数据结构第10章 排序
文章目录
- 插入排序
-
- 直接插入排序
-
- 时空复杂度和分析
- 希尔(Shell)排序
-
- 时空复杂度和分析
- 交换排序
-
- 冒泡排序
-
- 时空复杂度和分析
- 快速排序
-
- 时空复杂度和分析
- 选择排序
-
- 简单选择排序(或称直接选择排序)
-
- 时空复杂度和分析
- 树形选择排序(锦标赛排序)
- 堆排序(Heap Sort)
- 堆的概念
-
- 堆排序流程:
- 筛选或调整算法
- 无序序列建成一个初始堆
- 堆排序算法
- 时空复杂度和分析
- 归并排序
-
- 2-路归并排序
-
- 时空复杂度和分析
- 排序小结
-
- 排序算法选择规则
插入排序
每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子表中的适当位置,直到全部记录插入完成为止。
直接插入排序
整个排序过程为n-1趟插入,即先将序列中第1个记录看成是一个有序子序列,然后从第2个记录开始,逐个进行插入,直至整个序列有序。
void InsertSort(SqList &L)
{
int i,j;
for(i=2;i<=L.length; i++)
{
//将L.R[i]插入有序子表
if( L.R[i].key<L.R[i-1].key)
{
L.R[0]=L.R[i]; // 复制为哨兵
j = i-1;
do{
L.R[j+1]=L.R[j]; // 记录后移
j--;
}while(L.R[0].key>=L.R[j].key))
L.R[j+1]=L.R[0]; //插入到正确位置
}
}
}
时空复杂度和分析
最好的情况(关键字在记录序列中正序):
“比较”的次数: ∑ i = 1 n − 1 1 = n − 1 \sum_{i=1}^{n-1} 1=n-1 ∑i=1n−11=n−1
“移动”的次数:0
最坏的情况(关键字在记录序列中逆序有序):
“比较”的次数: ∑ i = 1 n − 1 i = n ( n − 1 ) / 2 \sum_{i=1}^{n-1} i=n(n-1)/2 ∑i=1n−1i=n(n−1)/2
“移动”的次数: ∑ i = 1 n − 1 ( i + 2 ) = ( n + 4 ) ( n − 1 ) / 2 \sum_{i=1}^{n-1} (i+2)=(n+4)(n-1)/2 ∑i=1n−1(i+2)=(n+4)(n−1)/2
- 改进:在插入第 i(i>1)个记录时,前面的 i-1 个记录已经排好序,则在寻找插入位置时,可以用二分查找来代替顺序查找,从而减少比较次数。这就是折半插入排序。
- 直接插入排序在基本有序时,效率较高
- 在待排序的记录个数较少时,效率较高
希尔(Shell)排序
先将整个待排记录序列分割成若干子序列,各个子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
将相距d个位置的记录分为一组, n 个记录被分成 d 个子序列,d 称为增量,增量d的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为 1。所以希尔排序也称为缩小增量排序。

时空复杂度和分析
时间复杂度平均情况: O ( n 1.3 ) O(n^{1.3}) O(n1.3)
如何选择最佳d序列,目前尚未解决;但最后一个增量值必须为1
不宜在链式存储结构上实现
交换排序
冒泡排序
void Bubble-sort(SqList &L)
{
int i, j, swap; // 当swap为0则停止排序
for ( i=1; i<L.length; i++) // i 表示趟数,最多n-1趟
{
swap=0; // 开始时元素未交换
for ( j=1; j<=L.length-i; j++)
if (L.R[j].key>L.R[j+1].key) // 发生逆序
{
L.R[0]=L.R[j]; L.R[j]=L.R[j+1]; L.R[j+1]=L.R[0];
swap=1;
} // 交换,并标记发生了交换
if(swap==0) break;
}
}
时空复杂度和分析
最好的情况(关键字在记录序列中正序):
“比较”的次数: ∑ i = 1 n − 1 1 = n − 1 \sum_{i=1}^{n-1} 1=n-1 ∑i=1n−11=n−1
“移动”的次数:0
最坏的情况(关键字在记录序列中逆序有序):
“比较”的次数: ∑ i = 1 n − 1 i = n ( n − 1 ) / 2 \sum_{i=1}^{n-1} i=n(n-1)/2 ∑i=1n−1i=n(n−1)/2
“移动”的次数: ∑ i = 1 n − 2 3 ( n − i − 1 ) = 3 n ( n − 1 ) / 2 \sum_{i=1}^{n-2}3 (n-i-1)=3n(n-1)/2 ∑i=1n−23(n−i−1)=3n(n−1)/2
改进:在冒泡排序中,记录的比较和移动是在相邻单元中进行的,记录每次交换只能上移或下移一个单元,因而总的比较次数和移动次数较多。
快速排序
- 快速排序首先选一个基准值(即比较的基准),每趟使表的第1个元素放入适当位置(归位),将表一分为二,前一部分记录的关键码均小于或等于基准值,后一部分记录的关键码均大于或等于基准值对;
- 子表按递归方式继续这种划分,直至划分的子表长为0或1(递归出口)。
void Quick_Sort(SqList &L,int s,int t) /* 对R[s]到R[t]的元素进行排序 */
{
if (s<t) //至少有两个元素
{
int i=Partition(L,s,t);
Quick_Sort(L,s,i-1);
Quick_Sort(L,i+1,t);
}
}
int Partition(SqList &L,int low,int high)
{
L.R[0]= L.R[low]; /* 暂存基准值元素到R[0]中*/
while(low<high) /* 从表的两端交替地向中间扫描 */
{
while( low<high&&L.R[high].key>=L.R[0].key )high--;
if(low<high) {
L.R[low]= L.R[high]; low++; }
while( low<high&&L.R[low].key<L.R[0].key ) low++;
if (low<high) {
L.R[high]= L.R[low]; high--; }
}
L.R[low]= L.R[0]; /* 将基准值元素放到其最终位置 */
return low; /* 返回基准值元素所在的位置*/
}
时空复杂度和分析
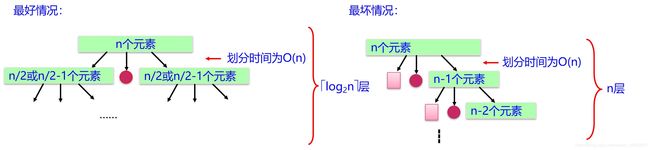
最好情况时间复杂度为 O ( n log 2 n ) O(n\log_2n) O(nlog2n),空间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n)。
最坏情况时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( n ) O(n) O(n)。
平均时间复杂度为 O ( n log 2 n ) O(n\log_2n) O(nlog2n)。
稳定性:不稳定。
选择排序
简单选择排序(或称直接选择排序)
每一趟在后面 n-i+1个中选出关键码最小的对象, 作为有序序列的第 i 个记录。
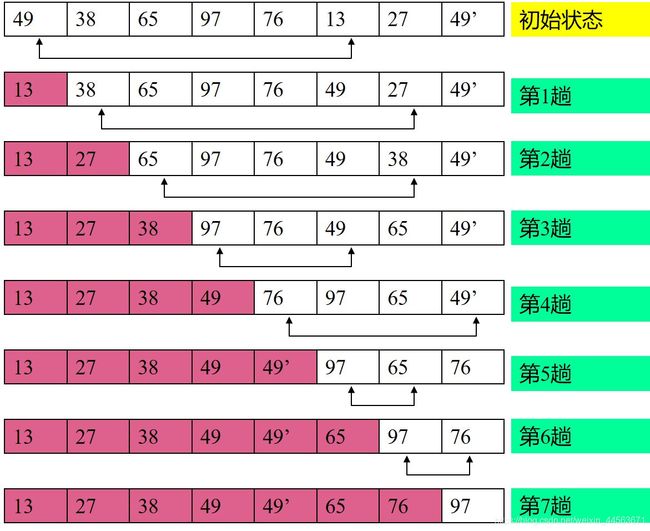
时空复杂度和分析
最好情况时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
最坏情况时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
空间复杂度为 O ( 1 ) O(1) O(1)。
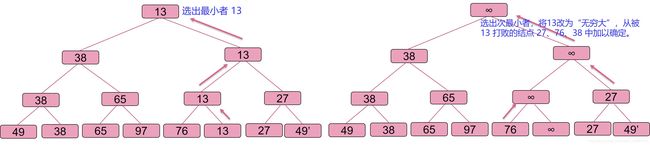
树形选择排序(锦标赛排序)
简单选择排序慢的原因?
用直接选择排序从n个记录中选出关键字值最小的记录要做n-1次比较,然后从其余n-1个记录中选出最小者要作n-2次比较。显然,相邻两趟中某些比较是重复的。
树形选择排序:首先对n个关键字进行两两比较,然后在其⌈/2⌉个较小者之间再进行两两比较,如此重复,直至选出最小关键字为止。这个过程可用一棵有n个叶结点的完全二叉树表示。
堆排序(Heap Sort)
堆的概念
n个元素的序列 { k 1 , k 2 , … … , k n } \{ k_1, k_2 ,…… , k_n \} { k1,k2,……,kn},当且仅当满足下面条件(以大根堆为例)称之为堆。
{ k i ≥ k 2 i k i ≥ k 2 i + 1 \left\{\begin{array}{l} k _{ i } \geq k _{2 i } \\ k _{ i } \geq k _{2 i +1}\end{array}\right. { ki≥k2iki≥k2i+1
( i = 1 , 2 , … , ⌊ n / 2 ⌋ ) (i=1,2, \ldots,\lfloor n / 2\rfloor) (i=1,2,…,⌊n/2⌋)
若将此关键字序列按顺序组成一棵完全二叉树,则堆可以如下定义:
或每个结点的值都大于或等于其左右孩子结点的值(称为大根堆或大顶堆)。
堆排序流程:
- 将无序序列建成一个堆;
- 输出堆顶的最小(大)值;
- 使剩余的n-1个元素又调整成一个堆,返回步骤2;
筛选或调整算法
对一棵左右子树均为堆的完全二叉树,“调整”根结点使整个二叉树也成为一个堆。
- s指向当前根节点,将根节点存入暂存区tmp;
- i指向s孩子中key较大的;
- 若tmp.key>=i.key,s=tmp,退出;否则s=i,返回步骤2。
void HeapAdjust(SqList &L,int s,int m)
{
//假设R[s+1..m]已经是堆,将R[s..m]调整为以R[s]为根的大根堆
RecType tmp=L.R[s];
for(int i=2*s ; i<=m ; i*=2) //沿key较大的孩子结点向下筛选
{
if(i<m && L.R[i].key<L.R[i+1].key) i++; //i为key较大的记录的下标
if( tmp.key>=L.R[i].key )
break;//双亲大:不再调整,temp应插在位置s上
L.R[s]=L.R[i];//将R[j]调整到双亲结点位置上
s=i; //修改s值,以便继续向下筛选
}
L.R[s]=tmp; //插入
}
无序序列建成一个初始堆
for (i=n/2;i>=1;i--)
HeapAdjust(L.R,i,n);

堆排序算法
void HeapSort(SqList &L)
{
int i; RecType tmp;
for (i=n/2;i>=1;i--) //循环建立初始堆
HeapAdjust(L.R,i,n);
for (i=n; i>=2; i--) //进行n-1次循环,完成堆排序
{
temp=L.R[1]; //堆顶归位,R[1] R[i]
L.R[1]=L.R[i];
L.R[i]=tmp;
HeapAdjust(L.R,1,i-1);//调整剩余记录,筛选R[1]结点,得到i-1个结点的堆
}
}
时空复杂度和分析
设有n个记录的初始序列对应的完全二叉树的深度为 h = ⌊ log 2 n ⌋ + 1 h =\left\lfloor\log _{2} n\right\rfloor+1 h=⌊log2n⌋+1,每个非终端结点都要自上而下进行“筛选”。由于第i层上的结点数小于等于 2 i − 1 2^{i-1} 2i−1,且第i层结点最大下移的深度为h-i,每下移一层要做两次比较,所以建初堆时关键字总的比较次数为
∑ i = h − 1 1 2 i − 1 ⋅ 2 ( h − i ) ≤ 4 n \sum_{i=h-1}^{1} 2^{i-1} \cdot 2(h-i) \leq 4 n ∑i=h−112i−1⋅2(h−i)≤4n
调整“堆顶”要做n-1 次“筛选”,每次“筛选”都要将根结点下移到合适的位置,比较2(h-1)次。n 个关键字的完全二叉树的深度为 ⌊ log 2 n ⌋ + 1 \lfloor \log_2n\rfloor+1 ⌊log2n⌋+1,则重建堆时关键字总的比较次数不超过:
2 ( log 2 ( n − 1 ) ⌋ + ⌊ log 2 ( n − 2 ) ⌋ + … + log 2 2 ) < 2 n ( log 2 n ⌋ ) \left.\left.2\left(\log _{2}( n -1)\right\rfloor+\left\lfloor\log _{2}( n -2)\right\rfloor+\ldots+\log _{2} 2\right)<2 n \left(\log _{2} n \right\rfloor\right) 2(log2(n−1)⌋+⌊log2(n−2)⌋+…+log22)<2n(log2n⌋)
因此,堆排序的时间复杂度为 O ( n log 2 n ) O(n\log_2n) O(nlog2n)。
空间复杂度为 O ( 1 ) O(1) O(1)。
稳定性:不稳定。
归并排序
2-路归并排序
- 初始序列看成n个有序子序列,每个子序列长度为1,两两合并,得到 ⌊ n / 2 ⌋ \lfloor n/2\rfloor ⌊n/2⌋ 个长度为2或1的有序子序列;
- 再两两合并,重复直至得到一个长度为n的有序序列为止。
void Merge( SqList &L,int low,int mid,int high)
{
SqList L1; L1.length = high-low+1;
int i=low, j=mid+1, k=0;//k是L1.R的下标,i、j分别为第1、2路的下标
while ( i<=mid && j<=high )
if (L.R[i].key<=L.R[j].key) //将关键字值小的记录放入L1中
{
L1.R[k]=L.R[i]; i++;k++; }
else {
L1.R[k]=L.R[j]; j++;k++; }
while (i<=mid) //如果第1路还有剩余记录,将其余下部分复制到L1
{
L1.R[k]=L.R[i]; i++;k++; }
while (j<=high) //如果第2路还有剩余记录,将其余下部分复制到L1
{
L1.R[k]=L.R[j]; j++;k++; }
for (k=0,i=low;i<=high; k++,i++)
L.R[i]=L1.R[k];//将归并后的记录复制回L中
}
void MergePass(SqList &L,int m)
{
for (int i=0;i+2*m<L.length;i=i+2*m) //归并长为m的两相邻子表
Merge(L,i,i+m-1,i+2*m-1);
if (i+m-1<L.length) //还剩下两个子表,第1段长度为m,第2段长度小于m
Merge(L,i,i+m-1,L.length-1); //归并剩余的这两个子表
}
时空复杂度和分析
最好情况时间复杂度为 O ( n log 2 n ) O(n\log_2n) O(nlog2n)。
最坏情况时间复杂度为 O ( n log 2 n ) O(n\log_2n) O(nlog2n)。
空间复杂度为 O ( n ) O(n) O(n)。
稳定性:稳定。
排序小结
为避免顺序存储时大量移动记录的时间开销,可考虑用链表作为存储结构:直接插入排序、归并排序、基数排序
不宜采用链表作为存储结构:折半插入排序、希尔排序、快速排序、堆排序
排序算法选择规则
- n较大时
(1)分布随机,稳定性不做要求,则采用快速排序
(2)内存允许,要求排序稳定时,则采用归并排序
(3)可能会出现正序或逆序,稳定性不做要求,则采用堆排序或归并排序 - n较小时
(1)基本有序,则采用直接插入排序
(2)分布随机,则采用简单选择排序,若排序码不接近逆序,也可以采用直接插入排序