数据库系统原理 15章 Concurrency Control
Lock-Based Protocols
锁协议是用来进行并发控制的协议。有两种锁:排他锁and共享锁。A lock is a mechanism to control concurrent access to a data item. Data items can be locked in two modes:
如果当前数据项获得了排他锁,则当前指令既可以对数据项进行读操作也可以进行写操作。exclusive(X) mode. Data item can be both read as well as written. X-lock is requested using lock-X instruction.
如果当前数据项获得的是共享锁,则只可以对数据项进行读操作。shared(S) mode. Data item can only be read. S-lock is requested using lock-S instruction.
通过加排他锁和共享锁可以进行并发控制,在加锁的过程中也可以进行锁的转换。事务在进行读和写的操作之前必须有读和写的操作的申请。只有在获得相应的锁之后才能对数据项进行相应的读和写操作。

最后一个应该是false,读写冲突啊。
A transaction may be granted a lock on an item if the requested lock is compatible with locks already held on the item by other transactions.
Any number of transactions can be hold shared locks on an item.如果申请的是共享锁,其他事务仍然可以申请共享锁。
but if any transaction holds an exclusive on the item no other transaction may hold any lock on the item.但是如果申请的是排他锁,其他所有事务不能申请任何锁 。
如果此时其他事务需要对当前数据项申请锁就只能排队等待。

在上例中对事务加锁可以保证事务是串行的。但是其他情况加锁并不一定能够保证可串行化。比如在A 和B之间有其他的操作,这个时候就可能对A和B的总和有一个改变,导致不一致。Locking as above is not sufficient to guarantee serializability -- if A and B get updated in-between the read of A and B, the displayed sum would be wrong.
但是可以保证在读的过程中没有其他事务再进行写。
A locking protocol is a set of rules followed by all transactions while requesting and releasing locks. Locking protocols restrict the set of possible schedules.锁协议就是一系列用来保证可串行化调度的机制
出现的问题:
1. deadlock
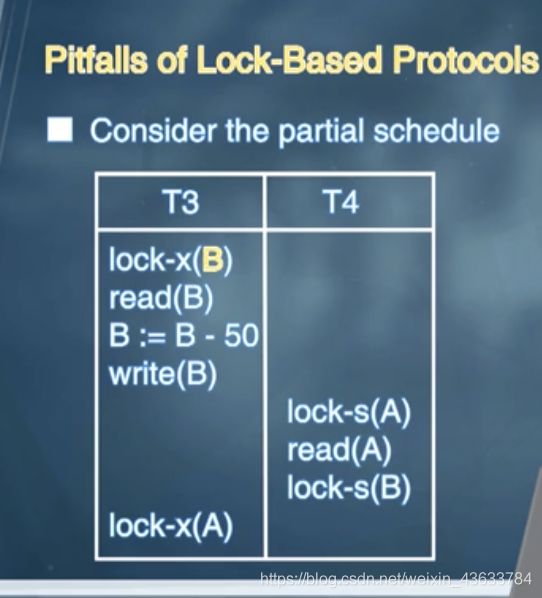
T3、T4互相等待产生死锁。

实际上在操作的时候产生deadlock是不可避免的,但是产生deadlock也要比在操作的时候发生读写错误要好,可以利用deadlock去减少数据不一致的现象的发生。(deadlock比较容易解决)

等待了一段时间之后可以对事务进行rollback,重新执行可以防止deadlock。
2. starvation
The potential for deadlock exists in most locking protocols. Deadlocks are a necessary evil.
Starvation is also possible if concurrency control manager is badly designed.
如果一个数据项拥有了共享锁而此时有事务申请排他锁,但是不可以,同时又不断有事务申请共享锁,那么申请排他锁的那个事务就一直等待 end with starvation.
The Two-Phase Locking Protocal
This is a protocol which ensures conflict-serializable schedules.这个协议可以保证冲突可串行化。
The protocol assures serializability. It can be proved that the transactions can be serialized in the order of their lock points.
两阶段锁协议就是保证冲突可串行化的机制。
Phase 1: Growing Phase 上升阶段
只可以对事务进行加锁操作,不能释放
- Transaction may obtain locks
- Transaction may not release locks
Phase 2: Shrinking Phase 下降阶段
只可以进行释放锁的操作,不能加锁
- Transaction may release locks
- Transaction may not obtain locks
Strict two-phase locking
两阶段锁协议仍旧不能避免死锁的发生。Two-phase locking does not ensure freedom from deadlocks.
Cascading roll-back is possible under two-phase locking. To avoid this, follow a modified protocol called strict two-phase locking. Here a transaction must hold all its exclusive locks till it commits/aborts.
可以通过检测两个事务的时间,可以同时回滚两个事务保持一致性。但是正常的两阶段锁无法避免级联回滚的state,所以出现了严格两阶段锁。当前事务在没有提交或者回滚之前不能释放排他锁。
The Two-Phase Locking Protocol
Rigorous two-phase locking(强两阶段锁) is even stricter: here all locks are held till commit/abort. In this protocol transaction can be serialized in the order in which they commit.
当任何事务提交或回滚之前,不能够释放任何的锁。
强两阶段锁既可以保证事务是可串行化的,又可以保证事务不会出现级联回滚。
对于一个调度来讲即使没有使用两阶段锁,也可以是冲突可串行化的。
在进行冲突可串行化判别的时候可能需要额外的信息。比如和当前调度相关的语义的信息。比如说如果增加的是特定数额而不是百分比的话就没什么影响。
However, in the absence of extra information(e.g., ordering of access to data), two-phase locking is needed for conflict serializability in the following sense:
Given a transaction TI that does not follow two-phase locking, we can find a transaction Tjthat uses two
所以在判定的时候要注意不是满足了某些条件就一定是某样东西,不满足就一定不是什么。是有一定的条件在里面的。

第一阶段只能将共享锁转换为排他锁,不能释放,向上转换。
第二阶段可以把排他锁转换为共享锁,进行向下转换。
在上升阶段只能申请锁;在下降阶段只能释放锁。
关于两阶段锁协议,了解何时加锁,解锁;如何进行锁的转换;以及介绍了严格两阶段锁和强两阶段锁的定义。
Implementation of Locking
锁的实现。
事务在执行的过程中对于事务的读和写操作并没有显式的对数据项进行读或者写操作。
数据库底层对于读操作如何进行加锁:

只有加了共享锁才能对数据项进行读操作。
看当前的数据项上是否有,如果有锁可以直接进行读操作。当前事务是否有其他的操作加了排他锁,如果加了排他锁需要进行等待,否则的话加上一个共享锁然后进行读取操作。
数据库底层对于写操作如何进行加锁:
对数据项进行写操作的时候需要对数据项上面加上排他锁。

如果要对数据项进行写操作的话如果拥有了排他锁可以直接对数据项进行写操作,如果没有排他锁的话,进行等待,等其他事务的锁都解除之后才能在数据项上加排他锁。

在对所有数据项操作完毕之后才能对数据项进行解锁。
所有的释放都要在事务提交/abort之后。
Lock manager
锁管理器:在数据库中对数据项进行加锁和解锁的管理机制,是由两个完全分开的过程组成的,向事务发送消息and接收消息——进行加锁和解锁的两个操作。A lock manager can be implemented as a separate process to which transactions send lock and unlock requests.在加锁阶段只能进行加锁,在解锁阶段只能进行解锁。

当发生两个事务对数据项进行申请的时候,可能会存在申请并保持的状态,发生死锁。在这种状态下,需要进行回滚。死锁的发生是与时间有关的错误,打乱时间就可能避免死锁。
所有请求的事务都需要去等待,等待锁管理器进行回复。任何一个事务对于数据项进行读或写的操作之前都必须经过锁管理器对于锁的分配。
所有的事务在进行操作的时候都需要进行排队等待。一个解锁的操作往往会对应其他锁的授予。(解锁操作往往对应于其他事务的加锁请求)
锁管理器实现的过程主要是通过一个lock table(锁表),类似链表的结构。The lock manager maintains a datastructure called a lock table to record granted locks and pending requests
锁表通常是以被加锁的数据项的名字来命名的结构。以请求到达的次序进行排列。
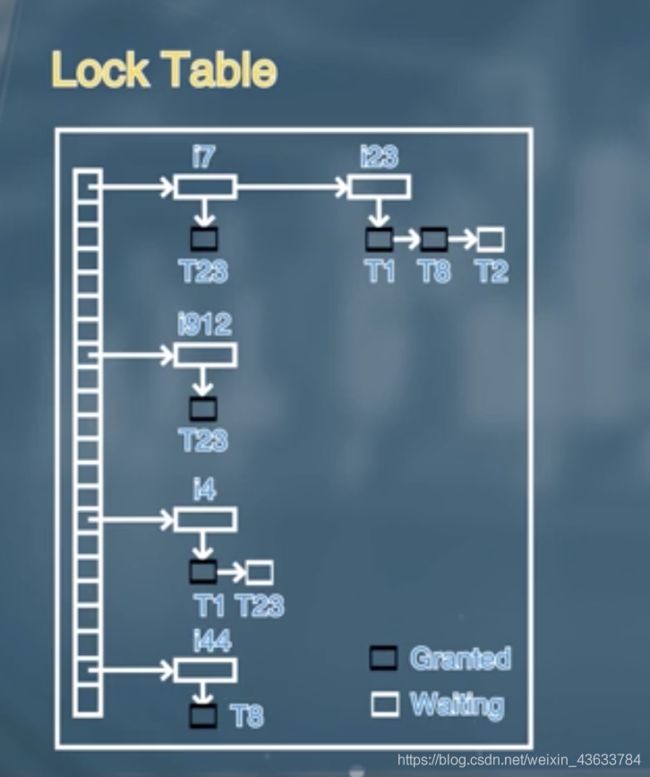
由哪个事务提出的请求以及对数据项提出什么样的锁(对数据项进行读还是写,排他锁还是共享锁)
黑色的框框表示授予锁,白色的框框表示要等待。
如果之前的事务对数据项有排他锁,而当前事务对数据项既有读又有写,可以先读,写的锁进行等待。

当一个事务执行结束之后要对当前的数据项进行解锁操作。If transaction aborts, all waiting or granted requests of the transaction are deleted.
当前的算法保证了没有饿死的现象。lock manager may keep a list of locks held by each transaction, to implement this efficiently.但是不能避免死锁。
“先来先服务”
Multiple Granularity
多粒度锁,某一个事务要对整个数据库进行操作,如果按照原来的操作,就要对每个数据项进行加锁和解锁的操作,这样增加了加锁和解锁的操作时间。
是否有这样的方式,可以对数据库只加一个锁,就可以完成将数据库作为一个整体进行操作的方式。或者是只对一个文件或者一个表进行加锁。
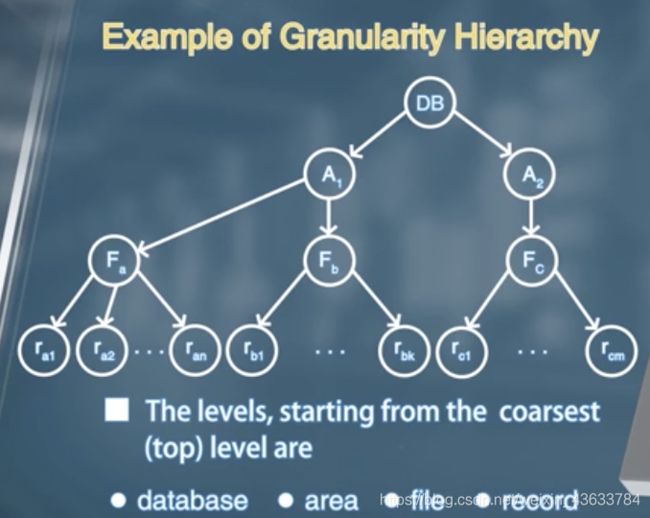
允许加多种粒度的锁。Allow data items to be of various sizes, and define a hierarchy of data granularities, where the small granularities are nested within larger ones.
表、行、文件、数据项。。。
可以将这种层次关系理解成一种树形结构。Can be represented graphically as a tree(but don't confuse with tree-locking protocol
当事务对一个结点进行加共享锁或者排他锁的时候,对其后代结点可以同时加锁。
锁的粒度分类:
细粒度锁——叶结点进行加锁(要分别对每个数据项进行加锁,加锁代价高),在树形结构的底层。

粗粒度锁——根结点加锁(加锁代价低、并发力度低、当一个事务对数据库进行加锁的时候对于数据库的其他访问操作就要等待,对数据库的访问是串行访问)
最顶层是DB级别的锁
然后是Area,域级别的锁
然后是File级别的锁。
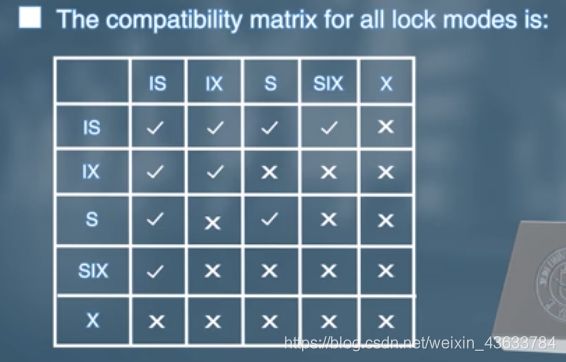
Intention Lock Modes(意向锁)
3种:

- 共享型意向锁:在树的较低层加共享锁。
- 排他型意向锁:在树的较低层(不仅对该结点加锁,还要对以该结点为根的子树上的所有结点都加上锁)加排他锁或共享锁,对于该子树上的更低的结点都加上显式的排他锁或共享锁。
- 共享排他意向锁:当前根结点加共享锁,在当前根结点的子结点加排他锁。
- 加意向锁的概念是在加共享锁或者排他锁之前先加意向锁,想要对它加锁的锁。(可能是告诉别人后面会加锁)
兼容矩阵
读和读相容,读和写、写和写不相容。
Multiple Granularity Locking Scheme
一个事务可以对一个结点加锁,需要满足以下规则:
- 必须要判断是否满足相容性矩阵
- 如果要对Q进行操作,必须要对Q的根结点加意向锁(任意类型的意向锁)
- 当对父结点拥有了相应的共享意向锁或者是排他意向锁的时候才可以对Q加相应的共享锁
- 当对父结点拥有了相应的排他意向锁或共享排他意向锁的时候才可以对Q加相应的排他锁
- 当事务没有解锁操作的时候可以对事务继续进行加锁操作
- 当事务对当前结点的任何一个子结点都么有锁的时候可以对当前结点进行解锁操作
自顶向下加锁、自底向上解锁
Deadlock Handling
死锁处理
与时间有关的错误

对于死锁的预防策略使用的比较少。
常见的死锁预防的方法(More Deadlock Prevention Strategies)
1. 时间戳
(通过事务的抢占来进行事务的rollback)
- 非抢占式
事务Ti所申请的数据项被Tj所占有的时候去比较二者的时间戳,事务开始执行的时间,如果Ti的执行时间比Tj早,那么Ti就等待,如果比Tj晚,rollback. Ti.
【缺点:一个事务被rollback多次】 - 抢占式
事务Ti所申请的数据项被Tj所占有的时候去比较二者的时间戳,如果Ti的时间戳大于Tj的话,等待;如果小于rollback. Tj.
【比非抢占式的rollback次数可能较少】
一个事务所申请的数据项被另一个事务所占有的时候,只要rollback任何一个数据项即可。
Both in wait-die and in wound-wait schemes, a rolled back transactions is restarted with its original timestamp. Older transactions thus have precedence over newer ones, and starvation is hence avoided.如果一个事务重启之后,会保持原有的时间戳。
根据时间戳可以定义老的事务比新的事务有更高的优先级,保证事务不会被饿死。
超时机制:事务在等待的时候,给定一个等待的时间,当事务超时的时候rollback事务并重启。a transaction waits for a lock only for a specified amount of time. After that, the wait times out and the transaction is rolled back.也是防止饿死,一个事务不能一直等待,超时重启。
所有的方式都没有一个完全避免死锁的方式,使用超时机制的时候,等待时间的确定也不容易。
Deadlock Detection
死锁检测and恢复
对于死锁的预防的算法并不能完全避免死锁的产生。
在DB中死锁检测的算法是周期性进行的,来判断DB中是否有死锁产生,如果有死锁产生则必须进行处理。
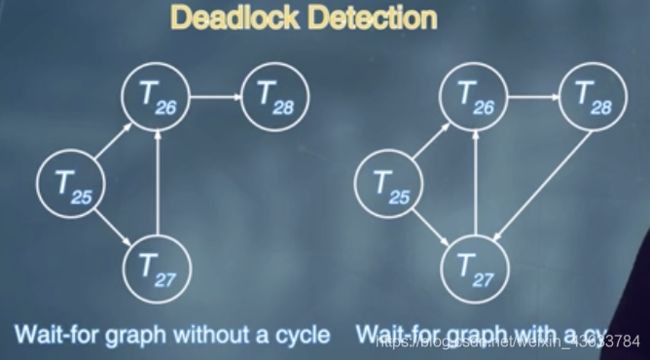
Wait-for graph
G = (V, E)
顶点V是数据库中的所有事务,边E的话是事务之间的执行次序。如果等待图中有一个Ti指向Tj则表明当前Ti有一个正在等待的数据项正在等待Tj的释放。
如果有一个上面的等待关系,就将这条有向边添加到对应的wait-for graph中,如果上面的等待关系消失,则将wait-for graph中的有向边删除。
等待图是根据Ti和Tj对于数据项的申请状态进行划分的。
当wait-for graph中出现环路的时候,系统存在死锁,此时该环路中的每个结点都处于死锁状态。Must invoke a deadlock-detection algorithm periodically to look for cycles.必须要有一个能够定期进行死锁检测的算法进行查看。
Deadlock Recovery
死锁恢复算法
rollback一个或多个事务,就可以打破死锁。
Rollback:
通常选择代价最小的事务进行回滚,一个事务已经执行很久了,rollback的代价就比较大。通过判断一个事务已经执行的时间和事务还需多少时间能够执行完成来判断是否对当前事务进行rollback。一旦决定了rollback当前事务就要决定当前事务需要rollback多远。rollback的时候可以对事务进行全部rollback,也可以对事务进行部分rollback。rollback的时候也可以找到接触到死锁的那个点,也就是从哪个点开始进入到死锁,从该点之后进行rollback,该点之前进行保持,但是这样的有效的部分rollback的代价比较大。所以真正在数据库中使用的时候total rollback使用的比较多
Starvation
两个事务发生死锁,某一个代价比较小的事务进行rollback了,而下一次进入的时候可能还是进入到死锁状态,再次rollback,一个事务被多次rollback的现象就是starvation。所以要保证但前的某一个牺牲者的牺牲次数是有限的才能保证不会产生饿死现象。
method:在rollback代价中添加rollback 次数。