使用Pandas创建数据透视表
本文转载自:蓝鲸的网站分析笔记
原文链接:使用Pandas创建数据透视表
目录
- pandas.pivot_table()
- 创建简单的数据透视表
- 增加一个行维度(index)
- 增加一个值变量(value)
- 更改数值汇总方式
- 增加数值汇总方式
- 增加一个列维度(columns)
- 增加多个列维度
- 增加数据汇总值
数据透视表是Excel中最常用的数据汇总工具,它可以根据一个或多个制定的维度对数据进行聚合。在python中同样可以通过pandas.pivot_table函数来实现这些功能。本篇文章将介绍 pandas.pivot_table函数与Excel数据透视表之间的联系,以及具体的使用方法。文章中的数据源来自Lending Club 2017-2011年的公开数据。

pandas数据透视表函数
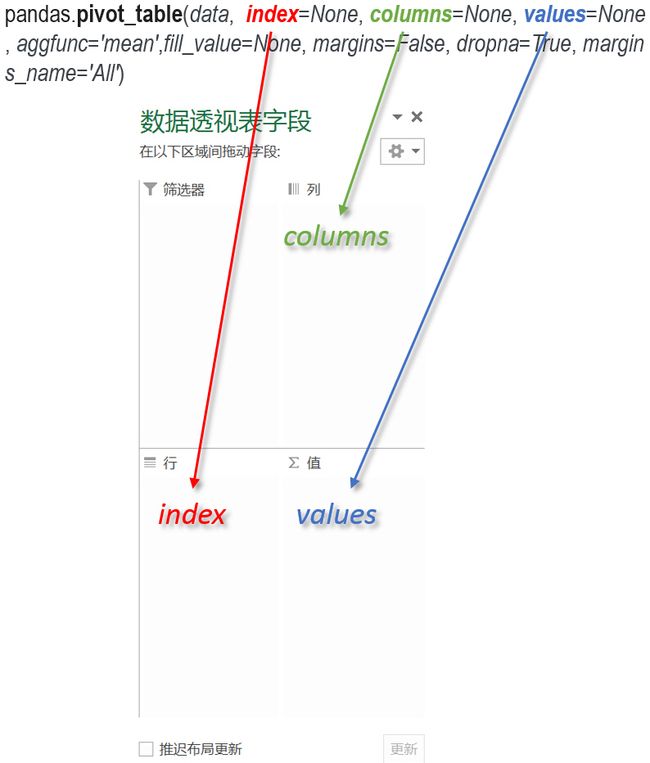
pandas.pivot_table函数中包含四个主要的变量,以及一些可选择使用的参数。四个主要的变量分别是数据源data,行索引index,列columns,和数值values。可选择使用的参数包括数值的汇总 方式,NaN值的处理方式,以及是否显示汇总行数据等。下面是Pandas官网给出的函数说明。

我们将pandas.pivot_table函数与Excel的数据透视表界面做了一个对比,并用不同的颜色和连线画出了两者之间的联系。在其中可以发现pandas.pivot_table的行索引index,列,和数值分别对 应了Excel数据透视表中的行,列和值三个部分。在实际的操作中Excel是将字段拖拽到相应的字段区间中,而在pandas.pivot_table中只需要将字段的的名称输入到等号后面就可以了。下面我们 来看下pandas.pivot_table具体的使用方法。
首先导入需要使用的numpy和pandas功能库,numpy用于数值计算,Pandas是基于numpy构建的用于科学计算的功能库,pandas.pivot_table是Pandas库(pd)中的函数。然后读取Lending Club数据 ,并生成名为lc的数据表。
|
1
2
3
|
import pandas as pd
import numpy as np
lc=pd.DataFrame(pd.read_csv('LoanStats3a.csv',header=1))
|
创建简单的数据透视表
我们选择Lending Club数据表中的贷款期限和贷款总额字段来创建一个简单的数据透视表。按贷款期限维度对贷款总额进行聚合,将贷款期限字段(term)放在行索引lndex中,贷款总额字段 (loan_amnt)放在值values中,生成按不同贷款期限维度聚合的贷款总额数据。这里需要说明的是在默认情况下pandas.pivot_table对指标的汇总方式是计算平均值。 因此下面的表中显示的是不 同贷款期限的贷款平均值数据。这个简单的数据透视表只有一个维度和一个指标。下面我们将为这个数据透视表增加更多的维度和指标,并增加更多的指标汇总计算方式。
|
1
|
pd.pivot_table(lc,index=["term"],values=["loan_amnt"])
|

增加一个行维度(index)
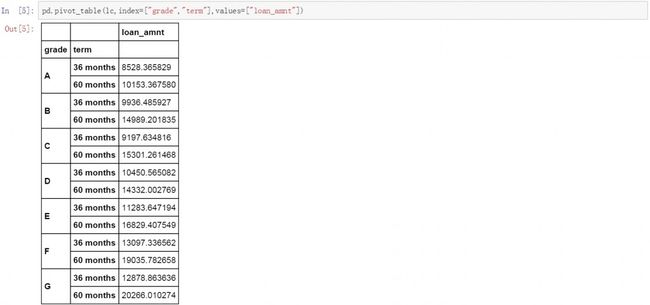
在贷款期限的维度上增加贷款用户等级维度,创建一个双维度的数据透视表,在pandas.pivot_table的行索引index中增加贷款用户等级字段(grade)。这样在行索引维度index中共包含了两个维 度,主维度贷款期限(term)和次级维度贷款用户等级(grade)。指标是按不同贷款期限下贷款用户等级分布进行汇总贷款金额平均值。与之前相比指标数据经过次级维度的细分变的更加精细。
|
1
|
pd.pivot_table(lc,index=["term","grade"],values=["loan_amnt"])
|

通过调整pandas.pivot_table函数中不同维度的位置可以更改数据透视表中维度的层级,以及数据的显示方式。这里我们将前面代码行索引中两个字段位置互换,此时贷款用户等级(grade)成了主维度,贷款期限(term)变成了次级维度。
|
1
|
pd.pivot_table(lc,index=["grade","term"],values=["loan_amnt"])
|
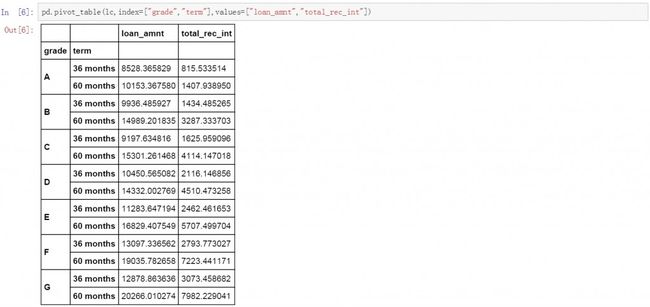
增加一个值变量(value)
除了增加次级维度以外,还可以增加需要汇总的数据值。在前面数据透视表的基础上我们增加总利息字段作为第二个汇总值。方法与前面增加次级维度很相似,将需要增加的字段放在值values中即可。下面是具体的代码和生成的数据透视表,其中total_rec_int是新增的值values变量。这里需要再次说明的是,默认情况下pandas.pivot_table按平均值对数据进行汇总。
|
1
|
pd.pivot_table(lc,index=["grade","term"],values=["loan_amnt","total_rec_int"])
|
更改数值汇总方式
若要更改pandas.pivot_table对值values的汇总方式需要在代码中进行设置,下面将贷款总额和总利息字段的汇总方式改为求和。方法是在代码中加入aggfunc=np.sum。新生成的数据透视表中值字段的计算方式就由之前的平均值改为了求和值。
|
1
|
pd.pivot_table(lc,index=["grade","term"],values["loan_amnt","total_rec_int"],aggfunc=np.sum)
|
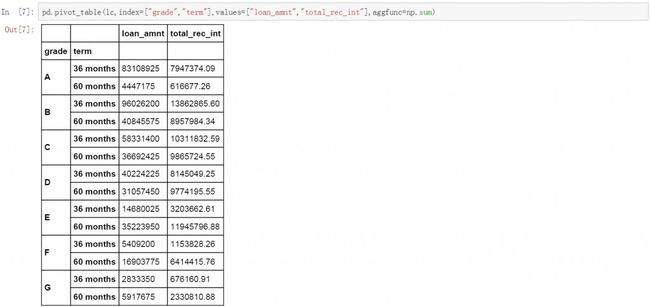
增加数值汇总方式
除了可以对值变量values计算平均值和求和以外,还可以进行计数。下面我们在上面数据透视表的基础上分别对贷款总额和总利息字段进行求和,平均值和技术的计算。具体方法是代码中增加以下内容aggfunc=[np.sum,np.mean,len]),aggfunc是汇总方式,np.sum表示求和,np.mean表示计算平均值,len表示计数。在下面新创建的数据透视表中可以看到,求和sum部分,平均值mean部
分和计数len部分的计算结果。
|
1
|
pd.pivot_table(lc,index=["grade","term"],values=["loan_amnt","total_rec_int"],aggfunc=[np.sum,np.mean,len])
|
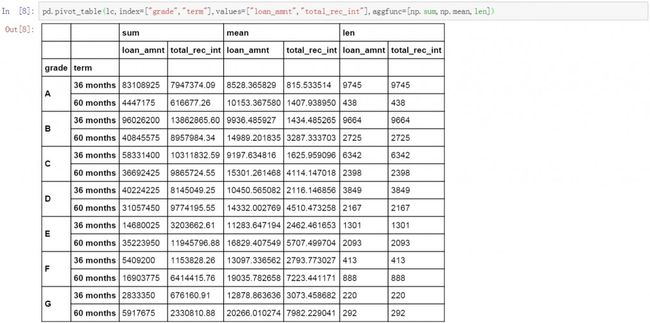
如果数据表中包含有NaN值,并且在之前的清洗中没有进行处理,也可以在生成数据透视表的过程中进行处理或替换。在pandas.pivot_table函数中有两种处理NaN值的方式,第一种是将NaN值替换为0。第二种为放弃NaN值,也就是说包含有NaN值的数据条目不参加计算。这里我们使用第一种方法,将NaN值替换为0。具体方法是在代码中添加以下部分fill_value=0。
|
1
|
pd.pivot_table(lc,index=["grade","term"],values=["loan_amnt","total_rec_int"],aggfunc=[np.sum,np.mean,len],fill_value=0)
|
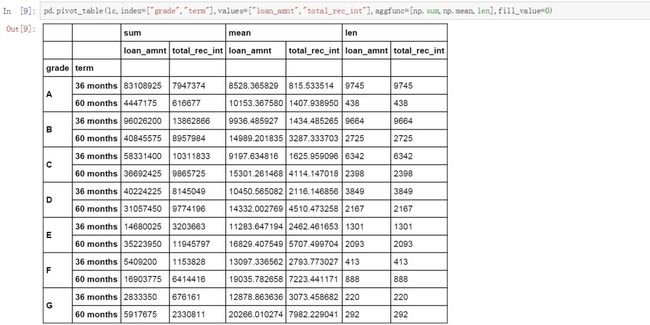
增加一个列维度(columns)
pandas.pivot_table函数也支持列维度。在Excel中需要将对应的字段拖到列区域中,在Pandas中的方法是增加列columns,并将对应的字段名称放在列columns变量的值中。下面是具体的代码,其中columns=[“home_ownership”]是新增加的部分,表示在数据表中增加列维度home_ownership。
|
1
|
pd.pivot_table(lc,index=["grade"],values=["loan_amnt"],columns=["home_ownership"],aggfunc=[np.sum],fill_value=0)
|
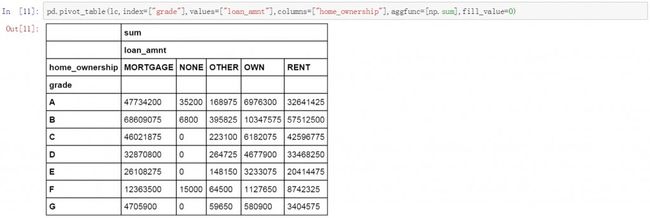
增加多个列维度
与行索引一样,列columns中也可以增加多个维度,方法与增加行维度和值一样,这里不再赘述。下面是具体的代码,其中columns=[“home_ownership”,”term”]是发生变化的部分,表示列中新增了贷款期限term维度。home_owership为主维度,term为次级维度。
|
1
|
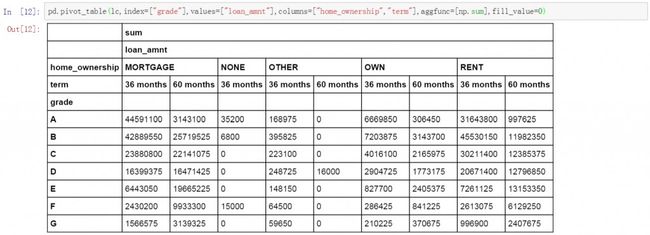
pd.pivot_table(lc,index=["grade"],values=["loan_amnt"],columns=["home_ownership","term"],aggfunc=[np.sum],fill_value=0)
|
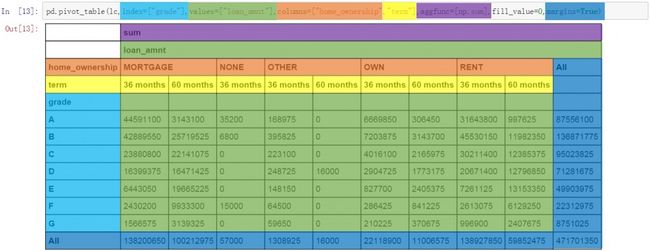
增加数据汇总值
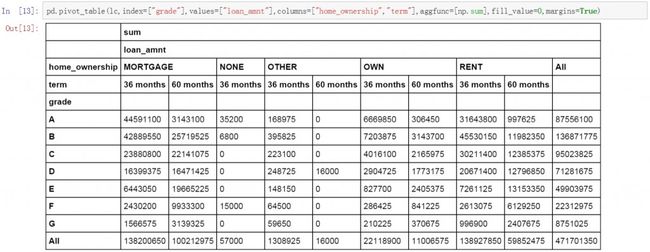
pandas.pivot_table函数中的margins参数用于增加数据透视表的汇总值。默认情况下margins的状态为False。需要增加透视表的汇总值时将margins值改为True即可。此时数据透视表将显示不同维度下数据的汇总值。汇总值的计算方式以aggfunc的一致。换句话说,如果aggfunc中设置的是求和,那么汇总值也是求和值。
|
1
|
pd.pivot_table(lc,index=["grade"],values=["loan_amnt"],columns=["home_ownership","term"],aggfunc=[np.sum],fill_value=0,margins=True)
|
最后,我们总结下pandas.pivot_table函数与数据透视表的对应关系。将每部分以不同颜色进行区分,index对应了数据透视表中行的索引部分(浅蓝色),values对应了数值的部分(绿色),columns对应了列的部分,(橙色表示主维度,黄色表示次级维度),aggfunc对应了数值的计算方式(紫色),并显示数据透视表的最顶部进行说明(sum)。Margins对应了数据透视表中值汇总的部分 (深蓝色)。