], '内容': content}
# 因为这只是一部分弹幕 所以就没有进行持久化存储 没有必要
print(item)
# 循环爬取所有弹幕 需要传入month的数据 根据视频发布的日期到现在的所有月份
def parse_date_url(self, month):
# 存放爬到的数据
result = []
# 获取视频的oid
oid = self.get_cid()
# 获取日期索引
date_by_month = requests.get(url=self.index_url.format(oid, month), headers=self.date_headers).json()['data']
# 根据日期索引循环请求
for day in date_by_month:
# 注意还是二进制文件
date_page = requests.get(url=self.date_url.format(oid, day), headers=self.date_headers).content
date_data = etree.HTML(date_page)
# 解析到到所有的d元素
barrage_list = date_data.xpath('//d')
# 循环解析数据
for barrage in barrage_list:
# 获取d元素的p属性值
things = barrage.xpath('./@p')[0].split(',')
# 获取弹幕内容 并去掉所有空格
content = barrage.xpath('./text()')[0].replace(" ", "")
item = {
'出现时间': things[0], '弹幕模式': things[1], '字体大小': things[2], '颜色': things[3], '发送时间': things[4],
'弹幕池': things[5],
'用户ID': things[6], 'rowID': things[7], '内容': content}
result.append(item)
# 返回封装好的数据
return result
# 舍友指导下的一行代码生成词云 编译器自动格式化了 本质还是一行代码
def wordCloud(self):
WordCloud(font_path="C:/Windows/Fonts/simfang.ttf", background_color='white', scale=16).generate(" ".join(
[c for c in jieba.cut("".join(str((pd.read_csv('{}弹幕池数据集.csv'.format(self.bv))['内容']).tolist()))) if len(c) > 1])).to_file(
"{}词云.png".format(self.bv))
主函数调用:
if __name__ == '__main__':
# 输入指定的视频bv号
bv_id = input('输入视频对应的bv号:')
# new一个对象
spider = BarrageSpider(bv_id)
# 请求今年1月和去年12月的数据 并合并数据
one = spider.parse_date_url('2021-01')
two = spider.parse_date_url('2020-12')
one.extend(two)
# 数据格式化处理 并输出csv格式文件
data = pd.DataFrame(one)
data.drop_duplicates(subset=['rowID'], keep='first')
# 字符集编码需要为utf-8-sig 不然会乱码
data.to_csv('{}弹幕池数据集.csv'.format(bv_id), index=False, encoding='utf-8-sig')
# 生成词云
spider.wordCloud()
运行结果

可以看到有5000条数据。
词云如图:
注:案例仅供学习