week4 day1初识模块
week4 day1初识模块
-
- 一. 模块介绍
- 1.1 什么是模块?
- 1.2 为何要使用模块?
- 二. 模块的使用
- 2.1 import
- 2.2 from...import...
- 三. 循环导入问题
- 四. 模块的搜索路径和优先级
- 五. 文件目录开发规范
一. 模块介绍
1.1 什么是模块?
模块是功能的集合体。可以放在文件中,也可以放在文件夹中。
模块大致分为四种:
| 模块分类 | 掌握程度 |
|---|---|
| 一个py文件就是一个模块,文件名叫test.py,模块名叫test。 | 重点掌握 |
| 在python2解释器中,包含__init__.py的文件夹称之为包,包也是模块。 | 重点掌握 |
| 使用c编写的并连接到python解释器的内置模块。 | 会用即可 |
| 已被编译成共享库或DDL的c或c++扩展 | 会用即可 |
模块的三种来源:
- 自带的模块
- 第三方模块:pip3 install requests
- 自定义模块
1.2 为何要使用模块?
- (自带的,第三方模块)拿来主义,提高开发效率
- 自定义代码是为了解决代码冗余问题
二. 模块的使用
执行文件只有一个,而模块文件是在文件被执行前提前写好导入要执行的文件中,导入文件的方法有两种。而我们之前知道,执行python文件会开辟名称空间,将文件中定义的名称放到名称空间里面。
导入模块的规范:
通常情况下所有的导入语句都应该写在文件开头,然后分为三部分:
第一部分:先导入自带的模块
第二部分:导入第三方模块
第三部分:导自定义的模块
import time
import 第三方模块
import spam
如果第三方库或者自定义模块的名字过长,可以给模块重新命名,方便调用。
import ifuruiegbirugberu as i
i.不啦不啦
2.1 import
通过import首次导入模块会发生的事情:
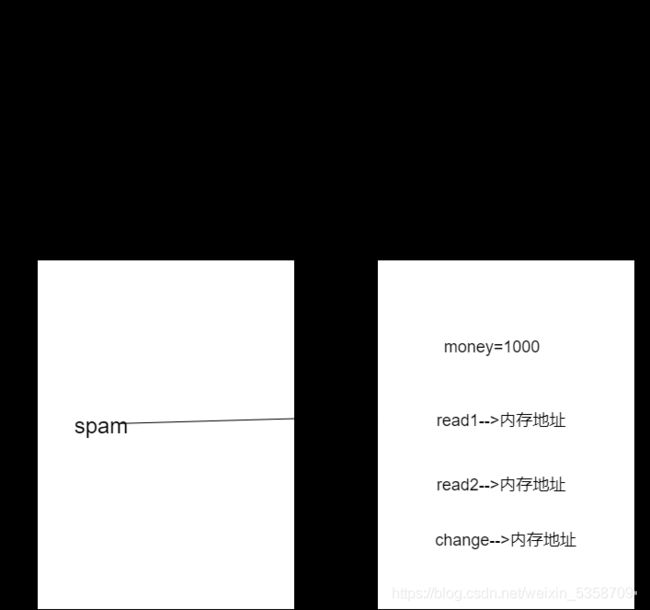
1.运行被导入模块的文件,创建一个模块的名称空间,将模块文件运行过程中产生的名字都丢到模块的名称空间中(下面有生成模块名称空间的示意图)。
2.在当前名称空间(执行文件)中得到一个模块的名字,该名字是指向魔魁啊的名称空间。
import spam
只有首次导入时会产生名称空间,后续调入时只会重复访问第一次调用时产生的名称空间。
2.2 from…import…
通过from import首次导入模块发生的事情:
1.运行模块文件,创建新的名称空间,将该模块对应的名字都添加到新的名称空间中。
2.在当前名称空间中得到一个import后面的变量名称/函数名称,该名称指向模块的名称空间中的对应的名称。
from spam import money
from spam import read1
from spam import read2
from spam import change
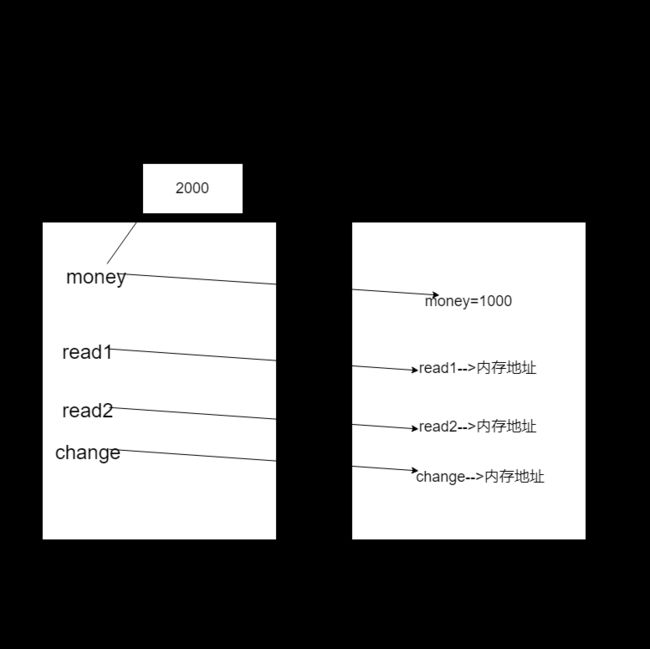
通过这种方式导入模块中的变量或者函数时,在执行主文件的时候需要注意这个名称是来自哪里(模块/主文件),再回到那个位置查看定义阶段是如何定义的,找作用域关系确定最后的值。
三. 循环导入问题
即两个模块文件相互导入彼此。尽量不要出现这种情况!!!如果实在出现了这种情况,有一种解决思想:把调用模块的语句放在最后执行,先在各自创建的名称空间里面添加完所有的名称,再运行导入模块那句话。
run.py:
print('from run.py')
import m1
m1.f1() # 在调用m1里面的函数之前,所有名称已经存放好了。再互相导模块就不会出现名称不存在的情况了
m1.py:
def f1():
from m2 import y
x=111
m2.py:
def f2():
from m1 import x
y=222
四. 模块的搜索路径和优先级
当主文件调用一个模块的时候,是按照这样的顺序搜索模块的:
- 搜索内存中的(如果模块第一次导入后,文件执行结束前在内存中存在模块的名称空间)
- 在内置的模块中搜索
- 在sys.path的目录中挨个搜索模块的名字的py文件
import sys
print(sys.path)----->['E:\\pycharm\\notes and homework\\w4 1.4', 'E:\\pycharm\\notes and homework', 'E:\\pycharm\\PyCharm 2020.1.2\\plugins\\python\\helpers\\pycharm_display'...]
会得到一个列表,列表的第一个文件路径是当前执行文件的文件夹路径,第二个文件路径是当前执行文件所在的项目文件夹目录的路径,后面都是pycharm内置的存放路径。
如果想导入的模块不在内存,内置以及环境变量(sys.path)下,两种导入方法(eg m1在aaa文件夹下):
方法一:
import aaa.m1 # .在导入语句中,是子文件夹的意思,在调用语句中,是内置变量/函数的意思
aaa.m1.f1()
方法二:
import sys
sys.path.append(r'文件路径')
导入的第三方库或者自定义模块不应与内置模块名字发生冲突。
五. 文件目录开发规范
我们之前学过的书写代码是把所有的代码写到一个文件里面,这样写会使修改文件变得非常的麻烦。程序设计者写完代码后,将文件发送给使用者,使用者使用错误中出错也会很难做出修改,使用者的使用也非常麻烦。因此,我们需要使用更清晰合理的结构来整理我们写好的“面条型”代码。这也就是软件目录开发的规范。
如下图所示,如果我们需要将不同功能的代码块放到不同的文件里面,方便我们的使用和管理。
| 文件夹名 | 文件夹里面的文件 | 文件的功能 |
|---|---|---|
| bin | start.py | 运行程序的代码,唯一的执行文件,eg run() |
| core | src.py | 程序的逻辑代码,即主体代码,eg atm项目中各项功能的定义 |
| conf | settings.py | 主体文件中的配置内容,eg atm项目中日志的格式和程序根目录 |
| db | db_handler.py | 里面存放对于数据的操作,读和写 |
| lib | common | 存放创建日志的方法 |
| log | access.log | 存放写入的日志信息 |
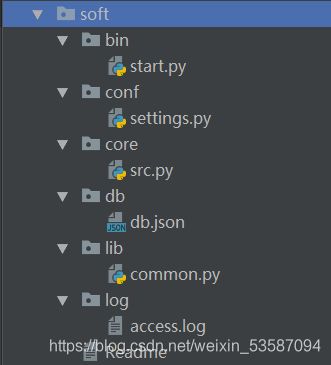
这样设置目录完,我们将原本在“面条型”代码里面的看起来有些乱的代码都拆分到了各个文件里面,但这些文件是彼此独立的,因此我们需要一根线,把所有文件串到一起。线 就是执行文件start.py,而线就是我们的start.py文件。把其他的文件都当作模块导入。
先导入内置模块sys和os。sys模块下的path方法是参照执行文件的环境变量进行配置,所以要拿到当前(执行)文件的根目录,从根目录的不同文件中获得被拆开的代码文件。需要BASE_DIR=os.path.dirname(os.path.dirname(__file__))拿到文件的根目录,然后把根目录添加到环境变量中。(这里使用了两次获取文件路径是因为当前start.py的父级是bin,bin的父级是ATM,也就是程序根文件夹)sys.path.append(BASE_DIR),这样就可以从其他文件夹中导入其他文件来使用。
例如:
from core import src
from conf import settings
from db import db_handler
from lib import common