Python数据分析 | (31) 透视表和交叉表
目录
1. 透视表
2. 交叉表:crosstab
3. 总结
1. 透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的 数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上的分 组键将数据分配到各个矩形区域中。在Python和pandas中,可以通过本博客所 介绍的groupby功能以及(能够利用层次化索引的)重塑运算制作透视表。
DataFrame有一个pivot_table方法,此外还有一个顶级的pandas.pivot_table 函数。除能为groupby提供便利之外,pivot_table还可以添加分项小计,也叫 做margins。
回到小费数据集,假设我想要根据day和smoker计算分组平均数 (pivot_table的默认聚合类型),并将day和smoker放到行上:
tips = pd.read_csv('examples/tips.csv')
# Add tip percentage of total bill
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips[:6]
tips.pivot_table(index=['day', 'smoker']) #默认每组执行mean聚合运算
可以用groupby直接来做。现在,假设我们只想聚合tip_pct和size,而且想根 据time进行分组。我将smoker放到列上,把day放到行上:
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],
columns='smoker')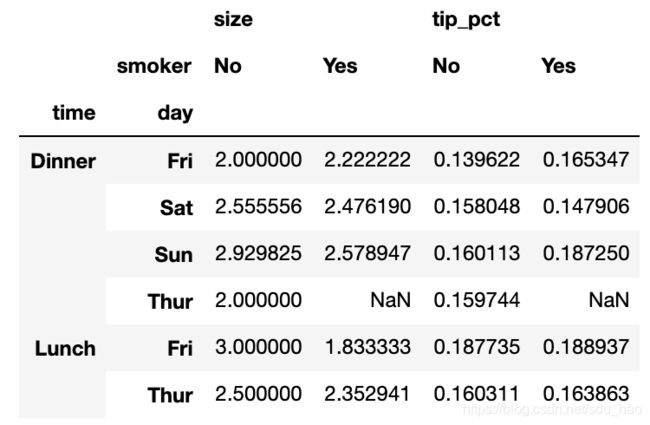
还可以对这个表作进一步的处理,传入margins=True添加分项小计。这将会 添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计:
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],
columns='smoker', margins=True)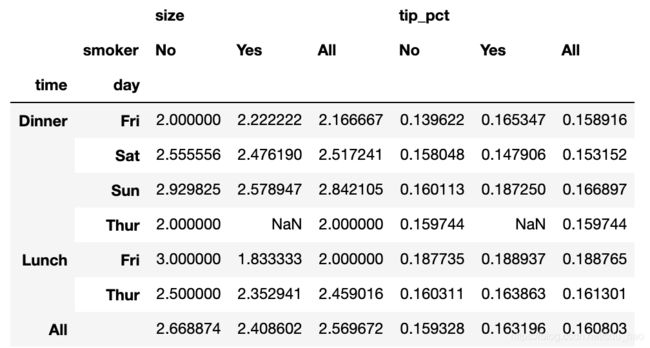
这里,All值为平均数:不单独考虑烟民与非烟民(All列),不单独考虑行分 组两个级别中的任何单项(All行)。
要使用其他的聚合函数,将其传给aggfunc即可。例如,使用count或len可以 得到有关分组大小的交叉表(计数或频率):
tips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day',
aggfunc=len, margins=True)
如果存在空的组合(也就是NA),你可能会希望设置一个fill_value:
tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],
columns='day', aggfunc='mean', fill_value=0)
pivot_table的参数说明请参见下表:
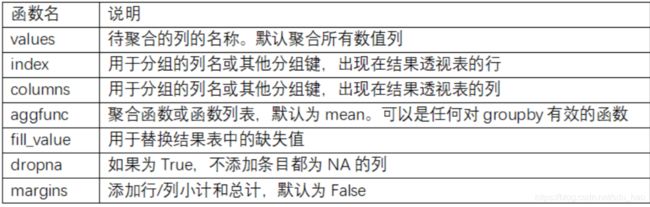
2. 交叉表:crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。看下面的例子:
from io import StringIO
data = """\
Sample Nationality Handedness
1 USA Right-handed
2 Japan Left-handed
3 USA Right-handed
4 Japan Right-handed
5 Japan Left-handed
6 Japan Right-handed
7 USA Right-handed
8 USA Left-handed
9 Japan Right-handed
10 USA Right-handed"""
data = pd.read_table(StringIO(data), sep='\s+')
data
作为调查分析的一部分,我们可能想要根据国籍和用手习惯对这段数据进行 统计汇总。虽然可以用pivot_table实现该功能,但是pandas.crosstab函数会 更方便:
pd.crosstab(data.Nationality, data.Handedness, margins=True)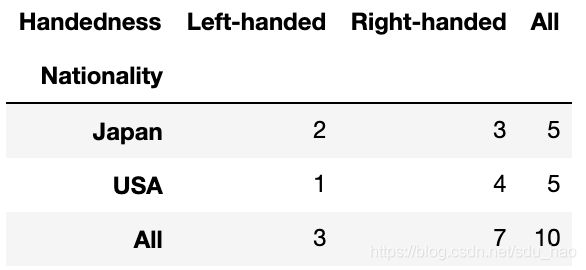
crosstab的前两个参数可以是数组或Series,或是数组列表。就像小费数 据:
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)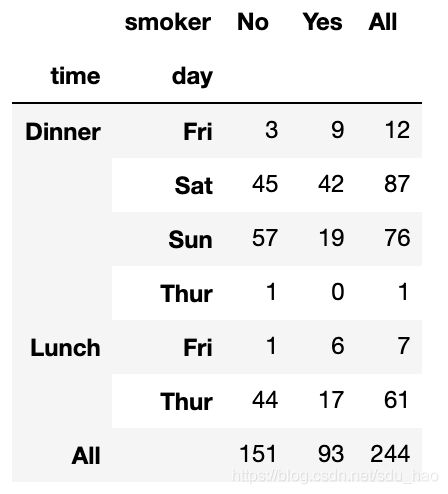
3. 总结
最近几篇博客我们介绍了pandas数据分组工具,它既有助于数据清理,也有助于建模或统计分析工作。之后,我们会学习几个例子,对真实数据使用groupby。后续的几篇博客我们会关注时间序列数据。